Fundamentos do K-means em Aprendizado de Máquina
O K-means é uma das técnicas mais conhecidas de aprendizado de máquina não supervisionado. Diferentemente dos modelos supervisionados, que aprendem a partir de exemplos previamente rotulados, o K-means busca descobrir padrões internos nos dados sem que exista uma variável-alvo informando previamente qual é a resposta correta. Para Hastie, Tibshirani e Friedman (2009), seu objetivo central é agrupar objetos semelhantes entre si e separar objetos diferentes em grupos distintos, chamados de clusters ou agrupamentos.
No contexto da ciência de dados e da inteligência artificial, o K-means é amplamente utilizado em tarefas de segmentação, exploração de dados e descoberta de padrões. Em sistemas reais, ele pode ser aplicado para agrupar clientes com comportamentos parecidos, identificar perfis de usuários em plataformas digitais, organizar documentos semelhantes, detectar padrões em sensores ou apoiar análises preliminares antes da construção de modelos mais complexos (James et al., 2021).
O domínio do K-means é relevante porque muitos problemas práticos não chegam com respostas prontas. O papel do modelo, nesse caso, é ajudar a revelar estruturas escondidas nos dados. Essa característica torna o K-means uma técnica importante para sistemas orientados por dados, dashboards analíticos, sistemas de recomendação, ferramentas de apoio à decisão e aplicações de inteligência artificial exploratória.
A popularidade do K-means também se explica por sua simplicidade conceitual e eficiência computacional. O algoritmo é relativamente fácil de entender, implementar e interpretar. Mesmo assim, sua aplicação exige cuidados, pois seus resultados dependem da escolha do número de clusters, da escala das variáveis, da presença de outliers e da forma geométrica dos agrupamentos nos dados (Bishop, 2006).
Fundamentação matemática básica
A ideia matemática do K-means é dividir um conjunto de dados em (K) grupos, de modo que cada observação pertença ao grupo cujo centro esteja mais próximo. Esses centros são chamados de centroides. Cada centroide representa uma espécie de “média” das observações daquele grupo (Hastie; Tibshirani; Friedman, 2009).
Considere um conjunto de dados com (n) observações:
Cada observação () pode ter uma ou mais variáveis. Por exemplo, em um problema de segmentação de clientes, uma observação pode conter renda mensal, idade, frequência de compra e valor médio gasto.
O objetivo do K-means é dividir essas observações em K clusters:
Cada cluster () possui um centroide (), que representa a média das observações pertencentes àquele grupo:
A função objetivo do K-means busca minimizar a soma das distâncias quadráticas entre cada ponto e o centroide do cluster ao qual ele pertence. Essa função é conhecida como soma dos quadrados intra-cluster ou Within-Cluster Sum of Squares, geralmente abreviada como WCSS ou inertia (James et al., 2021).
Nessa equação, (J) representa o custo total do agrupamento, () representa uma observação, () representa o centroide do cluster (), e ( ) representa a distância quadrática entre o ponto e o centroide.
Na prática, o K-means geralmente utiliza a distância euclidiana para medir a proximidade entre os pontos. Para duas observações ( ) e ( ), com ( ) variáveis, a distância euclidiana é dada por:
Segundo Hastie, Tibshirani e Friedman (2009), como o algoritmo trabalha com distâncias, a escala das variáveis tem grande impacto no resultado. Se uma variável possui valores muito maiores do que outra, ela pode dominar o cálculo da distância. Por isso, é comum aplicar padronização antes do treinamento, especialmente quando as variáveis estão em unidades diferentes.
A padronização pelo escore-z pode ser representada por:
onde ( ) é o valor original da variável, ( ) é a média da variável, ( ) é o desvio-padrão, e ( ) é o valor padronizado.
Processo de treinamento do modelo
O treinamento do K-means é diferente do treinamento de modelos supervisionados. Em modelos como regressão logística, árvore de decisão ou redes neurais supervisionadas, existe uma variável de saída que informa ao algoritmo qual deveria ser a resposta correta. No K-means, isso não existe. O algoritmo recebe apenas os dados de entrada e tenta encontrar uma estrutura de agrupamento com base na proximidade entre as observações (Bishop, 2006).
O processo começa com a escolha do número de clusters, representado por K. Essa escolha é uma das decisões mais importantes do modelo. Se K for muito pequeno, grupos diferentes podem ser misturados. Se K for muito grande, o modelo pode dividir artificialmente grupos que deveriam permanecer juntos.
Depois da escolha de (K), o algoritmo inicializa os centroides. Uma estratégia comum é escolher pontos iniciais de forma aleatória. No entanto, a inicialização aleatória pode gerar resultados ruins, pois o algoritmo pode convergir para uma solução local pouco adequada. Por esse motivo, bibliotecas como o scikit-learn utilizam estratégias mais robustas, como o k-means++, que seleciona centroides iniciais de maneira mais cuidadosa para melhorar a convergência (Arthur; Vassilvitskii, 2007).
Após a inicialização, o K-means alterna entre duas etapas principais: atribuição e atualização. Na etapa de atribuição, cada ponto é associado ao centroide mais próximo. Formalmente, cada observação () é atribuída ao cluster cujo centroide minimiza a distância:
Isso significa que o algoritmo verifica todos os centroides e escolhe aquele que está mais próximo do ponto analisado.
Na etapa de atualização, o algoritmo recalcula os centroides. Cada novo centroide passa a ser a média dos pontos atribuídos ao respectivo cluster:
Essas duas etapas se repetem até que os centroides praticamente não mudem mais ou até que seja atingido um número máximo de iterações. Quando isso ocorre, dizemos que o algoritmo convergiu.
É importante observar que o K-means não “aprende” classes no sentido supervisionado. Ele não sabe, por exemplo, se um grupo representa clientes bons, clientes ruins, flores da espécie setosa ou documentos de determinado tema. O que ele faz é formar grupos matematicamente coerentes com base na distância entre os registros. A interpretação dos clusters continua sendo uma tarefa humana e analítica.
Métricas de avaliação do modelo
Avaliar um modelo K-means exige cuidado, pois geralmente não há rótulos verdadeiros para comparar com os agrupamentos encontrados. Por isso, as métricas mais utilizadas analisam propriedades internas dos clusters, como compactação, separação e estrutura geométrica dos grupos.
Uma das formas mais conhecidas de avaliação é o Método do Cotovelo, ou Elbow Method. Ele utiliza a soma dos quadrados intra-cluster, também chamada de inertia ou WCSS. A ideia é treinar o K-means com diferentes valores de K e observar como o custo diminui à medida que o número de clusters aumenta (James et al., 2021).
A inertia pode ser representada por:
À medida que (K) aumenta, a inertia tende a diminuir, pois os pontos ficam mais próximos de seus respectivos centroides. No entanto, chega um momento em que o ganho passa a ser pequeno. O ponto em que ocorre essa mudança de ritmo é chamado de “cotovelo”. Esse valor costuma ser interpretado como uma possível escolha adequada para (K).
Outra métrica importante é a Pontuação de Silhueta, ou Silhouette Score. Essa métrica mede o quanto cada ponto está bem ajustado ao seu próprio cluster em comparação com os outros clusters. Ela varia aproximadamente entre -1 e 1, de forma que os valores próximos de 1 indicam que os pontos estão bem agrupados e os valores próximos de 0 indicam sobreposição entre clusters. Conforme Rousseeuw (1987), valores negativos sugerem que pontos podem ter sido atribuídos ao cluster errado.
Para uma observação ( ), a silhueta é calculada por:
Nessa fórmula, é a distância média entre o ponto ( ) e os demais pontos do mesmo cluster. Já é a menor distância média entre o ponto ( ) e os pontos de outro cluster. A média dos valores de silhueta de todos os pontos fornece a pontuação geral do modelo.
O Índice de Calinski-Harabasz também é bastante utilizado. Ele mede a relação entre a dispersão entre clusters e a dispersão dentro dos clusters. Em geral, valores maiores indicam agrupamentos mais bem definidos (Calinski; Harabasz, 1974).
O índice pode ser representado por:
Nessa equação, () representa a dispersão entre os clusters, () representa a dispersão dentro dos clusters, () é o número de clusters e () é o número total de observações.
Outra métrica relevante, segundo Davier e Bouldin (1979), é o Índice de Davies-Bouldin. Ele avalia a similaridade média entre cada cluster e o cluster mais parecido com ele. Nesse caso, valores menores indicam melhor separação entre os grupos.
De modo geral, não se recomenda escolher K com base em uma única métrica. O ideal é combinar evidências do Método do Cotovelo, da Silhueta, do Índice de Calinski-Harabasz, do Índice de Davies-Bouldin e da interpretação do problema de negócio ou pesquisa. Em aprendizado não supervisionado, a qualidade matemática do agrupamento precisa ser compatível com uma interpretação útil no contexto analisado.
Implementação prática do algoritmo
Para a etapa prática deste artigo, vamos trabalhar a implementação do K-means em Python usando a base Iris, que está disponível na biblioteca Scikit-Learn (2026). Essa base é clássica na literatura de aprendizado de máquina e contém medidas de flores do gênero Iris. Embora a base possua rótulos reais das espécies, esses rótulos não serão usados no treinamento do K-means. Isso é importante para respeitar a lógica do aprendizado não supervisionado.
O código que vamos construir utilizará as classes e métodos das bibliotecas pandas, matplotlib e scikit-learn para manipular os dados. Portanto, começaremos importando essas dependências:
# ------------------------------------------------------------
# Carregamento das libs, classes e métodos
# ------------------------------------------------------------
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
from sklearn.decomposition import PCA
# ------------------------------------------------------------
# Carregamento da base Iris no Scikit-learn
# ------------------------------------------------------------
iris = load_iris()
dados = pd.DataFrame(
iris.data,
columns=iris.feature_names
)
print("Primeiras linhas da base:")
print(dados.head())Aproveitamos também para carregar a base de dados Iris e a carregamos na variável dados. O método head() nos permite ver as primeiras linhas do DataFrame.
Depois, vamos preparar os dados. Como o K-means usa distância para calcular a proximidade dos registros em torno de centroides, é recomendável padronizar as variáveis para que todas fiquem em escala comparável. Portanto, temos:
# ------------------------------------------------------------
# Padronização dos dados
# ------------------------------------------------------------
padronizador = StandardScaler()
dados_padronizados = padronizador.fit_transform(dados)Partiremos para a etapa de testar diferentes valores para K. No trecho de código abaixo, o valor de K representa a quantidade de clusters que o modelo deve formar. Como não existe uma resposta correta previamente rotulada no aprendizado não supervisionado, é necessário comparar diferentes possibilidades de agrupamento e avaliar qual delas produz uma estrutura mais coerente nos dados.
# ------------------------------------------------------------
# Teste de diferentes valores de K
# ------------------------------------------------------------
valores_k = range(2, 11)
inertias = []
silhuetas = []
calinski = []
davies = []
for k in valores_k:
modelo = KMeans(
n_clusters=k,
random_state=42,
n_init=10
)
clusters = modelo.fit_predict(dados_padronizados)
inertias.append(modelo.inertia_)
silhuetas.append(silhouette_score(dados_padronizados, clusters))
calinski.append(calinski_harabasz_score(dados_padronizados, clusters))
davies.append(davies_bouldin_score(dados_padronizados, clusters))A linha valores_k = range(2, 11) define que serão testados os valores de K de 2 até 10. O teste começa em 2 porque métricas como a Pontuação de Silhueta precisam comparar pelo menos dois grupos. Em seguida, são criadas quatro listas vazias: inertias, silhuetas, calinski e davies. Essas listas armazenam, respectivamente, a inertia, a Pontuação de Silhueta, o Índice de Calinski-Harabasz e o Índice de Davies-Bouldin para cada valor de K testado.
O laço for percorre cada valor de K. Em cada repetição, um novo modelo K-means é criado com n_clusters=k. O parâmetro random_state=42 fixa a aleatoriedade do algoritmo, permitindo maior reprodutibilidade dos resultados. O parâmetro n_init=10 faz com que o K-means seja executado 10 vezes com inicializações diferentes dos centroides, mantendo a melhor solução encontrada. Isso reduz o risco de o algoritmo ficar preso em uma solução inicial ruim.
A linha clusters = modelo.fit_predict(dados_padronizados) treina o modelo e atribui cada observação a um cluster. O método fit ajusta os centroides aos dados, enquanto o predict retorna o grupo ao qual cada registro pertence. Assim, a variável clusters passa a armazenar um vetor com o número do cluster de cada observação.
Depois do treinamento, o código calcula e armazena as métricas do modelo. A inertia mede a soma das distâncias quadráticas entre os pontos e seus centroides, sendo usada no Método do Cotovelo. A Pontuação de Silhueta avalia se os pontos estão bem agrupados e separados dos demais clusters. O Índice de Calinski-Harabasz mede a relação entre separação entre clusters e compactação interna. Já o Índice de Davies-Bouldin avalia a semelhança entre clusters, sendo melhor quando apresenta valores menores.
A saída gerada nesse trecho são quatro listas preenchidas com os valores das métricas para cada K testado. Essas listas podem ser usadas posteriormente para construir tabelas e gráficos, ajudando a escolher uma quantidade adequada de clusters para o modelo K-means. Inclusive, é o que fazemos no código abaixo:
# ------------------------------------------------------------
# Tabela comparativa das métricas
# ------------------------------------------------------------
resultado_metricas = pd.DataFrame({
"K": list(valores_k),
"Inertia_WCSS": inertias,
"Silhouette": silhuetas,
"Calinski_Harabasz": calinski,
"Davies_Bouldin": davies
})
print("\nMétricas para diferentes valores de K:")
print(resultado_metricas)A saída que obtemos com a linha print(resultado_metricas) é semelhante ao disposto a seguir. Para cada valor de K, temos os valores obtidos nas métricas para analisar quais foram os melhores resultados.
Métricas para diferentes valores de K:
K Inertia_WCSS Silhouette Calinski_Harabasz Davies_Bouldin
0 2 222.361705 0.581750 251.349339 0.593313
1 3 139.820496 0.459948 241.904402 0.833595
2 4 114.092547 0.386941 207.265914 0.869814
3 5 90.927514 0.345901 202.951525 0.948317
4 6 81.544391 0.317079 183.109118 1.053677
5 7 72.631144 0.320197 173.051904 0.990528
6 8 62.540606 0.338692 174.330702 0.914982
7 9 55.119493 0.342360 174.230902 0.903152
8 10 47.391035 0.351793 181.387459 0.874825O primeiro ponto a observarmos é a coluna Inertia_WCSS. Essa métrica representa a soma das distâncias quadráticas entre os pontos e os centroides de seus respectivos clusters. Quanto menor a inertia, mais próximos os pontos estão dos centroides. Na tabela, a inertia cai de 222,36 com (K = 2) para 47,39 com (K = 10). Essa redução é esperada, pois quanto maior o número de clusters, mais fácil fica aproximar cada ponto de algum centroide.
No entanto, a menor inertia não significa, sozinha, o melhor modelo. Se um profissional escolhesse apenas o menor valor de inertia, tenderia sempre a escolher valores altos de K, como K = 10. Isso poderia gerar uma divisão excessiva dos dados, criando muitos grupos pequenos e pouco úteis para interpretação. Por isso, a inertia deve ser analisada pelo Método do Cotovelo, observando o ponto em que a redução começa a perder força.
Neste resultado, há uma queda forte da inertia de K = 2 para K = 3, saindo de 222,36 para 139,82. Depois, a redução continua, mas de forma mais gradual. Isso sugere que K = 3 pode ser um candidato razoável pelo Método do Cotovelo, pois a partir dele o ganho começa a diminuir.
A coluna Silhouette mostra a Pontuação de Silhueta. Essa métrica avalia se os pontos estão bem agrupados dentro do próprio cluster e bem separados dos demais clusters. Seus valores variam aproximadamente entre -1 e 1. Quanto mais próximo de 1, melhor tende a ser a separação dos grupos. Na tabela, o maior valor de Silhouette ocorre em K = 2, com 0,581750. Isso indica que, matematicamente, a divisão em dois clusters produziu grupos mais coesos e mais bem separados.
Para K = 3, a Silhouette cai para 0,459948. Esse valor ainda é aceitável, mas mostra que a separação dos grupos ficou menos forte do que em K = 2. Isso é comum na base Iris, pois uma das espécies costuma ser bem separada das outras, enquanto as outras duas apresentam maior sobreposição. Assim, o K-means tende a encontrar uma separação matemática muito clara em dois grandes grupos, mesmo que a base original tenha três espécies.
A coluna Calinski_Harabasz também favorece K = 2. O maior valor dessa métrica é 251,349339 para K = 2, seguido por 241,904402 para K = 3. Como valores maiores de Calinski-Harabasz indicam clusters mais compactos internamente e mais separados entre si, esse resultado reforça que K = 2 apresentou a melhor estrutura matemática de agrupamento segundo essa métrica.
A coluna Davies_Bouldin deve ser interpretada de forma inversa. Nessa métrica, valores menores são melhores. O menor valor obtido foi 0,593313 para K = 2. Isso significa que, segundo o Índice de Davies-Bouldin, os clusters formados com K = 2 foram os mais bem separados e menos semelhantes entre si.
Portanto, considerando as métricas internas, o melhor valor de K parece ser K = 2. Esse valor apresentou a maior Pontuação de Silhueta, o maior Índice de Calinski-Harabasz e o menor Índice de Davies-Bouldin. Isso indica que, do ponto de vista matemático, a divisão dos dados em dois grupos foi a mais consistente.
Entretanto, K = 3 também pode ser considerado uma escolha justificável, especialmente em uma análise didática com a base Iris. Isso ocorre porque a base Iris é conhecida por possuir três espécies reais. Como o K-means não usa os rótulos das espécies durante o treinamento, ele não tenta “adivinhar” diretamente essas três classes. Ele apenas agrupa os dados conforme a proximidade entre as observações. Assim, K = 3 pode ser escolhido quando o objetivo didático é comparar a estrutura encontrada pelo algoritmo com a estrutura real da base.
Em outras palavras, se a escolha for baseada apenas nas métricas internas, K = 2 é a melhor opção. Se a escolha considerar também o conhecimento prévio sobre a base Iris, K = 3 é uma alternativa interpretável e útil. Esse resultado nos mostra que a melhor solução matemática nem sempre coincide perfeitamente com a classificação real ou com a interpretação esperada em problemas do aprendizado não supervisionado.
Continuando, vamos plotar (desenhar) os gráficos das métricas para avaliarmos visualmente os resultados obtidos pelo modelo para cada valor de K. O primeiro gráfico que construiremos é o do método do cotovelo, usando o código abaixo:
# ------------------------------------------------------------
# Gráfico do Método do Cotovelo
# ------------------------------------------------------------
plt.figure(figsize=(8, 5))
plt.plot(list(valores_k), inertias, marker="o")
plt.xlabel("Número de clusters (K)")
plt.ylabel("Inertia / WCSS")
plt.title("Método do Cotovelo para escolha de K")
plt.grid(True)
plt.show()A linha plt.figure(figsize=(8, 5)) cria uma nova figura para o gráfico. O parâmetro figsize=(8, 5) define o tamanho da imagem, com 8 polegadas de largura e 5 polegadas de altura. Essa configuração deixa o gráfico em um formato mais legível para visualização em notebooks, relatórios ou artigos.
Depois, estamos desenhando o gráfico de linhas com plt.plot(list(valores_k), inertias, marker="o"). O primeiro argumento, list(valores_k), representa os valores de K testados, por exemplo, 2, 3, 4, 5 até 10. Esses valores aparecem no eixo horizontal. O segundo argumento, inertias, representa os valores de inertia ou WCSS obtidos para cada valor de K. Esses valores aparecem no eixo vertical. O parâmetro marker="o" adiciona um marcador circular em cada ponto da linha. Isso facilita a identificação visual de cada resultado calculado pelo algoritmo.
Para definirmos o rótulo do eixo horizontal do gráfico, fizemos plt.xlabel("Número de clusters (K)"). Nesse caso, o eixo x representa o número de clusters testados pelo K-means. Portanto, cada ponto no eixo horizontal corresponde a um valor diferente de K. Para o eixo y, definimos o rótulo do eixo vertical com plt.ylabel("Inertia / WCSS"). A Inertia / WCSS representa a soma das distâncias quadráticas entre os pontos e os centroides dos clusters aos quais eles pertencem.
A linha plt.title("Método do Cotovelo para escolha de K") define o título do gráfico. O título informa que a visualização está sendo usada para aplicar o Método do Cotovelo, técnica comum para ajudar na escolha de um valor adequado de (K) no K-means.
plt.grid(True) adiciona uma grade ao gráfico para facilitar a leitura dos valores nos eixos e ajudar na observação da queda da inertia conforme o número de clusters aumenta.
Finalmente, plt.show() exibe o gráfico na tela. Em ambientes como Jupyter Notebook, Google Colab ou VS Code, ela faz com que a figura seja renderizada visualmente para o usuário.
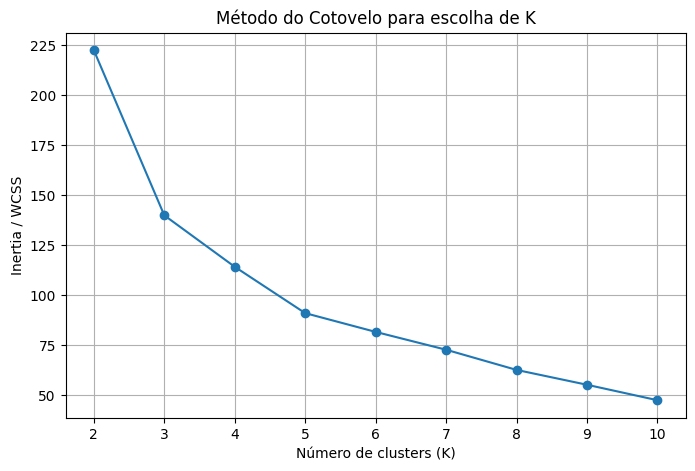
Simplificando toda a explicação, estamos construindo um gráfico de linha que compara os valores de K com os valores de inertia. A finalidade é observar em qual ponto o aumento do número de clusters deixa de gerar uma grande redução na inertia. Esse ponto é chamado de “cotovelo” e pode indicar uma quantidade adequada de clusters para o modelo K-means. A saída esperada desse trecho de código é um gráfico conforme o exposto na Figura 1.
Fonte: Autoria própria.
A interpretação geral é que valores menores de inertia indicam clusters mais compactos. Isso significa que os pontos estão mais próximos dos centroides dos grupos aos quais foram atribuídos. No gráfico, observa-se que a inertia diminui conforme o número de clusters aumenta. Esse comportamento é esperado, pois quanto maior o número de clusters, mais fácil fica aproximar cada ponto de algum centroide.
O ponto mais importante do gráfico está na mudança de ritmo da queda. De K = 2 para K = 3, a redução da inertia é bastante forte, caindo aproximadamente de 222 para 140. Isso indica que passar de dois para três clusters melhora consideravelmente a compactação dos agrupamentos. De K = 3 para K = 4, a redução ainda existe, mas já é menor. A partir de K = 5, a curva passa a cair de forma mais suave.
Essa mudança de comportamento é justamente o que se procura no Método do Cotovelo. O “cotovelo” corresponde ao ponto em que aumentar o número de clusters deixa de trazer uma melhoria tão expressiva. Neste gráfico, o cotovelo parece estar entre K = 3 e K = 5, com destaque para K = 3 ou K = 5, dependendo do critério adotado pelo profissional.
Considerando a queda mais intensa da curva, K = 3 pode ser interpretado como uma escolha bastante razoável. Ele representa um ponto em que houve grande redução da inertia em comparação com K = 2, mas antes de a curva entrar em uma região de ganhos menores. Essa escolha também é coerente em uma análise didática da base Iris, pois essa base é conhecida por possuir três espécies reais, ainda que o K-means não utilize esses rótulos durante o treinamento.
Por outro lado, se o analista observar a estabilização mais clara da curva, também pode argumentar que K = 5 marca uma redução importante antes de uma sequência de quedas menores. No entanto, escolher K = 5 pode gerar uma fragmentação maior dos dados, criando mais grupos do que o necessário para uma interpretação simples.
Portanto, o gráfico sugere que não vale a pena escolher automaticamente valores muito altos de K, como 8, 9 ou 10. Embora eles apresentem inertia menor, essa redução ocorre porque o modelo está dividindo os dados em mais grupos, e não necessariamente porque encontrou uma estrutura mais útil. Em aprendizado não supervisionado, a menor inertia isoladamente não garante o melhor agrupamento.
O próximo gráfico que plotaremos é o da pontuação de silhueta. O resultado que obtemos está descrito na Figura 2.
# ------------------------------------------------------------
# Gráfico da Pontuação de Silhueta
# ------------------------------------------------------------
plt.figure(figsize=(8, 5))
plt.plot(list(valores_k), silhuetas, marker="o")
plt.xlabel("Número de clusters (K)")
plt.ylabel("Silhouette Score")
plt.title("Pontuação de Silhueta para diferentes valores de K")
plt.grid(True)
plt.show()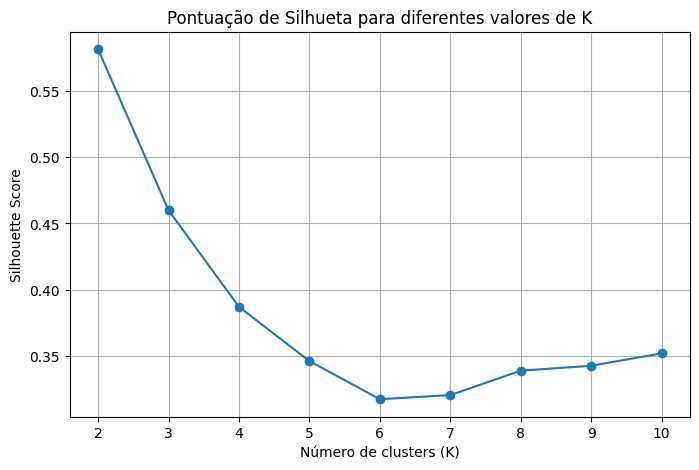
Fonte: Autoria própria.
No eixo horizontal, aparecem os valores de K, que representam a quantidade de clusters testada. No eixo vertical, aparece a Silhouette Score, métrica usada para avaliar a qualidade interna dos agrupamentos.
No gráfico, observa-se que o maior valor de Silhueta ocorre em K = 2, com aproximadamente 0,58. Isso significa que, do ponto de vista matemático dessa métrica, a divisão dos dados em dois clusters foi a mais bem definida. Nesse caso, os grupos ficaram mais coesos internamente e mais separados entre si.
Quando K = 3, a Pontuação de Silhueta cai para aproximadamente 0,46. Esse valor ainda pode ser considerado razoável, mas indica que a separação entre os clusters ficou menor do que em K = 2. Em outras palavras, ao dividir os dados em três grupos, o modelo passou a encontrar uma estrutura um pouco mais sobreposta.
A queda continua entre K = 4, K = 5 e K = 6, chegando ao menor valor em K = 6, com aproximadamente 0,32. Isso indica que, nessa faixa, os agrupamentos ficaram menos nítidos. Os pontos passaram a ficar menos bem separados entre os clusters, sugerindo uma divisão mais fragmentada dos dados.
A partir de K = 7, há uma pequena recuperação da Silhueta, chegando a aproximadamente 0,35 em K = 10. No entanto, essa melhora é discreta e não supera os resultados obtidos com K = 2 e K = 3. Portanto, valores altos de K, como 8, 9 ou 10, não parecem trazer uma vantagem significativa para a qualidade dos agrupamentos.
A principal conclusão do gráfico é que K = 2 foi o melhor valor para a Pontuação de Silhueta. Isso significa que, considerando apenas essa métrica, o modelo encontrou a estrutura mais clara quando separou os dados em dois grupos. No caso da base Iris, esse resultado é compreensível, pois uma das espécies costuma ser bem separada das demais, enquanto as outras duas apresentam maior sobreposição. Assim, o algoritmo identifica com facilidade dois grandes blocos de dados. Entretanto, K = 3 também pode ser usado em uma análise didática, especialmente porque a base Iris possui três espécies reais. Nesse caso, a escolha de K = 3 não é a melhor pela Silhueta, mas é coerente com o conhecimento prévio sobre a base.
A partir das análises que fizemos com os números e os gráficos, e considerando a informação prévia que temos da base Iris, usaremos K = 3 como escolha didática para mantermos a coerência com a estrutura conhecida da base.
# ------------------------------------------------------------
# Treinamento final com K = 3
# ------------------------------------------------------------
modelo_final = KMeans(
n_clusters=3,
random_state=42,
n_init=10
)
clusters_finais = modelo_final.fit_predict(dados_padronizados)
dados["cluster"] = clusters_finais
print("\nDados com clusters atribuídos:")
print(dados.head())Os agrupamentos que obtivemos com K=3 foram:
Dados com clusters atribuídos:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) \
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
cluster
0 1
1 1
2 1
3 1
4 1 Como usamos o método head(), não conseguimos ver todo o conjunto de dados. As primeiras cinco linhas foram todas agrupadas no cluster 1, mas não é uma regra que sempre as primeiras linhas serão do cluster 1. Para vermos mais linhas, podemos imprimir a base completa ou podemos observar apenas as últimas cinco com o método tail().
Agora, queremos observar como ficou a separação dos grupos (clusters) considerando K=3. Como a base Iris possui quatro variáveis (sepal length (cm), sepal width (cm), petal length (cm), petal width (cm)), usamos o método Principal Component Analysis (PCA) para reduzir a dimensionalidade dos dados e projetá-los em duas dimensões para facilitar a visualização.
# ------------------------------------------------------------
# Redução de dimensionalidade com PCA
# ------------------------------------------------------------
pca = PCA(n_components=2)
dados_pca = pca.fit_transform(dados_padronizados)
grafico = pd.DataFrame({
"PC1": dados_pca[:, 0],
"PC2": dados_pca[:, 1],
"cluster": clusters_finais
})Finalmente, vamos plotar o gráfico dos clusters:
# ------------------------------------------------------------
# Gráfico final dos clusters
# ------------------------------------------------------------
plt.figure(figsize=(8, 6))
for cluster in sorted(grafico["cluster"].unique()):
grupo = grafico[grafico["cluster"] == cluster]
plt.scatter(
grupo["PC1"],
grupo["PC2"],
label=f"Cluster {cluster}"
)
plt.xlabel("Componente Principal 1")
plt.ylabel("Componente Principal 2")
plt.title("Clusters encontrados pelo K-means na base Iris")
plt.legend()
plt.grid(True)
plt.show()O gráfico da separação dos clusters que obtivemos com o código anterior está apresentado na Figura 3. Cada ponto representa uma flor da base de dados, e cada cor representa um cluster atribuído pelo modelo. Como a base Iris possui quatro variáveis originais, foi aplicada uma redução de dimensionalidade com PCA para projetar os dados em apenas duas dimensões: Componente Principal 1 e Componente Principal 2.
Essa redução foi feita apenas para facilitar a visualização. O K-means foi treinado com os dados padronizados completos, mas o gráfico mostra uma representação bidimensional dos agrupamentos. Portanto, os eixos do gráfico não correspondem diretamente às variáveis originais da base, como comprimento da pétala ou largura da sépala. Eles representam combinações matemáticas dessas variáveis originais.
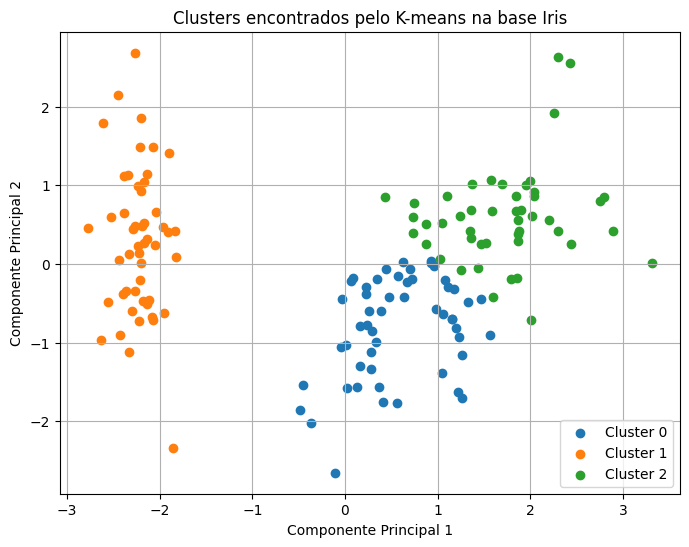
Fonte: Autoria própria.
No gráfico, observa-se que o Cluster 1, representado pelos pontos laranja, está bem separado dos demais. Ele aparece concentrado à esquerda, com pouca sobreposição em relação aos outros grupos. Isso indica que esse conjunto de observações possui características bastante distintas. No caso da base Iris, esse comportamento é esperado, pois uma das espécies costuma ser mais facilmente separável das demais.
Os clusters 0 e 2, representados pelos pontos azul e verde, aparecem mais próximos entre si. Existe uma separação visual razoável entre eles, mas também há uma região de transição em que os pontos ficam próximos. Isso indica que esses dois grupos possuem características mais parecidas, dificultando uma separação totalmente nítida pelo K-means.
Esse resultado é coerente com as métricas obtidas anteriormente. A Pontuação de Silhueta mostrou que K = 2 produziu uma separação matemática mais forte, enquanto K = 3 gerou uma divisão aceitável, mas com maior sobreposição. O gráfico confirma essa interpretação: há um grupo claramente separado e dois grupos parcialmente próximos.
A principal informação do gráfico é que o K-means conseguiu identificar uma estrutura de agrupamento relevante nos dados. Ele separou bem um dos grupos e dividiu os demais em dois conjuntos próximos, mas ainda visualmente distinguíveis. Isso mostra que o modelo conseguiu capturar padrões presentes na base Iris mesmo sem usar os rótulos reais das espécies durante o treinamento.
No entanto, é importante lembrar que os nomes Cluster 0, Cluster 1 e Cluster 2 não têm significado semântico automático. Eles são apenas identificadores numéricos criados pelo algoritmo. O K-means não sabe qual cluster corresponde a qual espécie da base Iris. Portanto, a interpretação dos grupos precisa ser feita posteriormente por quem vaia analisar os dados, comparando as características médias de cada cluster ou, em um contexto didático, comparando com os rótulos reais da base. Em aplicações reais, depois de treinar o K-means, o profissional deve investigar o perfil de cada cluster, calcular médias das variáveis por grupo e verificar se os agrupamentos fazem sentido para a tomada de decisão.
Nosso algoritmo já está bom o suficiente, mas caso você queira imprimir os valores das métricas para o modelo final com K = 3, pode complementar com o trecho abaixo:
# ------------------------------------------------------------
# Métricas do modelo final
# ------------------------------------------------------------
silhueta_final = silhouette_score(dados_padronizados, clusters_finais)
calinski_final = calinski_harabasz_score(dados_padronizados, clusters_finais)
davies_final = davies_bouldin_score(dados_padronizados, clusters_finais)
print("\nMétricas do modelo final com K = 3:")
print(f"Silhouette Score: {silhueta_final:.4f}")
print(f"Calinski-Harabasz: {calinski_final:.4f}")
print(f"Davies-Bouldin: {davies_final:.4f}")O resultado que você encontrará deve ser algo semelhante ao descrito abaixo:
Métricas do modelo final com K = 3:
Silhouette Score: 0.4599
Calinski-Harabasz: 241.9044
Davies-Bouldin: 0.8336Como os dados são os mesmos e o algoritmo também é o mesmo, observaremos que os valores encontrados agora são idênticos aos números da tabela apresentada no início do código onde buscamos testar diversos valores de K (compare com a linha onde K = 3).
Conclusão
O K-means é uma técnica fundamental para quem atua com aprendizado de máquina, ciência de dados e inteligência artificial. Sua principal contribuição está na capacidade de revelar agrupamentos em bases de dados sem depender de rótulos prévios. Essa característica torna o algoritmo especialmente útil em contextos exploratórios, nos quais o analista ainda não conhece a estrutura dos dados ou deseja descobrir perfis, padrões e segmentos.
Para o profissional de sistemas, compreender o K-means amplia sua capacidade de construir soluções orientadas por dados, de forma que o algoritmo pode ser integrado a dashboards, sistemas de recomendação, ferramentas de segmentação, módulos de análise de comportamento e aplicações de apoio à decisão. No entanto, seu uso exige atenção técnica, pois a escolha do número de clusters, a padronização das variáveis, a presença de outliers e a interpretação dos resultados são fatores decisivos para que o modelo produza informações úteis.
Obrigado pela leitura e bons estudos!
Referências
ARTHUR, David; VASSILVITSKII, Sergei. K-means++: the advantages of careful seeding. In: ANNUAL ACM-SIAM SYMPOSIUM ON DISCRETE ALGORITHMS, 18., 2007, New Orleans. Proceedings […]. Philadelphia: Society for Industrial and Applied Mathematics, 2007. p. 1027-1035.
BISHOP, Christopher M. Pattern recognition and machine learning. New York: Springer, 2006.
CALINSKI, Tadeusz; HARABASZ, Jerzy. A dendrite method for cluster analysis. Communications in Statistics, London, v. 3, n. 1, p. 1-27, 1974.
DAVIES, David L.; BOULDIN, Donald W. A cluster separation measure. IEEE Transactions on Pattern Analysis and Machine Intelligence, New York, v. PAMI-1, n. 2, p. 224-227, 1979.
HASTIE, Trevor; TIBSHIRANI, Robert; FRIEDMAN, Jerome. The elements of statistical learning: data mining, inference, and prediction. 2. ed. New York: Springer, 2009.
JAMES, Gareth; WITTEN, Daniela; HASTIE, Trevor; TIBSHIRANI, Robert. An introduction to statistical learning: with applications in R. 2. ed. New York: Springer, 2021.
ROUSSEEUW, Peter J. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics, Amsterdam, v. 20, p. 53-65, 1987.
SCIKIT-LEARN. Clustering. Scikit-learn documentation. Disponível em: https://scikit-learn.org/stable/modules/clustering.html. Acesso em: 20 jun. 2026.