Introdução ao Machine Learning
Machine Learning (ML), ou Aprendizado de Máquina, é uma subárea da Inteligência Artificial dedicada ao estudo de sistemas capazes de melhorar seu desempenho em uma tarefa a partir da experiência. Ou seja, em vez de programarmos explicitamente todas as regras de decisão, fornecemos dados, objetivos e métricas para que o algoritmo encontre padrões, regularidades ou estratégias de ação.
Segundo a formulação mais clásica de Mitchell (1997), um sistema pode ser considerado como “capaz de aprender” quando seu desempenho em uma tarefa melhora com a experiência disponível a ele. Na literatura contemporânea, Mohri, Rostamizadeh e Talwalkar (2018) apliam essa discussão dos algoritmos para além da questão de “serem capazes ou não de aprender”, buscando compreender por que eles generalizam para dados ainda não observados. Essa perspectiva de análise é interessante pois coloca os profissionais de TI para discutir conceitos como generalização, erro de treinamento, erro de teste, viés, variância e complexidade do modelo.
Ameet Joshi (2022) enfatiza a integração entre teoria e aplicação. Para ele, a área deve ser compreendida tanto pelos seus fundamentos conceituais quanto pelo seu uso prático em problemas reais, como classificação, previsão, reconhecimento de padrões e tomada de decisão. Isso significa dizer que aprender os algoritmos de machine learning não se limita apenas a “rodar uma biblioteca”, mas compreender como os dados representam um problema, como o algoritmo aprende e quais limites existem nessa aprendizagem.
Grandes áreas de ML
De forma didática, podemos dividir machine learning em três grandes áreas de estudo: 1) Aprendizado supervisionado; 2) Aprendizado não supervisionado; e 3) Aprendizado por reforço. Essa divisão não esgota todas as possibilidades de pesquisa e estudo em ML, mas organiza bem os primeiros estudos para quem está começando a conhecer o assunto.
Aprendizado supervisionado
O aprendizado supervisionado ocorre quando o algoritmo aprende a partir de exemplos rotulados. Isso significa que cada instância do conjunto de dados possui atributos de entrada, geralmente chamados de X, e uma resposta esperada, chamada de y.
Podemos dividir as técncas supervisionadas em dois tipos: classificação e regressão. Na classificação, a saída é uma categoria, como “spam” ou “não spam”, “aprovado” ou “reprovado”, “alto”, “médio” ou “baixo”. Na regressão, a saída é um valor numérico contínuo, como o preço de um imóvel, a temperatura prevista ou a demanda futura de um produto. Em ambos os casos, o modelo aprende a partir de exemplos históricos.
Os métodos de aprendizado supervisionado mais comuns são:
- Regressão linear
- Regressão logística
- K-vizinhos mais próximos
- Naive Bayes
- Árvores de decisão
- Florestas aleatórias
- Máquinas de vetores de suporte (SVM)
- Redes neurais
A biblioteca scikit-learn possui métodos implementados em forma de módulos que aplicam as ideias destes algoritmos e que podem ser usados em nossos próprios códigos (Scikit-learn, 2026). Para ler mais sobre o funcionamento dos algoritmos de aprendizado supervisionado, clique aqui.
Aprendizado não supervisionado
O aprendizado não supervisionado ocorre quando os dados não possuem rótulos previamente conhecidos, ou seja, o algoritmo precisa encontrar estruturas internas nos dados. Autores como Bishop (2006) destacam que esse tipo de abordagem é essencial para descobrir padrões latentes em conjuntos de dados complexos.
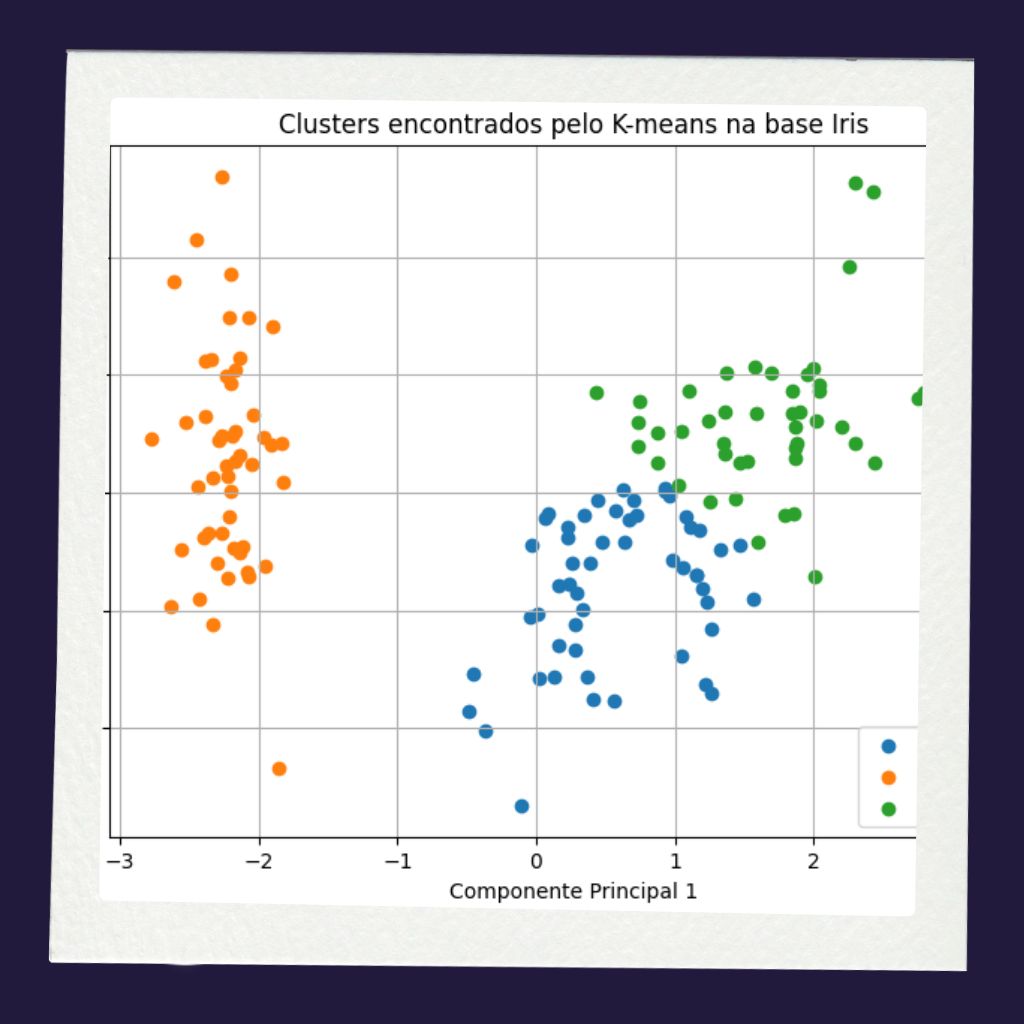
Um exemplo clássico é a técnica de agrupamento (do inglês clustering), em que o modelo tenta separar os dados em grupos semelhantes. Em uma base de clientes, por exemplo, um algoritmo pode encontrar grupos de consumidores com comportamentos parecidos, mesmo sem que alguém tenha informado previamente quais grupos existem.
Os métodos de aprendizado não supervisionado mais comuns são:
- K-means
- Agrupamento hierárquico
- DBSCAN
- PCA
- Métodos de associação
A biblioteca scikit-learn também possui métodos implementados em forma de módulos que aplicam as ideias destes algoritmos e que podem ser usados em nossos próprios códigos (Scikit-learn, 2026). Para ler mais sobre o funcionamento dos algoritmos de aprendizado não supervisionado, clique aqui.
Aprendizado por reforço
O aprendizado por reforço é diferente dos dois anteriores porque envolve um agente que interage com um ambiente. O agente executa ações, recebe recompensas ou punições e aprende uma política de comportamento para maximizar a recompensa acumulada ao longo do tempo.
Sutton e Barto (2018) explicam que o aprendizado por reforço é especialmente adequado para problemas sequenciais, nos quais uma decisão atual afeta estados e recompensas futuras. Exemplos incluem jogos, robótica, navegação autônoma e sistemas de recomendação adaptativos.
Os métodos de aprendizado por reforço mais comuns são:
- Métodos de programação dinâmica
- Monte Carlo
- SARSA
- Q-learning
- Deep Q-Networks
- Métodos de gradiente de política
Em cursos introdutórios, o Q-learning e o SARSA costumam ser os mais didáticos porque mostram claramente a lógica de estados, ações, recompensas e atualização de valor.
A biblioteca scikit-learn também possui métodos implementados em forma de módulos que aplicam as ideias destes algoritmos e que podem ser usados em nossos próprios códigos (Scikit-learn, 2026). Para ler mais sobre o funcionamento dos algoritmos de aprendizado por reforço, clique aqui.
Conclusão
A etapa inicial para se trabalhar com Machine Learning é compreender o problema, analisar os dados, identificar as variáveis, tratar as inconsistências e preparar a base para que o modelo possa aprender de forma adequada.
Dentro dessa linha de estudo, temos as técnicas e algoritmos de aprendizado supervisionado, não supervisionado e por reforço. Elas representam três formas distintas de aprendizagem computacional, mas todas dependem de uma boa representação do problema.
A diferença entre essas três áreas pode ser resumida da seguinte maneira:
- no aprendizado supervisionado, o algoritmo aprende com respostas conhecidas;
- no aprendizado não supervisionado, o algoritmo aprende padrões sem respostas previamente definidas;
- no aprendizado por reforço, o algoritmo aprende por tentativa, erro e recompensa.
Essa distinção é simples do ponto de vista conceitual, mas tecnicamente profunda, pois cada área vai exigir formas diferentes de representar dados, avaliar resultados e lidar com incerteza. É necessário compreender o que os dados representam, que tipo de problema está sendo resolvido, quais hipóteses o algoritmo assume e quais decisões humanas foram tomadas durante o pré-processamento.
Obrigado pela leitura e bons estudos!
Referências
BISHOP, Christopher M. Pattern Recognition and Machine Learning. New York: Springer, 2006.
JOSHI, Ameet V. Machine Learning and Artificial Intelligence. 2. ed. Cham: Springer, 2022.
MITCHELL, Tom M. Machine Learning. New York: McGraw-Hill, 1997.
MOHRI, Mehryar; ROSTAMIZADEH, Afshin; TALWALKAR, Ameet. Foundations of Machine Learning. 2. ed. Cambridge: MIT Press, 2018.
SCIKIT-LEARN. User Guide. 2026. Disponível em: <https://scikit-learn.org/stable/user_guide.html>. Acesso em: 5 mai. 2026.
SUTTON, Richard S.; BARTO, Andrew G. Reinforcement Learning: An Introduction. 2. ed. Cambridge: MIT Press, 2018.