Aprendizado Supervisionado: Redes Neurais Artificiais
As Redes Neurais Artificiais, ou RNAs, são modelos computacionais de aprendizado de máquina inspirados de forma abstrata no funcionamento de sistemas neurais biológicos, conforme a comparação na Figura 1. Em termos práticos, uma RNA aprende padrões a partir de dados por meio do ajuste progressivo de pesos numéricos associados às conexões entre seus neurônios artificiais. Esse processo permite que o modelo aproxime funções complexas, reconheça regularidades e produza previsões ou classificações a partir de exemplos observados anteriormente (Haykin, 2009; Bishop, 2006).
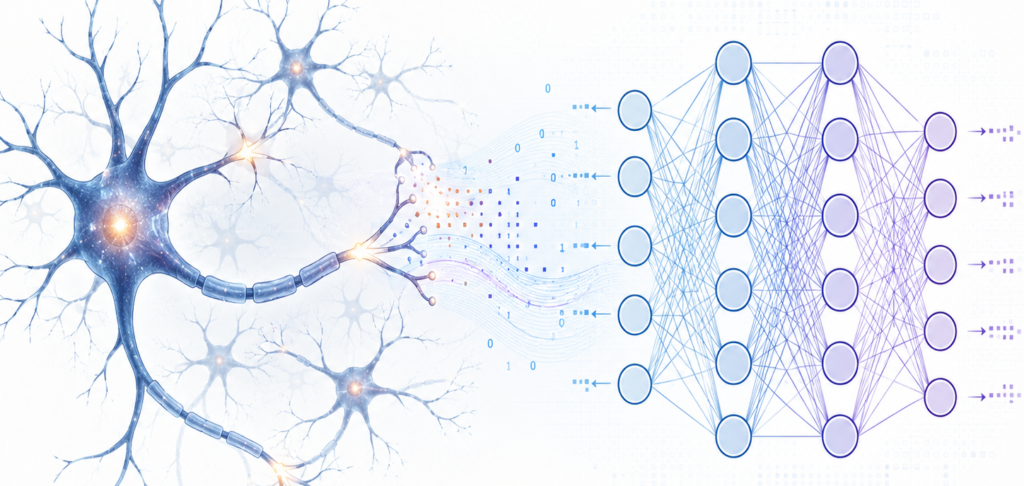
Fonte: Autoria própria com auxílio de ferramentas de IA.
No aprendizado supervisionado, as RNAs são usadas quando há um conjunto de dados composto por variáveis de entrada e uma saída conhecida. A partir desses exemplos, o modelo aprende uma relação entre os atributos observados e o resultado esperado. Essa abordagem é aplicada em diferentes áreas da ciência de dados e da inteligência artificial, como diagnóstico auxiliado por computador, análise de crédito, detecção de fraudes, reconhecimento de imagens, processamento de linguagem natural, recomendação de produtos e previsão de eventos futuros (Goodfellow; Bengio; Courville, 2016).
Outro cenário em que uma RNA pode ser usada é na previsão se um estudante tende a concluir o curso ou entrar em evasão, por exemplo. Para isso, o modelo pode usar variáveis como situação de trabalho, renda familiar, escolaridade dos pais, desempenho em programação e retenção acadêmica. Neste cenário (e em outros), a ideia não é substituir a decisão humana, mas oferecer um instrumento analítico para apoiar tomadas de decisão e ações efetivas.
Fundamentação matemática do modelo
O modelo base Perceptron
A versão base de um neurônio artificial recebe um vetor de entrada, multiplica cada entrada por um peso, soma um viés e aplica uma função de ativação. Essa formulação deriva da ideia de Perceptron proposta por Rosenblatt, um dos primeiros modelos computacionais de aprendizado supervisionado (Rosenblatt, 1958).
Em termos matemáticos, podemos dizer que para um vetor de entrada:
e um vetor de pesos:
o neurônio calcula primeiro a combinação linear:
(ou, em forma vetorial):
e depois aplica uma função de ativação:
Nessa estrutura, os pesos w indicam a importância relativa de cada variável de entrada. O viés b, ou bias, desloca a fronteira de decisão do modelo, permitindo que o neurônio aprenda padrões mesmo quando todas as entradas estão próximas de zero. A função de ativação introduz não linearidade, permitindo que redes multicamadas aprendam relações mais complexas do que uma simples regressão linear (Haykin, 2009; Goodfellow; Bengio; Courville, 2016).
O funcionamento matemático do Perceptron simples pode ser visto de forma visual na Figura 2.
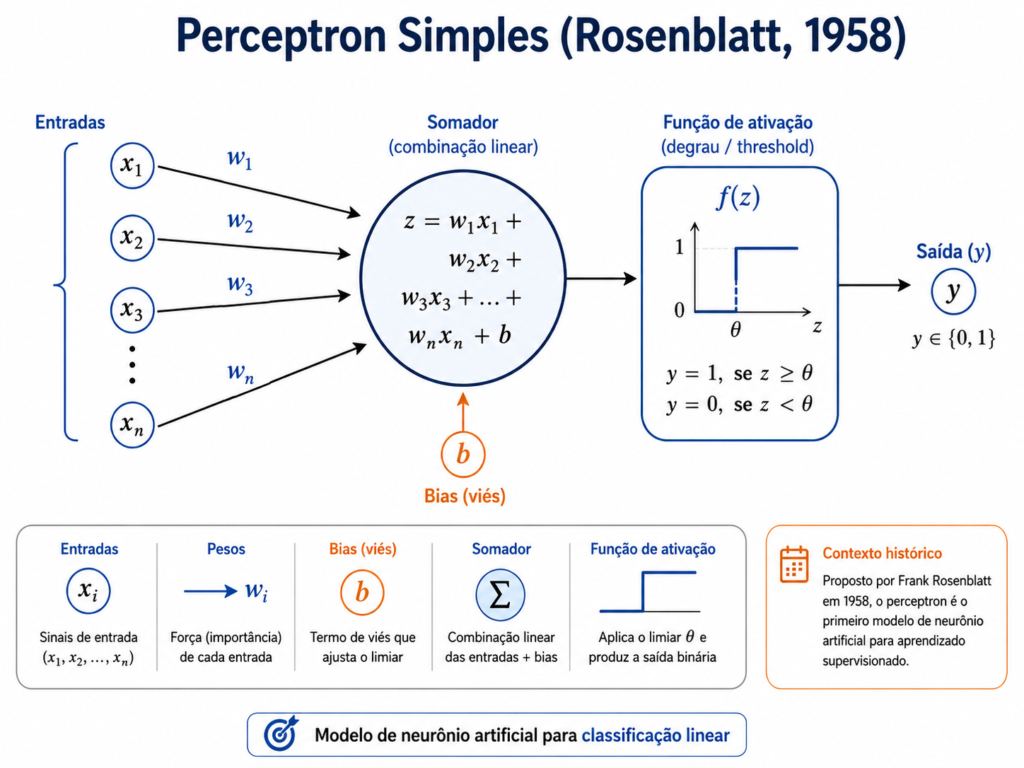
Fonte: Autoria própria com auxílio de ferramentas de IA.
Do Perceptron simples aos modelos com múltiplas camadas (MLP)
O Perceptron simples possui uma única camada de saída e é limitado a problemas linearmente separáveis. O Multilayer Perceptron, ou MLP, amplia essa ideia ao organizar neurônios em camadas: uma camada de entrada, uma ou mais camadas ocultas e uma camada de saída, conforme descrito na Figura 3.
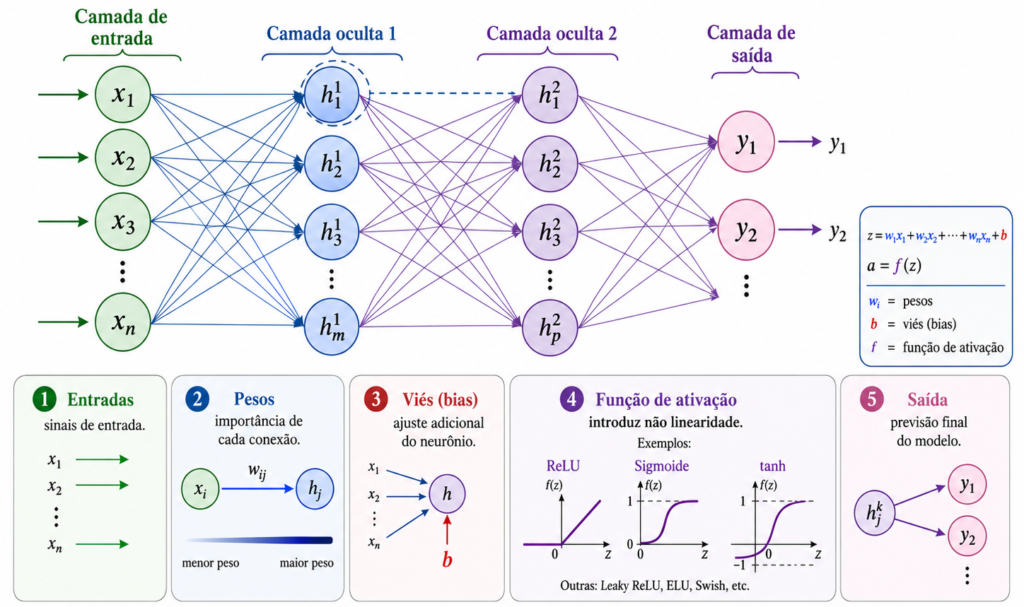
Fonte: Autoria própria com auxílio de ferramentas de IA.
Para uma rede com apenas uma camada oculta, temos a primeira camada realizando os cálculos com os valores de entrada () e gerando a ativição :
A segunda camada (ou camada oculta) não usa os valores de () diretamente, substituindo-os pelos valores da função de ativição :
Por fim, a função de decisão (ou saída final do modelo) será obtida a partir da segunda camada (a camada oculta deste exemplo):
Para problemas binários, a função sigmoide é adequada como função de decisão porque transforma o valor calculado em uma probabilidade entre 0 e 1, conforme a equação:
Se a saída for próxima de 1, o modelo pode interpretar o caso como alta probabilidade de evasão. Se for próxima de 0, pode interpretar como maior probabilidade de sucesso.
Funções de ativação
As funções de ativação definem como a saída de um neurônio artificial será transformada antes de seguir para a próxima camada da rede. Sem elas, uma rede neural formada por várias camadas equivaleria, matematicamente, a uma única transformação linear, o que limitaria sua capacidade de representar padrões complexos. A função degrau, usada no Perceptron clássico, produz uma saída binária a partir de um limiar de decisão, sendo adequada para classificações simples, mas pouco útil em redes multicamadas treinadas por gradiente, pois não oferece derivadas apropriadas para a retropropagação (Rosenblatt, 1958; Haykin, 2009).
Entre as funções historicamente importantes estão a Sigmoide e a Tangente Hiperbólica. A Sigmoide transforma qualquer valor real em um número entre 0 e 1, o que a torna útil em saídas de problemas de classificação binária, especialmente quando se deseja interpretar o resultado como probabilidade. A sigmoide é definida como:
A Tangente Hiperbólica, por sua vez, transforma os valores para o intervalo entre -1 e 1, produzindo ativações centradas em zero, característica que pode favorecer o processo de otimização em comparação com a Sigmoide. Essas funções apresentam saturação em regiões extremas, onde seus gradientes se tornam muito pequenos, dificultando o aprendizado em redes mais profundas, fenômeno associado ao problema do desaparecimento do gradiente (Goodfellow; Bengio; Courville, 2016).
Nas arquiteturas modernas, a ReLU tornou-se uma das funções de ativação mais utilizadas em camadas ocultas. Sua definição simples é dada por:
e preserva valores positivos ao mesmo tempo que zera valores negativos, favorecendo eficiência computacional e reduzindo parte dos problemas de saturação observados em funções sigmoides. Variantes como Leaky ReLU, Parametric ReLU e ELU foram propostas para tratar limitações da ReLU, como neurônios que deixam de atualizar seus pesos quando passam a produzir sempre zero.
Em camadas de saída, a escolha da ativação depende do tipo de problema: Sigmoide para classificação binária, Softmax para classificação multiclasse e função linear para regressão (Goodfellow; Bengio; Courville, 2016; Bishop, 2006).
Fases de treinamento do modelo
O treinamento de uma RNA consiste em ajustar progressivamente seus pesos e vieses para que a saída produzida pelo modelo se aproxime da saída esperada nos dados de treinamento. Esse processo ocorre de forma iterativa: a rede recebe exemplos de entrada, calcula previsões, mede o erro cometido e modifica seus parâmetros internos para reduzir esse erro nas próximas passagens.
Em termos gerais, o aprendizado da rede depende de duas etapas complementares: a propagação direta, responsável por produzir a previsão, e a retropropagação, responsável por calcular como os pesos devem ser corrigidos (Haykin, 2009; Goodfellow; Bengio; Courville, 2016).
Fase de Propagação direta (Forward Propagation)
Na propagação direta, ou forward propagation, os dados atravessam a rede da camada de entrada até a camada de saída. Cada neurônio calcula uma combinação linear entre as entradas recebidas, os pesos associados e o viés; em seguida, aplica uma função de ativação para produzir sua saída. Essa saída se torna a entrada da próxima camada, formando uma sequência de transformações matemáticas. Em uma rede multicamadas, cada camada constrói uma nova representação dos dados, permitindo que padrões simples sejam combinados em estruturas mais complexas ao longo do fluxo de cálculo (Bishop, 2006).
Para uma rede com apenas uma camada oculta, o cálculo é igual ao descrito na seção Do Perceptron simples aos modelos com múltiplas camadas (MLP). Nela, vimos que a primeira camada realiza os cálculos com os valores de entrada (), gerando a ativição :
Em seguida, a segunda camada (ou camada oculta) não usa os valores de () diretamente, substituindo-os pelos valores da função de ativição :
Por fim, a função de decisão (saída final do modelo) será obtida a partir da segunda camada (a camada oculta deste exemplo):
Após a propagação direta, o modelo compara a previsão produzida com o valor real esperado por meio de uma função de perda. Em problemas de classificação binária, por exemplo, é comum usar a entropia cruzada binária; em problemas de regressão, pode-se usar o erro quadrático médio. Essa função resume numericamente a distância entre o que a rede previu e o que deveria ter previsto. O valor da perda orienta o treinamento, pois indica se os parâmetros atuais estão produzindo respostas adequadas ou se precisam ser ajustados para melhorar o desempenho do modelo (Goodfellow; Bengio; Courville, 2016).
Fase de Retropropagação (Backpropagation)
Na fase de retropropagação, ou backpropagation, o modelo calcula a contribuição de cada peso e viés para o erro final da rede. Esse cálculo utiliza a regra da cadeia do cálculo diferencial, propagando o erro da camada de saída em direção às camadas anteriores. Com os gradientes calculados, um algoritmo de otimização, como o gradiente descendente, atualiza os parâmetros na direção que reduz a função de perda.
A atualização genérica de um peso pelo gradiente descendente é dada pela equação:
sendo o viés atualizado de modo semelhante:
Nessas equações, L representa a função de perda, η representa a taxa de aprendizagem e a derivada parcial indica a direção de maior crescimento do erro. Como o objetivo é reduzir o erro, o modelo “caminha” na direção oposta ao gradiente (daí o sinal negativo).
A regra da cadeia aparece porque o erro final depende da saída, que depende das ativações, que dependem dos pesos e dos vieses das camadas anteriores:
Esse ciclo de propagação direta, cálculo da perda, retropropagação e atualização dos pesos se repete por várias “épocas” (iterações no código), até que a rede alcance um desempenho satisfatório ou até que algum critério de parada seja atingido (Rumelhart; Hinton; Williams, 1986; Haykin, 2009).
Função de perda
As funções de perda, ou loss functions, são métricas internas usadas durante o treinamento para medir o erro entre a saída prevista pela rede neural e o valor real esperado. Elas transformam o desempenho do modelo em um único valor numérico, permitindo que o algoritmo de otimização saiba em qual direção os pesos e vieses devem ser ajustados.
Em redes neurais, a função de perda ocupa uma posição central porque é a partir dela que os gradientes são calculados na retropropagação. Quanto menor o valor da perda, mais próximas tendem a estar as previsões do modelo em relação aos valores corretos, embora essa interpretação sempre dependa do tipo de problema e da função escolhida (Haykin, 2009; Goodfellow; Bengio; Courville, 2016).
Em problemas de classificação binária, uma das funções de perda mais utilizadas é a Entropia Cruzada Binária, ou Binary Cross-Entropy. Ela é adequada quando a variável alvo possui duas classes, como 0 e 1, e a rede produz uma probabilidade para a classe positiva. Sua fórmula pode ser dada como:
em que é o valor real e é a probabilidade prevista. Essa função penaliza fortemente previsões confiantes e erradas; por exemplo, quando o modelo atribui probabilidade muito baixa a uma classe que realmente ocorreu. Essa característica torna a entropia cruzada apropriada para treinar classificadores probabilísticos (Bishop, 2006; Goodfellow; Bengio; Courville, 2016).
Em problemas de classificação multiclasse, a função de perda mais comum é a Entropia Cruzada Categórica, usada quando cada exemplo pertence a uma entre várias classes possíveis. Nesse caso, a camada de saída normalmente utiliza a função Softmax, que transforma os valores finais da rede em uma distribuição de probabilidades sobre as classes.
A perda compara a distribuição prevista com a classe correta, penalizando o modelo quando ele atribui baixa probabilidade à resposta verdadeira. Em termos práticos, essa função é muito usada em tarefas como reconhecimento de imagens, classificação de textos e categorização automática de registros, nas quais o modelo precisa escolher uma classe entre várias alternativas (Bishop, 2006; Goodfellow; Bengio; Courville, 2016).
Para problemas de regressão, nos quais a rede prevê valores numéricos contínuos, funções como o Erro Quadrático Médio e o Erro Absoluto Médio são mais adequadas. O Erro Quadrático Médio calcula a média dos quadrados das diferenças entre valores reais e previstos, penalizando erros grandes com mais intensidade; enquanto o Erro Absoluto Médio calcula a média dos módulos dessas diferenças, oferecendo uma medida mais direta do tamanho médio dos erros.
A escolha da função de perda deve acompanhar a natureza do problema: perdas baseadas em entropia são apropriadas para classificação probabilística, enquanto perdas baseadas em distância numérica são usadas em regressão. Essa decisão afeta diretamente o modo como a rede aprende, pois define quais erros serão considerados mais graves durante o ajuste dos parâmetros (Hastie; Tibshirani; Friedman, 2009; Goodfellow; Bengio; Courville, 2016).
Métricas de avaliação do modelo
Após o treinamento, as métricas de avaliação permitem verificar como a Rede Neural Artificial se comporta diante de dados que não foram usados diretamente para ajustar seus pesos. Essa etapa é essencial para estimar a capacidade de generalização do modelo, pois um bom desempenho no conjunto de treino pode indicar apenas memorização dos exemplos observados. Segundo Bishop (2006) e Haykin (2009), em aprendizado supervisionado, a avaliação costuma ser feita com um conjunto de teste ou validação, separado previamente, para comparar as previsões do modelo com os valores reais conhecidos.
Em situações que envolvem problemas de classificação, métricas como acurácia, precisão, sensibilidade (recall), F1-Score e matriz de confusão são úteis pois ajudam a analisar diferentes tipos de acerto e erro do modelo.
Matriz de confusão
A matriz de confusão é uma representação tabular que organiza os acertos e erros de um modelo de classificação. Em problemas binários, ela costuma ser dividida em quatro categorias: verdadeiros positivos (VP), verdadeiros negativos (VN), falsos positivos (FP) e falsos negativos (FN). A ordenação dos elementos pode variar, mas normalmente encontramos a tabela configurada da seguinte forma:
De acordo com Hastie, Tibshirani e Friedman (2009), sua principal utilidade está em mostrar a natureza dos erros cometidos pelo modelo, permitindo observar se ele erra mais ao classificar exemplos positivos como negativos ou exemplos negativos como positivos. Essa métrica é a base para o cálculo de várias outras medidas de desempenho em classificação.
Outra vantagem para a métrica é que ela permite interpretar os resultados de forma mais próxima das consequências práticas do problema estudado.
Acurácia
A acurácia mede a proporção total de previsões corretas em relação ao número total de exemplos avaliados. Sua formulação depende dos elementos que encontramos para a matriz de confusão e é dada por:
Ela é uma métrica intuitiva e útil quando as classes estão razoavelmente equilibradas. Em bases desbalanceadas, sua interpretação exige cautela, pois um modelo pode obter alta acurácia simplesmente ao favorecer a classe majoritária (Bishop, 2006).
Precisão
A precisão mede, entre todos os exemplos classificados como positivos pelo modelo, quantos realmente pertenciam à classe positiva. Sua fórmula é dada por:
Uma precisão alta indica que o modelo gera poucos falsos positivos. Essa métrica é útil quando o custo de uma classificação positiva incorreta é elevado, pois ajuda a avaliar se as previsões positivas do modelo são confiáveis do ponto de vista estatístico e operacional (Hastie; Tibshirani; Friedman, 2009).
Recall (ou Sensibilidade)
O recall, também chamado de sensibilidade, mede a capacidade do modelo de identificar corretamente os exemplos pertencentes à classe positiva. Sua fórmula é dada por:
sendo que um valor de recall alto indica que o modelo deixou passar poucos casos positivos, ou seja, produziu poucos falsos negativos. Para Goodfellow, Bengio e Courville (2016), essa métrica é especialmente relevante quando o erro de não identificar um caso positivo tem impacto maior do que o erro de classificar indevidamente um caso negativo como positivo.
F1-Score
O F1-Score é uma métrica que combina precisão e recall por meio da média harmônica entre essas duas medidas e sua fórmula é obtida a partir da razão:
Ele é útil quando se deseja equilibrar a capacidade do modelo de encontrar exemplos positivos e, ao mesmo tempo, evitar classificações positivas incorretas. Por penalizar desequilíbrios entre precisão e recall, o F1-Score costuma ser mais informativo do que a acurácia em problemas com distribuição desigual entre as classes (Bishop, 2006; Hastie; Tibshirani; Friedman, 2009).
Implementação da RNA em Python
A partir da fundamentação matemática das redes neurais artificiais, partiremos para uma tentativa de implementação em linguagem Python. Para orientar nossos trabalhos, vamos adotar o seguinte cenário de exemplo: uma instituição tem uma base de dados com a situação final de vários estudantes que passaram pelo curso de Análise e Desenvolvimento de Sistemas, indicando quem concluiu o curso e quem evadiu.
A base é constituida por 354 registros (linhas) e 17 colunas. A nossa variável alvo é a coluna Situação, que possui as classes SUCESSO e EVASAO. Com exceção da coluna RETENÇÃO, que é numérica, as demais variáveis usadas no exemplo são categóricas. Destacamos que a coluna POSICAO será removida do treinamento, pois tende a representar uma informação posterior ou diretamente associada ao desfecho do aluno, como CONCLUIDO, FECHADO ou MATRICULADO. Usá-la poderia gerar vazamento de dados, fazendo o modelo “aprender” uma resposta que não estaria disponível no momento real da previsão.
A base de dados está em formato CSV e pode ser baixada no link: BASE DE EXEMPLO.
A primeira coisa que faremos é importar todas as classes e métodos que precisamos da biblioteca Scikit-learn para criar, treinar, testar e avaliar nossa RNA. Também importaremos a lib Pandas para outras operações com os dados.
# ============================================================
# IMPORTAÇÃO DAS BIBLIOTECAS
# ============================================================
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import (
confusion_matrix,
classification_report,
accuracy_score,
precision_score,
recall_score,
f1_score
)Observação: Uma vez que você baixou o arquivo CSV em sua máquina, trate de descobrir onde está o arquivo e deixe-o no mesmo diretório do seu script python. A base até pode estar numa pasta diferente, mas você precisará alterar a variável "caminho_arquivo" para detalhar completamente o caminho do diretório.O código abaixo carrega o CSV e imprime as 5 primeiras linhas do dataframe (.head), as informações da base (.info) e a contagem dos valores contidos na coluna Situacao.
# ============================================================
# CARREGAMENTO DA BASE DE DADOS
# ============================================================
caminho_arquivo = "BASE_DE_DADOS_Estatistica_sem_acentos.csv"
dados = pd.read_csv(caminho_arquivo)
print(dados.head())
print(dados.info())
print(dados["Situacao"].value_counts())Agora faremos um pré-processamento da base para corrigir pequenas imperfeições nos dados que temos a disposição. Esse pré-processamento inclui a padronização no uso de acentos e outros caracteres especiais, a remoção de colunas desnecessárias, a definição das classes positiva e negativa e a reomoção da coluna Situacao original.
# ============================================================
# LIMPEZA E DEFINIÇÃO DA VARIÁVEL ALVO
# ============================================================
# Padroniza pequenas diferenças textuais, como NAO e NÃO.
dados["PROGRAMACAO"] = dados["PROGRAMACAO"].replace({
"NÃO": "NAO"
})
# Remove a coluna POSICAO para evitar vazamento de informação.
# Essa coluna representa uma condição posterior do estudante.
dados = dados.drop(columns=["POSICAO"])
# Define a variável alvo.
# EVASAO será a classe positiva: 1.
# SUCESSO será a classe negativa: 0.
dados["alvo_evasao"] = dados["Situacao"].map({
"SUCESSO": 0,
"EVASAO": 1
})
# Remove a coluna textual original da variável alvo.
dados = dados.drop(columns=["Situacao"])Seguindo a lógica, faremos a separação das variáveis (colunas) que servirão de entrada (X) e de saída (y). Além disso, vamos especificar quais colunas são numéricas e quais são categóricas.
# ============================================================
# SEPARAÇÃO ENTRE VARIÁVEIS EXPLICATIVAS E ALVO
# ============================================================
X = dados.drop(columns=["alvo_evasao"])
y = dados["alvo_evasao"]
variaveis_numericas = ["RETENCAO"]
variaveis_categoricas = [
"EMPREGADO",
"RENDA INDIV",
"MEMBROS FAM",
"RENDA BRUTA FAMILIAR",
"ENSINO_MED",
"CIDADE",
"PROC ZONA",
"ESCOLA_PAI",
"ESCOLA_MAE",
"Modalidade de ingresso",
"SEXO",
"Estado Civil",
"Cor/Raca",
"PROGRAMACAO"
]O método train_test_split divide os dados em treino e teste. O parâmetro test_size=0.25 reserva 25% dos dados para avaliação. O parâmetro stratify=y mantém proporção semelhante entre EVASAO e SUCESSO nos conjuntos de treino e teste (estratificação), o que é importante em problemas de classificação.
# ============================================================
# DIVISÃO ENTRE TREINO E TESTE
# ============================================================
X_treino, X_teste, y_treino, y_teste = train_test_split(
X,
y,
test_size=0.25,
random_state=42,
stratify=y
)O método Pipeline integra as possibilidade de pré-processamento do Scikit-learn e serve para colocar o modelo em uma única estrutura. Isso evita erros comuns, como aplicar transformação nos dados de teste antes da separação, e torna o experimento mais reprodutível.
Para a variável numérica utilizamos o método StandardScaler para padronizar a coluna RETENÇÃO, deixando-a com mediana próxima de 0 e desvio padrão próximo de 1. Isso é relevante para redes neurais porque variáveis em escalas muito diferentes podem dificultar o processo de otimização.
Por sua vez, nas variáveis categóricas, utilizamos o OneHotEncoder, que transforma as colunas categóricas em binárias. Por exemplo, uma variável como EMPREGADO, com valores SIM e NAO, passa a ser representada numericamente. A documentação oficial do Scikit-learn (2026) define o método OneHotEncoder como um codificador que transforma categorias textuais ou discretas em uma representação one-hot, criando uma coluna binária para cada categoria.
# ============================================================
# PRÉ-PROCESSAMENTO DAS VARIÁVEIS
# ============================================================
pipeline_numerico = Pipeline(steps=[
("imputador", SimpleImputer(strategy="median")),
("padronizador", StandardScaler())
])
pipeline_categorico = Pipeline(steps=[
("imputador", SimpleImputer(strategy="most_frequent")),
("codificador", OneHotEncoder(handle_unknown="ignore", sparse_output=False))
])
pre_processador = ColumnTransformer(transformers=[
("numericas", pipeline_numerico, variaveis_numericas),
("categoricas", pipeline_categorico, variaveis_categoricas)
])O ColumnTransformer aplica transformações diferentes a grupos diferentes de colunas. Ele é adequado para bases heterogêneas, nas quais algumas variáveis são numéricas e outras são categóricas. O Scikit-learn (2026) descreve esse componente como um estimador que aplica transformadores separadamente a subconjuntos de colunas e concatena os resultados em um único espaço de atributos.
Em seguida, criaremos a RNA para nosso exemplo e vamos usar o MLPClassifier neste código. O parâmetro hidden_layer_sizes=(16, 8) cria duas camadas ocultas: a primeira com 16 neurônios e a segunda com 8. O parâmetro activation="relu" usa a função ReLU nas camadas ocultas.
# ============================================================
# CRIAÇÃO DO MODELO DE REDE NEURAL ARTIFICIAL
# ============================================================
classificador_rna = MLPClassifier(
hidden_layer_sizes=(16, 8),
activation="relu",
solver="adam",
alpha=0.001,
max_iter=1000,
early_stopping=True,
validation_fraction=0.15,
random_state=42
)O parâmetro solver="adam" seleciona o algoritmo de otimização Adam para otimizar a função de perda, sendo muito usado em redes neurais por ajustar a taxa de atualização dos pesos de forma adaptativa. O parâmetro max_iter=1000 define o número máximo de iterações de treinamento.
No código abaixo estamos completando o pipeline do classificador via RNA. No pipeline estamos embutindo a fase do pré-processamento e da formulação inicial do modelo.
# ============================================================
# CRIAÇÃO DO PIPELINE COMPLETO
# ============================================================
modelo = Pipeline(steps=[
("pre_processamento", pre_processador),
("classificador", classificador_rna)
])Com a variável modelo completa (pipeline finalizado), partiremos para o treinamento da rede neural. Para isso, usamos o método .fit() da biblioteca scikit-learn. Cabe reforçar que para o treinamento devemos sempre usar os conjuntos X e y de treino.
# ============================================================
# TREINAMENTO DO MODELO
# ============================================================
modelo.fit(X_treino, y_treino)Finalizado o treinamento do modelo, faremos a predição com o conjunto de entrada para teste (X_teste). Como retorno, teremos os valores da variável alvo (y_predito) previstas pelo classificador RNA.
# ============================================================
# PREDIÇÃO NO CONJUNTO DE TESTE
# ============================================================
y_predito = modelo.predict(X_teste)Finalmente, chamamos os métodos para calcularem as métricas dicutidas na seção Métricas de avaliação do modelo. É importante observar que para o cálculo correto das métricas, é necessário que passemos como parâmetros dois conjuntos: o y_teste, que representa os valores reais esperados para cada linha do conjunto de teste; e o y_predito, que são os valores previstos pelo classificador.
Além dos valores isolados, também imprimimos o relatório de classificação do Scikit-learn (classification_report).
# ============================================================
# AVALIAÇÃO DO MODELO
# ============================================================
matriz = confusion_matrix(
y_teste,
y_predito,
labels=[0, 1]
)
print("Matriz de confusão:")
print(matriz)
print("\nRelatório de classificação:")
print(classification_report(
y_teste,
y_predito,
target_names=["SUCESSO", "EVASAO"]
))
acuracia = accuracy_score(y_teste, y_predito)
precisao = precision_score(y_teste, y_predito)
recall = recall_score(y_teste, y_predito)
f1 = f1_score(y_teste, y_predito)
print(f"Acurácia: {acuracia:.3f}")
print(f"Precisão: {precisao:.3f}")
print(f"Recall: {recall:.3f}")
print(f"F1-Score: {f1:.3f}")Do código acima, obtemos os resultados descritos a seguir. Na matriz de confusão, percebemos que o modelo de RNA foi capaz de detectar:
- VN – 28 casos classificados corretamente como
SUCESSO(o aluno não abandonou o curso). - FN – 11 casos classificados erradamente como
SUCESSO(ou seja, classificou o aluno como não evadido, mas na verdade ele abandonou o curso). - FP – 12 casos classificados erradamente como
EVASAO(ou seja, classificou o aluno como evadido, mas na verdade ele não abandonou o curso). - VP – 38 casos classificados corretamente como
EVASAO(o aluno abandonou o curso).
Matriz de confusão:
[ [28 12]
[11 38] ]Com esses dados, devemos considerar o problema abordado para detectar os valores que chamam mais a atenção e que podem gerar mais consequências. Por exemplo, seguindo o contexto, o número de falsos negativos (FN) pode ser mais problemático. Isso ocorre porque o número 11 indica a quantidade de alunos que o modelo previu como não tendo risco de evasão, mas que na verdade abandonaram o curso. Em um sistema funcionando em produção e comercialmente viável, qualquer caso de FN poderia inibir a instituição a tomar medidas preventivas com futuros alunos acreditando no eventual sucesso deles.
Para além da matriz de confusão, o relatório de classificação explicitou um comportamento médio do sistema em torno de 75% de acurácia, o que pode ser bom ou ruim, dependendo do baseline que você tem como referência. Além disso, percebemos que o modelo tem desempenho ligeiramente melhor para classificar os casos de evasão. Esse resultado até que faz algum sentido, pois ele foi treinado com mais registros de evasão. Logo, é plausível considerarmos que ele tenha desenvolvido uma espécie de “viés” para detectar esta classe.
Relatório de classificação:
precision recall f1-score support
SUCESSO 0.72 0.70 0.71 40
EVASAO 0.76 0.78 0.77 49
accuracy 0.74 89
macro avg 0.74 0.74 0.74 89
weighted avg 0.74 0.74 0.74 89Por fim, os valores isolados que imprimimos corroboraram as observações feitas no relatório de classificação, indicando as mesmas taxas de acurácia, precisão, recall e f1-score (obs: as impressões isoladas mostram os maiores valores encontrados pelo modelo, que neste caso foram os da classe EVASAO).
Acurácia: 0.742
Precisão: 0.760
Recall: 0.776
F1-Score: 0.768Para analisarmos os resultados obtidos, primeiro, vamos comparar com uma regra ingênua. Se a base tem, por exemplo, 55% de evasão e 45% de sucesso, um modelo burro que sempre chutasse a classe majoritária já teria cerca de 55% de acurácia. Nesse caso, 74% indica ganho real. Se a base fosse muito desbalanceada, por exemplo 90% de uma classe, então 74% seria ruim. No nosso caso, como as classes parecem relativamente próximas, 74% tende a ser um resultado inicial aceitável.
Segundo, vamos observar quais métricas estão em 74%. Se acurácia, precisão, recall e F1-score estão todas próximas disso, o modelo está relativamente equilibrado. Mas se a acurácia é 74% e o recall para EVASAO é baixo, por exemplo, o modelo pode ser inadequado para políticas de permanência, porque estaria deixando de identificar estudantes em risco. Para o tipo de problema que estamos abordando, o recall da classe EVASAO costuma ser mais importante que a acurácia isolada.
Terceiro, considere o tamanho e a natureza da base. Com cerca de algumas centenas de registros, variáveis categóricas sociais e acadêmicas, e possível ruído nos dados, 74% é um desempenho razoável para um primeiro modelo. Não é excelente, mas também não é ruim. É um resultado intermediário, útil para análise exploratória e comparação com outros modelos.
Conclusão
Redes Neurais Artificiais são ferramentas poderosas para problemas supervisionados de classificação, especialmente quando há relações não lineares entre as variáveis. No contexto de evasão estudantil que usamos de exemplo, elas podem ajudar instituições de ensino a detectar padrões de risco e planejar intervenções mais oportunas.
A principal força das redes neurais está em sua capacidade de representar relações não lineares. Enquanto modelos mais simples podem ter dificuldade para capturar interações complexas entre variáveis, uma rede neural multicamadas consegue combinar sucessivas transformações matemáticas para construir representações internas mais sofisticadas dos dados. Essa característica torna as RNAs especialmente relevantes em problemas nos quais os padrões não são facilmente descritos por regras explícitas ou por relações lineares simples (Bishop, 2006; Goodfellow; Bengio; Courville, 2016).
Essa capacidade, entretanto, também exige cuidado metodológico. Redes neurais dependem de dados bem preparados, escolha adequada de arquitetura, definição criteriosa de funções de ativação, controle do processo de treinamento e avaliação com métricas coerentes ao problema. Modelos neurais podem apresentar subajuste (underfitting), quando são simples demais para aprender os padrões relevantes, ou sobreajuste (overfitting), quando aprendem excessivamente os detalhes do conjunto de treinamento e perdem capacidade de generalização para novos casos (Haykin, 2009).
Obrigado pela leitura e bons estudos!
Referências
BISHOP, Christopher M. Pattern recognition and machine learning. New York: Springer, 2006.
GOODFELLOW, Ian; BENGIO, Yoshua; COURVILLE, Aaron. Deep learning. Cambridge: MIT Press, 2016.
HAYKIN, Simon. Neural networks and learning machines. 3. ed. Upper Saddle River: Pearson, 2009.
ROSENBLATT, Frank. The perceptron: a probabilistic model for information storage and organization in the brain. Psychological Review, Washington, v. 65, n. 6, p. 386-408, 1958.
RUMELHART, David E.; HINTON, Geoffrey E.; WILLIAMS, Ronald J. Learning representations by back-propagating errors. Nature, London, v. 323, p. 533-536, 1986.
SCIKIT-LEARN. MLPClassifier. Documentação oficial. Disponível em: <https://scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPClassifier.html>. Acesso em: 4 jun. 2026.
SCIKIT-LEARN. OneHotEncoder. Documentação oficial. Disponível em: <https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html>. Acesso em: 4 jun. 2026.
SCIKIT-LEARN. ColumnTransformer. Documentação oficial. Disponível em: <https://scikit-learn.org/stable/modules/generated/sklearn.compose.ColumnTransformer.html>. Acesso em: 4 jun. 2026.
SCIKIT-LEARN. Classification metrics. Documentação oficial. Disponível em: <https://scikit-learn.org/stable/modules/model_evaluation.html#classification-metrics>. Acesso em: 4 jun. 2026.