Introdução aos testes de hipóteses
O teste de hipóteses é um procedimento estatístico usado para avaliar se uma afirmação sobre uma população é compatível com os dados observados em uma amostra. Em termos práticos, ele ajuda o pesquisador a decidir se uma diferença, uma melhoria, uma associação ou um efeito observado nos dados pode ser tratado como evidência estatística ou se pode ter ocorrido apenas por variação aleatória.
Na Estatística, raramente temos acesso a todos os elementos de uma população. Em pesquisas científicas, sistemas computacionais, experimentos de usabilidade, testes A/B, avaliação de algoritmos ou análise de desempenho de software, normalmente trabalhamos com amostras. O teste de hipóteses surge exatamente no contexto em que precisamos tomar decisões racionais sob incerteza, considerando que os dados amostrais podem variar de uma coleta para outra (Bussab; Morettin, 2017).
Breve contexto histórico
Historicamente, os fundamentos dos testes de hipóteses foram consolidados principalmente no início do século XX. William Sealy Gosset, conhecido pelo pseudônimo Student, propôs a distribuição t como ferramenta para lidar com amostras pequenas em problemas industriais, especialmente no controle de qualidade da cervejaria Guinness (Student, 1908). Ronald A. Fisher (1925) desenvolveu a ideia de significância estatística e popularizou o uso do valor-p (ou p-value) como medida de evidência contra uma hipótese inicial. Posteriormente, Jerzy Neyman e Egon Pearson (1933) formalizaram uma abordagem decisória baseada em hipótese nula, hipótese alternativa, erro tipo I, erro tipo II e poder do teste.
Essas contribuições moldaram a prática científica moderna. O teste de hipóteses tornou-se uma ferramenta essencial para avaliar resultados em áreas como Medicina, Engenharia, Economia, Psicologia, Computação e Ciência de Dados. Em Computação, por exemplo, ele pode ser usado para verificar se uma nova versão de um sistema reduziu o tempo médio de resposta, se um algoritmo de classificação superou outro em acurácia, se uma mudança na interface aumentou a taxa de conversão ou se um novo mecanismo de cache diminuiu a latência média das requisições.
A importância do teste de hipóteses está no fato de que ele evita conclusões baseadas apenas na aparência dos números. Uma diferença entre duas médias pode parecer grande, mas talvez seja explicada pelo acaso. Uma melhoria de 2% na acurácia de um modelo pode parecer pequena, mas talvez seja estatisticamente consistente. Portanto, o teste de hipóteses oferece um método formal para avaliar essas situações, conectando dados, probabilidade e decisão científica (Montgomery; Runger, 2018).
O que é uma hipótese?
Em sentido amplo, uma hipótese é uma afirmação provisória que pode ser investigada por meio de evidências. Na pesquisa científica, uma hipótese expressa uma suposição sobre determinado fenômeno. Em Estatística, essa ideia é formalizada como uma afirmação sobre uma população, um parâmetro ou uma distribuição de probabilidade.
Um parâmetro é uma característica numérica da população, como a média, a proporção, a variância ou a diferença entre médias. Quando dizemos que o tempo médio de resposta de uma API é de 200 milissegundos, estamos fazendo uma afirmação sobre uma média populacional. Quando afirmamos que 70% dos usuários preferem uma nova interface, estamos falando de uma proporção populacional.
O teste de hipóteses normalmente parte de duas afirmações concorrentes: a hipótese nula e a hipótese alternativa. Conforme Casella e Berger (2002), a hipótese nula, representada por H₀, é a afirmação inicial que será colocada à prova. Ela costuma expressar ausência de efeito, ausência de diferença ou manutenção de uma condição conhecida. A hipótese alternativa, representada por H₁ ou Ha, expressa aquilo que o pesquisador deseja investigar como possibilidade: existência de diferença, melhoria, redução, aumento ou associação.
Por exemplo, imagine uma equipe de desenvolvimento que afirma ter otimizado uma API. Antes da mudança, o tempo médio de resposta era de 500 milissegundos. Após a otimização, a equipe coleta uma amostra de requisições e deseja verificar se houve redução real no tempo médio. Nesse caso, as hipóteses poderiam ser formuladas assim:
- H₀: o tempo médio de resposta continua sendo 500 ms ou mais.
- H₁: o tempo médio de resposta ficou menor que 500 ms.
Esse é um exemplo de teste unilateral à esquerda, porque o interesse está em verificar redução. O pesquisador não está apenas perguntando se houve alguma diferença; ele está perguntando se houve melhoria em uma direção específica.
Em outro exemplo, uma equipe de Ciência de Dados compara dois algoritmos de recomendação. O algoritmo A apresenta acurácia média de 82% em experimentos anteriores. Um novo algoritmo B é proposto. O objetivo é verificar se o novo algoritmo possui desempenho diferente. As hipóteses poderiam ser:
- H₀: a acurácia média do algoritmo B é igual à acurácia média do algoritmo A.
- H₁: a acurácia média do algoritmo B é diferente da acurácia média do algoritmo A.
Esse é um teste bilateral, pois qualquer diferença interessa para mostrar que o novo algoritmo é melhor ou pior.
É importante observar que o teste de hipóteses não prova verdades absolutas. Ele avalia evidências amostrais sob um modelo probabilístico. Por isso, a linguagem estatística costuma falar em “rejeitar” ou “não rejeitar” a hipótese nula, e não em “provar” definitivamente uma hipótese. Essa distinção é importante, pois a inferência estatística trabalha com incerteza, amostragem e probabilidade (Moore; McCabe; Craig, 2017).
Nível de significância estatística
O nível de significância, geralmente representado pela letra grega alfa (), é um limite definido pelo pesquisador antes da realização do teste de hipóteses. Ele indica a tolerância máxima ao chamado erro tipo I, isto é, ao risco de rejeitar a hipótese nula quando ela é verdadeira. Segundo Bussab e Morettin (2017), alfa () representa o nível de risco que o pesquisador aceita correr ao concluir que existe uma diferença, redução, aumento ou efeito estatístico quando, na realidade, esse efeito pode não existir na população.
Os valores mais comuns para o nível de significância são:
- Nível de significância de 10%
- Nível de significância de 5%
- Nível de significância de 1%
Quando se adota (), por exemplo, o pesquisador está aceitando uma tolerância de 5% para cometer erro tipo I. Isso não significa que há 5% de probabilidade de a hipótese nula ser verdadeira. Significa que, dentro do procedimento estatístico adotado, aceita-se um risco de 5% de rejeitar () em situações nas quais () seria verdadeira.
A comparação entre o valor-p e o nível de significância é o critério mais usado para tomar a decisão estatística. O valor-p mede o grau de compatibilidade do resultado observado com a hipótese nula. Se o valor-p for pequeno, isso indica que seria pouco provável observar um resultado tão extremo quanto o obtido caso () fosse verdadeira. Por isso, valores-p pequenos fornecem evidência contra a hipótese nula (Fisher, 1925).
A regra de decisão pode ser escrita assim:
Isso mostra que a conclusão de um teste de hipóteses depende do nível de significância escolhido. Quanto menor o valor de (), mais rigoroso é o teste e mais forte precisa ser a evidência amostral para rejeitar ().
Portanto, o nível de significância funciona como uma régua de decisão. O valor-p mostra a força da evidência contra a hipótese nula, enquanto () define o ponto de corte usado para decidir se essa evidência será considerada suficiente. Em pesquisas científicas e em experimentos computacionais, essa escolha deve ser feita antes da análise dos dados, pois escolher () depois de observar o valor-p pode favorecer interpretações enviesadas.
Erros tipo I e II
Em testes de hipóteses, a decisão estatística sempre envolve algum grau de incerteza. Como pesquisadores costumam trabalhar com amostras, e não com a população inteira, existe a possibilidade de tomar uma decisão incorreta. Essa possibilidade é organizada em dois conceitos fundamentais: erro tipo I e erro tipo II. Esses erros foram formalizados na abordagem clássica de Neyman e Pearson (1933), que tratou o teste de hipóteses como um procedimento de decisão sujeito a riscos controláveis.
O erro tipo I ocorre quando rejeitamos a hipótese nula mesmo ela sendo verdadeira. Em outras palavras, concluímos que existe uma diferença, uma redução, um aumento ou um efeito estatístico quando, na realidade, esse efeito não existe na população. Esse erro está diretamente associado ao nível de significância do teste, representado por alfa ( ). Por isso, quando adotamos , estamos aceitando uma tolerância de 5% para cometer erro tipo I ao longo do procedimento estatístico (Bussab; Morettin, 2017).
Em notação matemática, o erro tipo I pode ser representado assim:
A probabilidade de cometer erro tipo I é:
O erro tipo II ocorre na situação inversa: não rejeitamos a hipótese nula quando ela é falsa. Nesse caso, existe uma diferença, redução, aumento ou efeito real na população, mas o teste não consegue detectar evidência estatística suficiente a partir da amostra analisada. A probabilidade de cometer erro tipo II é geralmente representada por beta ( ) (Montgomery; Runger, 2018).
Em notação matemática:
A probabilidade de cometer erro tipo II é:
Esses dois erros podem ser compreendidos por meio de uma matriz de decisão:
| Situação real | Decisão do teste | Resultado |
|---|---|---|
| () é verdadeira | Não rejeitar () | Decisão correta |
| () é verdadeira | Rejeitar () | Erro tipo I |
| () é falsa | Rejeitar () | Decisão correta |
| () é falsa | Não rejeitar () | Erro tipo II |
A relação entre esses erros exige cuidado. Reduzir muito o nível de significância diminui a probabilidade de erro tipo I, mas pode aumentar a probabilidade de erro tipo II. Por exemplo, se o pesquisador adotar , ela será mais rigorosa para rejeitar (). Isso reduz o risco de concluir falsamente que houve melhoria. Porém, também pode tornar o teste menos sensível para detectar uma melhoria real, principalmente se a amostra for pequena ou se os dados tiverem grande variabilidade.
Poder do teste
O complemento do erro tipo II é chamado de poder do teste. O poder representa a probabilidade de rejeitar () quando ela realmente é falsa. Em termos práticos, é a capacidade do teste de detectar um efeito real. Matematicamente, expressamos o poder do teste assim:
De acordo com Montgomery e Runger (2018), o poder do teste tende a aumentar quando o tamanho da amostra cresce, quando a variabilidade dos dados diminui ou quando o efeito real é maior.
Tipos de testes
Os testes de hipóteses podem ser classificados de diferentes formas. Uma primeira distinção envolve o tipo de parâmetro analisado. Existem testes para médias, proporções, variâncias, diferenças entre médias, diferenças entre proporções, associação entre variáveis categóricas e comparação entre múltiplos grupos.
Os testes para médias são usados quando o pesquisador deseja avaliar uma variável quantitativa, como tempo de execução, consumo de memória, latência, nota média de usuários, número médio de acessos ou tempo médio para concluir uma tarefa. Quando a variância populacional é conhecida, pode-se usar o teste z para média. Na prática, como a variância populacional geralmente não é conhecida, o teste t é mais comum, principalmente quando a amostra é pequena ou moderada (Student, 1908; Devore, 2018).
O teste para uma proporção é adequado quando a variável de interesse é categórica e o resultado pode ser resumido como sucesso ou fracasso. Em Computação, isso aparece em situações como proporção de usuários que clicaram em um botão, proporção de testes automatizados aprovados, proporção de classificações corretas, proporção de clientes que abandonaram o carrinho ou proporção de requisições com erro.
Quando o objetivo é comparar duas médias, pode-se usar o teste t para duas amostras. Ele é útil quando se deseja comparar, por exemplo, o tempo médio de resposta de dois servidores, o desempenho médio de dois algoritmos ou o tempo médio de conclusão de tarefa em duas versões de interface. Se as observações forem pareadas, como antes e depois da mesma aplicação em um mesmo conjunto de casos, usa-se o teste t pareado. Aplicamos essa distinção porque dados independentes e dados pareados exigem modelos estatísticos diferentes (Montgomery; Runger, 2018).
Também existem testes para comparação de proporções. Eles são aplicados quando se deseja saber se duas taxas diferem estatisticamente. Em um teste A/B, por exemplo, uma equipe pode comparar a proporção de usuários que clicaram em “Assinar” na versão antiga e na versão nova de uma página. Se a versão A teve 8% de conversão e a versão B teve 10%, o teste ajuda a avaliar se essa diferença pode ser atribuída à alteração da interface ou se pode ser apenas flutuação amostral.
Para analisar associação entre variáveis categóricas, um teste muito usado é o qui-quadrado. Ele pode responder perguntas como: “o tipo de dispositivo usado pelo usuário está associado à taxa de abandono?”, “a categoria do erro está associada ao módulo do sistema?” ou “o perfil do usuário está associado à preferência por determinada funcionalidade?”. Segundo Agresti (2013), o teste qui-quadrado é especialmente importante em pesquisas com tabelas de contingência.
Quando existem mais de dois grupos, a análise de variância, conhecida como ANOVA, é uma técnica clássica. Ela permite avaliar se há diferença estatisticamente significativa entre três ou mais médias. Em Computação, poderia ser usada para comparar o tempo médio de execução de três algoritmos de ordenação, três configurações de infraestrutura ou três versões de uma interface (Montgomery; Runger, 2018).
Além dessa classificação por objetivo, os testes também podem ser paramétricos ou não paramétricos. Testes paramétricos assumem condições específicas sobre os dados, como normalidade aproximada, independência das observações ou homogeneidade de variâncias. Testes não paramétricos são alternativas úteis quando essas suposições não são razoáveis, principalmente em dados assimétricos, ordinais ou com muitos valores extremos. Exemplos comuns são os testes de Mann-Whitney, Wilcoxon e Kruskal-Wallis (Siegel; Castellan, 1988).
A escolha do teste depende de quatro perguntas práticas:
- Qual é o tipo de variável analisada?
- Quantos grupos estão sendo comparados?
- As amostras são independentes ou pareadas?
- Quais suposições estatísticas parecem aceitáveis?
Uma escolha inadequada pode levar a conclusões frágeis, mesmo quando os cálculos foram executados corretamente.
Como obter o valor-p?
O valor-p é um dos conceitos centrais dos testes de hipóteses. Sua interpretação depende diretamente da distribuição de probabilidade da estatística de teste utilizada. Em termos gerais, o valor-p representa a probabilidade de observar um resultado tão extremo quanto o obtido na amostra, ou ainda mais extremo, assumindo que a hipótese nula seja verdadeira.
Para calcularmos o valor-p, o primeiro passo consiste em formular as hipóteses estatísticas. Para um teste sobre a média populacional, por exemplo, podemos ter um cenário bilateral:
ou, cenários unilaterais,
Após definir as hipóteses, calcula-se uma estatística de teste que mede o afastamento entre o valor observado na amostra e o valor assumido pela hipótese nula.
Quando a variância populacional é conhecida, utiliza-se frequentemente a estatística z:
em que:
- é a média amostral,
- é a média especificada pela hipótese nula,
- é o desvio padrão populacional,
- é o tamanho da amostra.
Quando a variância populacional é desconhecida, substitui-se pelo desvio padrão amostral e utiliza-se a distribuição t de Student, com graus de liberdade:
O denominador dessas expressões é chamado de erro padrão da média. Esse erro pode ocorrer quando temos a variância populacional:
ou, quando a variância populacional é desconhecida,
Seja como for, o erro padrão mede a variabilidade esperada da média amostral. Quanto maior a amostra, menor tende a ser o erro padrão e mais precisa será a estimativa da média populacional.
Depois de calcular a estatística de teste, determina-se a probabilidade associada a ela na distribuição teórica correspondente. Essa probabilidade é justamente o valor-p.
Para um teste unilateral à esquerda, o valor-p é dado por uma das equações abaixo, dependendo da distribuição utilizada:
Para um teste unilateral à direita, temos:
Já para um teste bilateral, considera-se a probabilidade nas duas caudas da distribuição:
Do ponto de vista geométrico, o valor-p corresponde à área sob a curva da distribuição de probabilidade localizada além da estatística observada, na direção indicada pela hipótese alternativa. Essa interpretação conecta diretamente os conceitos de distribuição amostral, estatística de teste e tomada de decisão estatística. A Figura 1 demonstra visualmente a ideia.
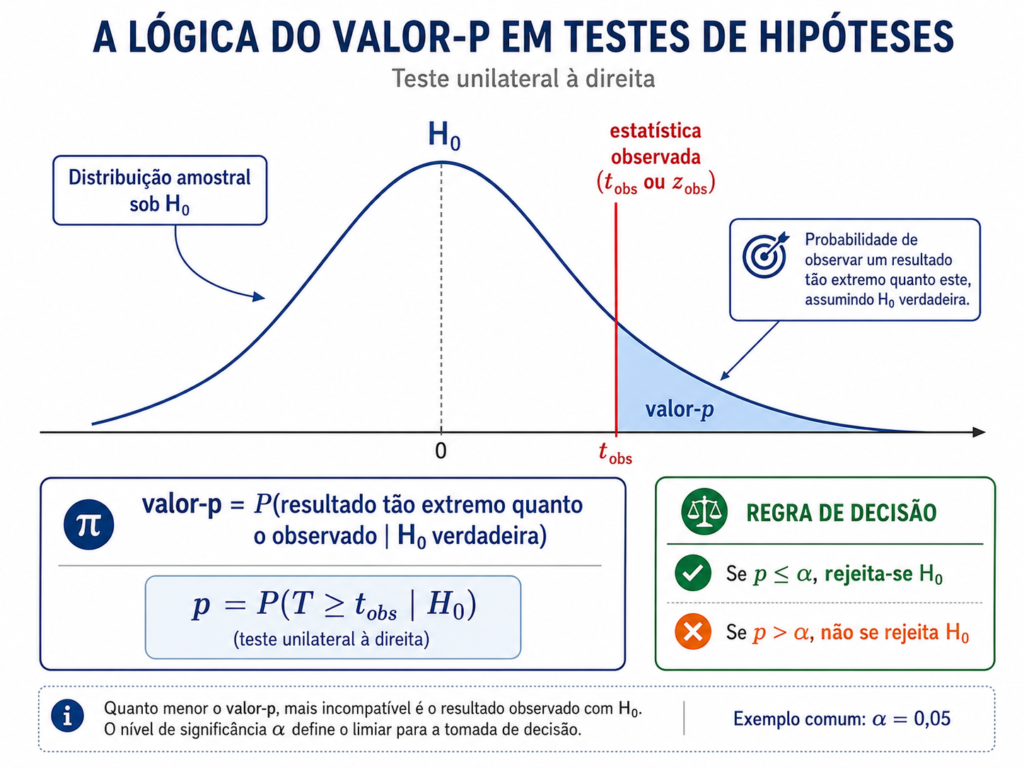
Fonte: Autoria própria com auxílio de ferramentas de IA.
A lógica matemática apresentada na Figura 1 é simples: quanto mais distante a estatística observada estiver do valor esperado sob a hipótese nula, menor será a área de probabilidade associada a esse resultado. Consequentemente, menor será o valor-p e maior será a evidência contra H₀.
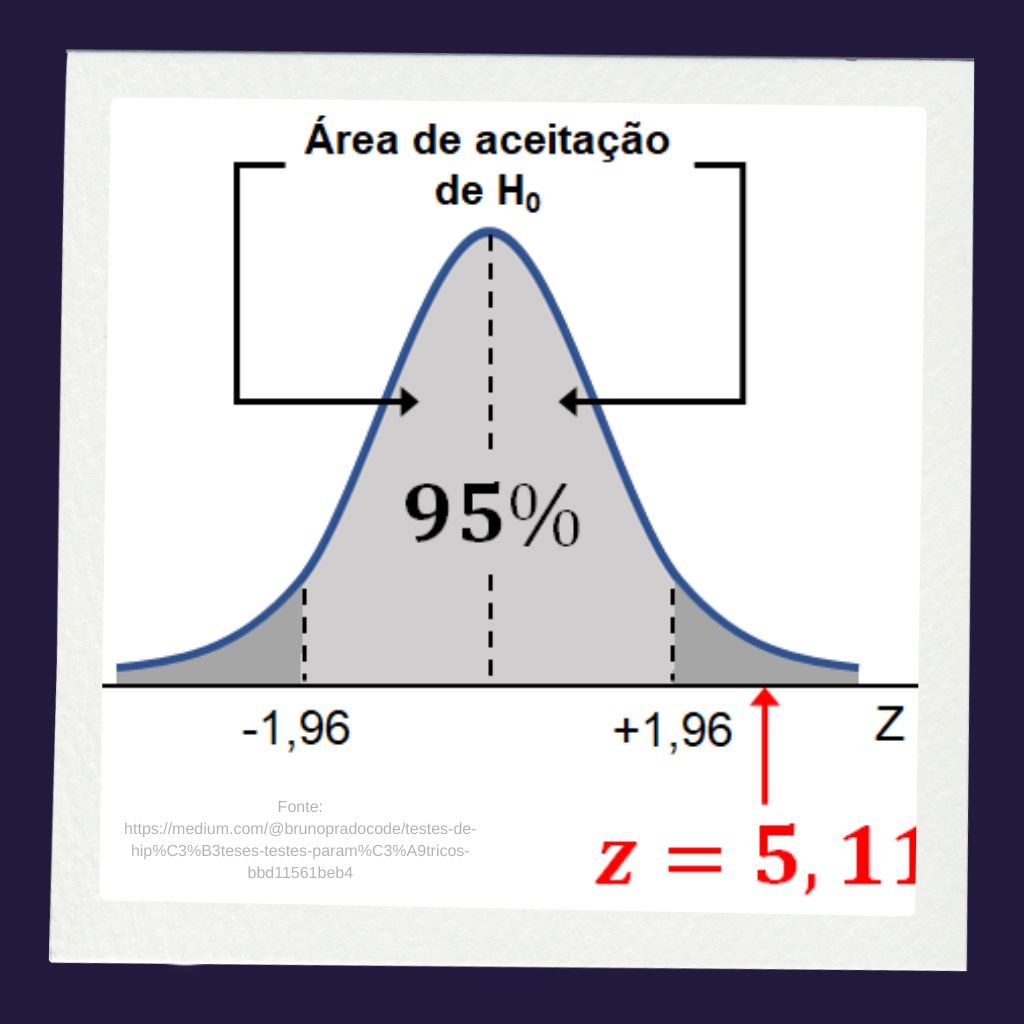
A decisão final é tomada comparando o valor-p com o nível de significância previamente definido, geralmente representado por alfa ( ). Neste caso, se , rejeita-se a hipótese nula. Caso contrário, se , não se rejeita a hipótese nula.
Exemplo para tempo médio de resposta
Imagine uma pequena empresa fictícia chamada BRSistemas, responsável por manter uma plataforma educacional usada por estudantes de Computação. A plataforma possui um problema recorrente: em horários de pico, o tempo médio de resposta das páginas fica alto, prejudicando a experiência dos usuários.
A equipe técnica decide criar uma nova versão do sistema, chamada BREduCache, pois ela usa uma camada de cache que armazena respostas frequentes para entregá-las mais rapidamente. Antes da mudança, o tempo médio de resposta era de aproximadamente 800 milissegundos. Depois da implementação, a equipe coleta uma amostra com tempos de resposta de várias requisições.
Neste exemplo, a pergunta de pesquisa é simples: a nova versão reduziu o tempo médio de resposta do sistema?
A hipótese nula representa a situação conservadora, ou seja, a nova versão não reduziu o tempo médio de resposta. A hipótese alternativa representa aquilo que a equipe deseja investigar: a nova versão reduziu o tempo médio. Assim, temos:
- H₀: o tempo médio de resposta é igual ou maior que 800 ms.
- Ha: o tempo médio de resposta é menor que 800 ms.
Esse é um teste unilateral à esquerda, pois a equipe procura evidência de redução. A lógica do teste neste exemplo é perguntar: “se o sistema realmente continuasse com média de 800 ms, seria comum obter uma amostra com média muito menor que isso?” Se a resposta for “seria muito improvável”, a equipe passa a ter evidência estatística contra H₀.
Suponha que a equipe colete 36 requisições e encontre média amostral de 760 ms. À primeira vista, houve melhoria de 40 ms. Porém, essa diferença isolada ainda não basta. É necessário observar também a variabilidade dos tempos. Se os tempos variam muito, uma média amostral de 760 ms pode ocorrer por acaso. Se os tempos variam pouco, a mesma diferença pode ser mais convincente.
Isso nos informa que um teste de hipóteses não olha apenas para a diferença observada. Segundo Bussab e Morettin (2017), o método compara a diferença com a variabilidade dos dados e com o tamanho da amostra. Quanto maior a amostra e menor a variabilidade, mais sensível tende a ser o teste para detectar diferenças reais.
Agora, vamos calcular o valor-p para este caso. Digamos que o desvio padrão amostral seja , portanto, o teste adequado é o teste t para uma média, unilateral à esquerda (queremos saber se o tempo diminuiu).
Os dados iniciais do problema são:
- Média histórica (assumida como parâmetro populacional)
- Média amostral
- Desvio padrão amostral
- Tamanho da amostra
- Hipótese nula
- Hipótese alternativa
O cálculo do erro padrão da média dá-se da seguinte maneira:
Como estamos usando a distribuição t de Student, para obtermos a estatística de teste faremos:
Os graus de liberdade são:
Como o teste é unilateral à esquerda, o valor-p é:
Neste ponto, para encontrarmos o valor-p à mão, precisaríamos calcular a área sob a curva da distribuição t de Student, e esse cálculo de área é uma integral. Como esse não é o foco do artigo, e usando a informação dos 35 graus de liberdade, obtivemos o valor-p por meio de um software estatístico. Logo, o valor-p encontrado foi:
Portanto, ao nível de significância de 5%, temos:
O valor-p que encontramos indica a probabilidade de observarmos um resultado tão extremo quanto o obtido, ou ainda mais extremo, assumindo que a hipótese nula seja verdadeira. Na interpretação fisheriana, um valor-p pequeno indica que os dados seriam pouco compatíveis com H₀ (Fisher, 1925).
Se a equipe adotar nível de significância de 5%, ou seja, , o resultado levaria à rejeição da hipótese nula . Em linguagem aplicada, a equipe poderia concluir que há evidência estatística de que a nova versão do software reduziu o tempo médio de resposta da plataforma.
Entretanto, a conclusão precisa ser escrita com cuidado. A equipe não deve dizer que “está provado” que o sistema sempre será mais rápido. Uma formulação mais adequada seria: “considerando uma amostra de 36 requisições, com média amostral de 760 ms e desvio padrão amostral de 110 ms, obteve-se uma estatística , com 35 graus de liberdade. Como o teste é unilateral à esquerda, o valor-p foi aproximadamente . Como esse valor é menor que , rejeita-se a hipótese nula ao nível de 5% de significância. Assim, os dados fornecem evidência estatística de que a nova versão do software reduziu o tempo médio de resposta do sistema.“
Cuidados na interpretação
Um erro comum é interpretar o valor-p como a probabilidade de a hipótese nula ser verdadeira, o que é uma interpretação incorreta. O valor-p é calculado supondo que a hipótese nula seja verdadeira, logo, ele indica a compatibilidade dos dados com essa suposição e não a probabilidade direta de H₀ estar correta (Fisher, 1925; Casella; Berger, 2002).
Outro cuidado envolve o nível de significância. Quando se usa , aceita-se uma tolerância de 5% para cometer erro tipo I, isto é, rejeitar H₀ quando ela é verdadeira. Já o erro tipo II ocorre quando não se rejeita H₀ mesmo quando a hipótese alternativa é verdadeira. A abordagem de Neyman e Pearson (1933) organizou formalmente esses erros, conectando teste estatístico e teoria da decisão.
Também é necessário distinguir significância estatística de relevância prática. Em amostras muito grandes, diferenças pequenas podem se tornar estatisticamente significativas. Em Computação, uma redução média de 2 ms no tempo de resposta pode gerar , mas talvez não tenha impacto perceptível para o usuário. Por outro lado, em sistemas críticos de baixa latência, essa diferença pode ser relevante. Portante, lembre-se que a interpretação depende do domínio.
Por isso, além do valor-p, recomenda-se observar intervalos de confiança, tamanho do efeito e impacto prático. De acordo com Montgomery e Runger (2018), um bom relatório estatístico deve dizer se o resultado foi “significativo”, além de explicar a magnitude da diferença, a incerteza da estimativa e as condições do estudo.
Conclusão
O teste de hipóteses é uma das ferramentas mais importantes no campo da Estatística inferencial. Ele permite avaliar afirmações sobre populações a partir de amostras, fornecendo um procedimento formal para lidar com incerteza, variabilidade e tomada de decisão científica.
Sua origem histórica está ligada a autores fundamentais como Student, Fisher, Neyman e Pearson, que desenvolveram conceitos como distribuição t, significância estatística, valor-p, hipótese nula, hipótese alternativa, erro tipo I, erro tipo II e poder do teste. Essas ideias continuam presentes em pesquisas científicas, experimentos industriais, análise de dados, engenharia de software e aprendizado de máquina.
Na área de Computação, testes de hipóteses ajudam a responder perguntas práticas: uma API ficou mais rápida? Um algoritmo é mais eficiente? Uma interface converte mais usuários? Uma nova versão reduziu erros? Um tipo de dispositivo está associado ao abandono de uma atividade? Em todos esses casos, o teste estatístico impede que decisões sejam tomadas apenas pela aparência dos números.
Esperamos que após a leitura deste artigo, você compreenda que o teste de hipóteses é menos uma “fórmula decorada” e mais um raciocínio estruturado. Primeiro, define-se a pergunta. Depois, formulam-se hipóteses. Em seguida, escolhe-se o teste adequado ao tipo de dado e ao desenho da pesquisa. Por fim, interpreta-se o resultado considerando valor-p, nível de significância, tamanho do efeito, tamanho da amostra e contexto do problema.
Obrigado pela leitura e bons estudos!
Referências
AGRESTI, Alan. Categorical data analysis. 3. ed. Hoboken: Wiley, 2013.
BUSSAB, Wilton de O.; MORETTIN, Pedro A. Estatística básica. 9. ed. São Paulo: Saraiva, 2017.
CASELLA, George; BERGER, Roger L. Statistical inference. 2. ed. Pacific Grove: Duxbury, 2002.
DEVORE, Jay L. Probabilidade e estatística para engenharia e ciências. 9. ed. São Paulo: Cengage Learning, 2018.
FISHER, Ronald A. Statistical methods for research workers. Edinburgh: Oliver and Boyd, 1925.
MONTGOMERY, Douglas C.; RUNGER, George C. Applied statistics and probability for engineers. 7. ed. Hoboken: Wiley, 2018.
MOORE, David S.; McCABE, George P.; CRAIG, Bruce A. Introduction to the practice of statistics. 9. ed. New York: W. H. Freeman, 2017.
NEYMAN, Jerzy; PEARSON, Egon S. On the problem of the most efficient tests of statistical hypotheses. Philosophical Transactions of the Royal Society of London. Series A, London, v. 231, p. 289-337, 1933.
SIEGEL, Sidney; CASTELLAN, N. John. Nonparametric statistics for the behavioral sciences. 2. ed. New York: McGraw-Hill, 1988.
STUDENT. The probable error of a mean. Biometrika, Oxford, v. 6, n. 1, p. 1-25, 1908.