Aprendizado supervisionado: Regressão Logística
A regressão logística é uma técnica estatística e de aprendizado de máquina usada principalmente para problemas de classificação, sobretudo quando a variável de saída possui duas classes possíveis: sim/não, aprovado/reprovado, fraude/não fraude, evasão/não evasão, tumor benigno/maligno, cliente cancela/não cancela.
No desenvolvimento de software moderno, esse tipo de problema aparece com frequência considerável. Um sistema financeiro pode estimar se uma transação é fraudulenta; uma plataforma educacional pode prever risco de evasão; um aplicativo de saúde pode classificar exames como suspeitos ou não suspeitos; um sistema de recomendação pode estimar se um usuário clicará ou não em um item. Em todos esses casos, o objetivo não é apenas prever um número contínuo, mas estimar a probabilidade de ocorrência de uma classe.
A regressão logística surge como uma continuação conceitual da regressão linear. Na regressão linear, procura-se modelar uma variável quantitativa contínua por meio de uma combinação linear das variáveis explicativas, conforme equação abaixo:
Para ler mais sobre Regressão Linear, leia o artigo clicando aqui.Esse modelo é adequado quando a saída esperada pode assumir valores em uma escala contínua, como preço, temperatura, nota ou tempo de execução. Porém, em problemas binários, a saída costuma ser codificada como 0 ou 1. Se aplicarmos diretamente uma regressão linear para prever uma classe binária, o modelo poderá gerar valores menores que 0 ou maiores que 1, o que não faz sentido quando queremos interpretar a saída como probabilidade.
Por isso, a regressão logística transforma a combinação linear dos atributos em uma probabilidade entre 0 e 1. Na literatura de aprendizado estatístico, a regressão logística é frequentemente apresentada como um classificador linear probabilístico. James et al. (2021) explicam que ela é apropriada quando a variável resposta pertence a categorias e quando se deseja estimar a probabilidade condicional de uma classe dado um conjunto de atributos. De modo semelhante, Agresti (2013) destaca que modelos logísticos pertencem à família dos modelos lineares generalizados, pois usam uma função de ligação para relacionar a média da resposta a uma combinação linear dos preditores.
Função Sigmoide
Hosmer, Lemeshow e Sturdivant (2013) tratam a regressão logística como um dos modelos fundamentais para análise de desfechos com duas possibilidades, justamente porque ela permite relacionar variáveis explicativas a probabilidades de ocorrência de um evento. A lógica da regressão logística é manter uma estrutura linear nos parâmetros (vide abaixo), mas aplicar uma função não linear, chamada função sigmoide, para limitar a saída ao intervalo probabilístico.
A partir da combinação linear dos atributos, busca-se transformar o valor em uma probabilidade. O detalhe é que o valor pode assumir qualquer número real (). Para fazer essa transformação, usamos a função sigmoide, também chamada de função logística, que é descrita pela equação:
de forma que a saída da função sigmoide sempre estará no intervalo entre . Isso acontece porque o denominador da equação () é sempre positivo. Quando é muito grande e positivo, tende a 0, fazendo com que se aproxime de 1. Quando é muito negativo, cresce muito, fazendo com que se aproxime de 0. Quando , temos:
Essa característica da função sigmoide cria um gráfico semelhante à Figura 1, onde há duas classes (0 para ‘Não’ e 1 para ‘Sim’) e os valores dos parâmetros (quantidade de palavras-chave) ficam encapsulados entre esses valores.
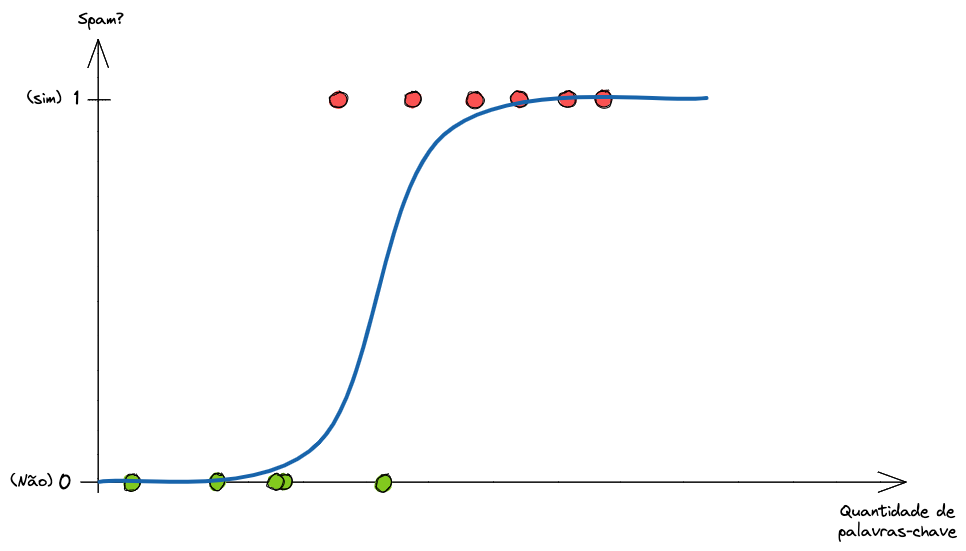
Fonte: Retirado de https://brains.dev/2023/modelos-de-classificacao-regressao-logistica/.
Dessa forma, podemos dizer que a regressão logística estima a probabilidade de uma observação pertencer à classe 1, dado o vetor de atributos (vide equação abaixo).
Entendendo o conceito de odds (ou razão de chances)
Para compreendermos a regressão logística de modo mais profundo, precisamos entender um pouco mais o conceito de odds (também conhecida como razão de chances). Se é a probabilidade de um evento ocorrer, então a chance de ele não ocorrer é . A razão de chances (odds) é definida como:
Por exemplo, se a probabilidade de um aluno evadir é , então diremos que a chance de evasão é 4 vezes a chance de não evasão, conforme o cálculo a seguir:
Segundo Agresti (2013), o uso de odds é especialmente importante em modelos para dados categóricos porque permite interpretar o efeito dos preditores em termos multiplicativos sobre as chances de ocorrência do evento.
Aplicando o logaritmo das chances (Logit)
A regressão logística não modela diretamente a probabilidade como uma função linear dos atributos. Em vez disso, ela modela o logaritmo da razão de chances, chamado de logit, dada pela equação:
E porque isso acontece? A ideia é que o logit transforme uma probabilidade limitada ao intervalo entre 0 e 1 em um valor que pode variar de a . Isso permite conectar o problema de classificação binária a uma estrutura linear:
A equação acima mostra como é feita a linearização do problema. A probabilidade em si não é linear em relação aos atributos, mas o logaritmo das chances é linear nos parâmetros. Hosmer, Lemeshow e Sturdivant (2013) enfatizam que essa propriedade torna a regressão logística interpretável, pois cada coeficiente ( ) representa a variação no logaritmo das chances associada ao aumento de uma unidade em , mantendo as demais variáveis constantes.
Se aplicarmos a exponencial em ambos os lados da equação, temos:
Como o modelo estima o logaritmo das chances, cada coeficiente indica o efeito de um atributo sobre o logit. Ao aplicar a exponencial no coeficiente (vide equação abaixo), obtemos o Odds Ratio (OR).
O valor indica por quanto as chances do evento são multiplicadas quando aumenta uma unidade, mantendo os demais atributos constantes. Por exemplo, se , o atributo aumenta as chances do evento; se , o atributo reduz as chances do evento; por fim, se , o atributo não altera as chances.
Suponha que um atributo tem . Isso significa que, mantendo os demais atributos constantes, o aumento de uma unidade nesse atributo multiplica as chances do evento por 1,5. Caso o valor seja , as chances são multiplicadas por 0,7, isto é, diminuem.
Otimização do treinamento
Na regressão linear, é comum treinarmos o modelo para minimizar o Erro Quadrático Médio (do inglês, Mean Squared Error), dado pela equação:
Esse custo é adequado quando a saída do modelo é contínua e o erro pode ser tratado como uma diferença numérica direta entre valor real e valor previsto. Porém, na regressão logística, a saída é uma probabilidade produzida pela função sigmoide. Em casos assim, quando o MSE é combinado com a função sigmoide, a superfície de erro pode se tornar não convexa, criando regiões com mínimos locais que dificultam a otimização, conforme observamos a descrição na Figura 2.
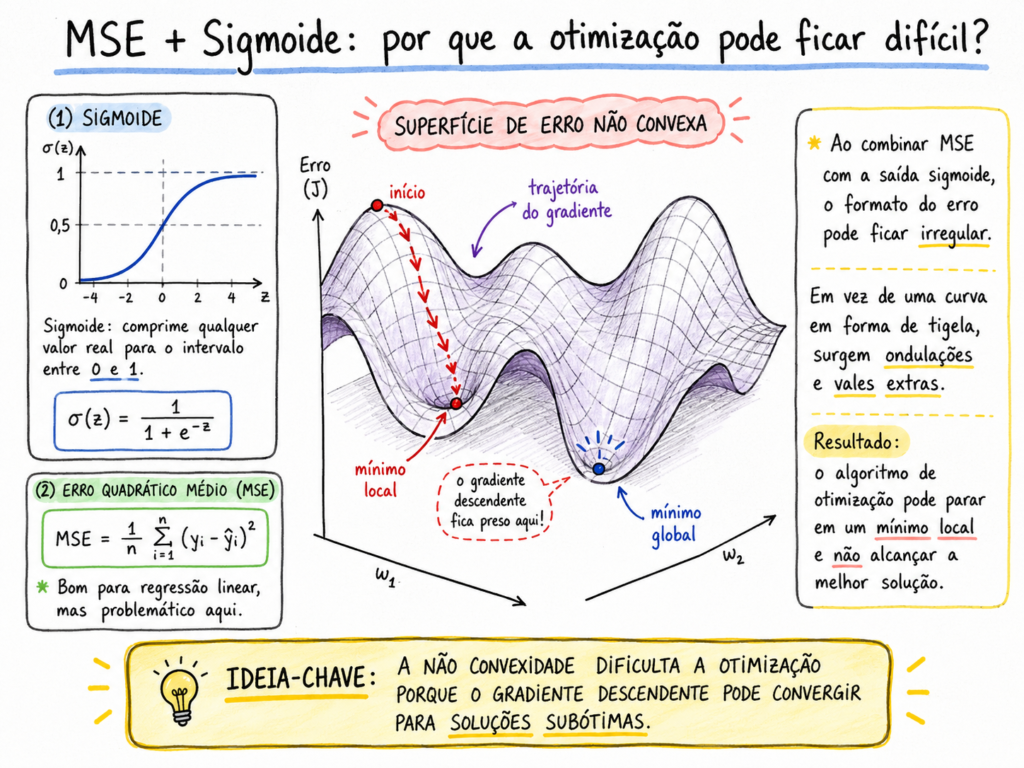
Fonte: Autoria própria com auxílio de ferramenta de IA.
Goodfellow, Bengio e Courville (2016) explicam que a escolha da função de custo em modelos probabilísticos deve estar alinhada ao princípio da máxima verossimilhança, isto é, busca-se encontrar os coeficientes que tornem os dados observados mais prováveis sob o modelo.
Além disso, como a regressão logística modela uma variável binária, a distribuição probabilística natural é a Bernoulli. Por isso, em vez de minimizar o erro quadrático, o modelo normalmente minimiza a Entropia Cruzada Binária, também conhecida como Log Loss.
Podemos encontrar dois cenários para calcular a Log Loss. A primeira é quando temos apenas uma observação, onde a equação da Log Loss é dada por:
Entretanto, a segunda possibilidade ocorre quando temos observações. Quando isto acontece, a equação é dada por:
A função Log Loss penaliza fortemente previsões confiantes e erradas. Se o valor real é , o custo fica pequeno quando se aproxima de 1 e cresce muito quando se aproxima de 0. Se o valor real é , ocorre o oposto: o custo fica pequeno quando se aproxima de 0 e cresce muito quando se aproxima de 1.
Como a regressão logística é normalmente ajustada pelo método da máxima verossimilhança, minimizar a função Log Loss equivale a maximizar a verossimilhança, pois a Log Loss é a forma negativa da log-verossimilhança média.
Gradiente Descendente
O Gradiente Descendente é um algoritmo de otimização que ajusta os parâmetros do modelo na direção de maior redução da função de custo. A regra geral de atualização de um peso é:
O parâmetro da equação é a taxa de aprendizado. Ele controla o tamanho do passo dado em cada atualização. Se for muito pequeno, o treinamento pode ser lento. Se for muito grande, o algoritmo pode oscilar ou divergir.
Na regressão logística, considerando:
podemos escrever o gradiente da função de custo em relação aos pesos como:
E, no caso específico para o viés (ou bias), temos:
Para a atualização dos pesos e do viés, seguimos a lógica dada nas equações a seguir:
Reconhecemos nossa limitação para explorar mais profundamente as equações, suas origens e definições conforme os preceitos matemáticos. Contudo, considerando que este artigo foca em estudantes graduandos em Análise e Desenvolvimento de Sistemas que muitas vezes não têm a base matemática necessária, acreditamos que seja suficiente ao menos demonstrar de onde vem as interpretações e o que acontece por “debaixo dos panos” nos algoritmos de regressão logística, mesmo que sem demonstrar profundamente o procedimento matemático.
Dito isso, para ajudar na compreensão desta seção podemos dizer que, em termos intuitivos, o modelo calcula a diferença entre a probabilidade prevista e o valor real para depois usar essa diferença nos ajustes dos coeficientes. Quando o modelo erra muito, os ajustes tendem a ser maiores. Quando o erro diminui, os ajustes tendem a ficar menores.
Métricas de avaliação do modelo
A avaliação de modelos de classificação exige mais cuidado do que a simples comparação entre valor previsto e valor real. Em classificação binária, especialmente quando as classes são desbalanceadas, a acurácia pode ser insuficiente. Por isso, costuma-se analisar outras métricas, tais como matriz de confusão, precisão, recall, F1-Score e AUC.
Acurácia
A métrica chamada acurácia mede a proporção total de acertos do modelo e é dada pela equação:
Onde cada elemento significa:
- verdadeiro positivo, que representa os casos positivos corretamente classificados.
- verdadeiro negativo, que representa os casos negativos corretamente classificados.
- falso positivo, que representa os casos negativos classificados incorretamente como positivos.
- falso negativo, que representa os casos positivos classificados incorretamente como negativos.
Basicamente, a acurácia tenta medir o quanto o modelo foi capaz de acertar após seu treinamento. Logo, esta é uma métrica intuitiva e de fácil compreensão. Contudo, ela pode ser enganosa. Por exemplo, se 95% das transações de um banco são legítimas e apenas 5% são fraudes, um modelo que sempre prevê uma transação como “não fraude” terá 95% de acurácia, mas será inútil para detectar fraudes.
Matriz de Confusão
Para complementar as análises obtidas com a acurácia, vamos começar avaliando o comportamento prático do modelo por meio da matriz de confusão. Ela organiza os resultados em quatro categorias, conforme abaixo, de forma que os elementos significam a mesma coisa que apresentamos na acurácia.
Em problemas reais, cada tipo de erro tem um custo diferente. Em um sistema médico, um falso negativo (FN) pode significar não encaminhar um paciente que precisava de investigação. Em um sistema bancário, um falso positivo (FP) pode bloquear uma transação legítima. Em uma plataforma educacional, um falso negativo (FN) pode deixar de identificar um aluno com risco de evasão.
Por isso, a análise não deve depender apenas da acurácia. Em bases desbalanceadas, a acurácia pode parecer alta mesmo quando o modelo ignora a classe minoritária. Esse problema é recorrente em aplicações de fraude, evasão, inadimplência e diagnóstico, nas quais a classe mais importante costuma ser menos frequente.
Precisão
A precisão é a métrica que mede, entre todos os casos classificados como positivos, quantos realmente eram positivos. Ela busca responder à pergunta “quando o modelo diz que algo é positivo, com que frequência ele está correto?” e é dada pela equação:
A precisão é especialmente importante de se observar quando falsos positivos são custosos. Em um sistema antifraude, por exemplo, um falso positivo pode bloquear uma compra legítima. Em um sistema de seleção automatizada, um falso positivo pode aprovar indevidamente um candidato que não deveria ser aprovado. Assim, a precisão deve ser priorizada quando o custo do falso positivo é alto no contexto da aplicação.
Recall
O recall (também chamado de sensibilidade ou revocação), mede, entre todos os positivos reais, quantos foram corretamente identificados. A métrica busca resposta para a pergunta: “entre todos os casos positivos existentes, quantos o modelo conseguiu encontrar?”.
O recall é encontrado por meio da equação:
O recall é essencial quando falsos negativos são perigosos. Em triagens médicas, por exemplo, deixar de detectar um caso suspeito pode ter consequência grave. Em segurança da informação, deixar de detectar uma tentativa real de invasão pode ser mais prejudicial do que gerar alguns alertas falsos. Portanto, o recall deve ser priorizado quando o custo do falso negativo é alto no cenário do problema.
F1-Score
Quando a pessoa que toma as decisões deseja equilibrar precisão e recall, este método de avaliação é bem útil. O F1-Score é a média harmônica entre precisão e recall, dada pela equação:
Conforme o cálculo do F1-score, observamos que ela penaliza valores muito baixos. Portanto, um modelo só terá F1-Score alto se tiver simultaneamente boa precisão e bom recall. Dessa forma, o F1-Score é útil quando se busca um compromisso entre ambos.
Curva ROC e AUC
A Curva ROC (sigla para Receiver Operating Characteristic) é um gráfico de probabilidade que ilustra o desempenho de um modelo de classificação em todos os limiares (thresholds) de decisão. Nele são plotadas duas métricas:
- Eixo Y (Sensibilidade / Taxa de Verdadeiros Positivos): proporção de casos positivos que o modelo previu corretamente.
- Eixo X (Taxa de Falsos Positivos): proporção de casos negativos que o modelo previu incorretamente como positivos.
O eixo Y é construído com a taxa de verdadeiros positivos (TPR), sendo que ele é o próprio recall, dado pela equação:
O outro eixo do gráfico, o eixo X, é montado com a taxa de falsos positivos (FPR), dada por:
Variando o ponto de corte do modelo (de 0 a 1), a curva se forma. Quanto mais próxima a curva estiver do canto superior esquerdo, melhor o modelo, pois ele acerta muitos positivos e erra poucos negativos (vide a Figura 3).
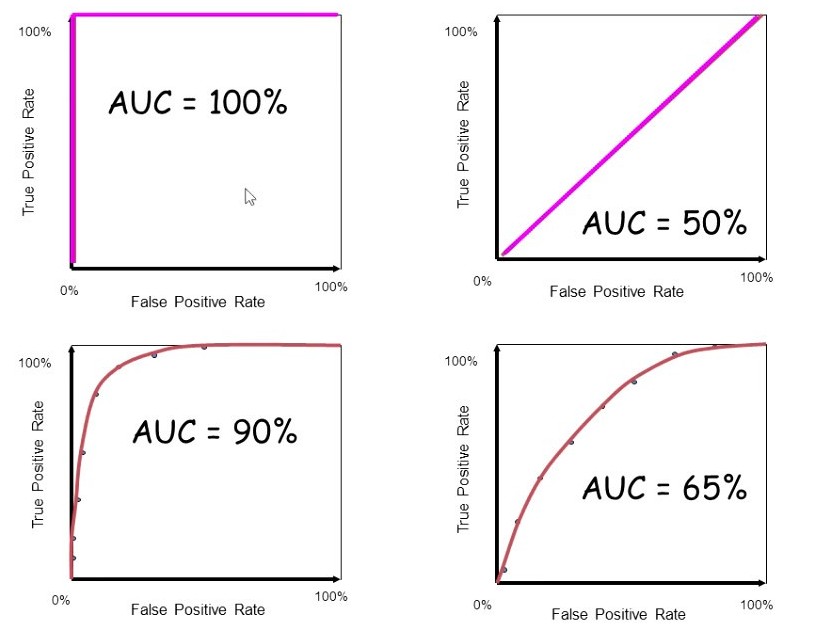
Fonte: Retirado de https://www.youtube.com/watch?v=MLq5xWNq-T8
Enquanto a curva ROC é um gráfico, a AUC (sigla para Área Sob a Curva) é um valor escalar único que resume a Curva ROC, representando a área abaixo dessa curva. Ela varia de 0 a 1 e indica a probabilidade de o modelo atribuir uma pontuação maior a um exemplo positivo escolhido aleatoriamente do que a um exemplo negativo.
A métrica AUC ajuda a entender a capacidade geral de separação entre as classes, independentemente de um único limiar de decisão. Ou seja, ela mede a capacidade do modelo de separar as classes. Quando obtemos uma AUC próxima de 1, temos indicação forte da capacidade discriminatória do modelo. Por outro lado, uma AUC próxima de 0,5 indica desempenho semelhante ao acaso.
A grande vantagem da AUC é que ela avalia o modelo considerando vários limiares de decisão, não apenas o limiar padrão de 0,5. Isso é útil quando o analista precisa ajustar o ponto de corte de acordo com o custo dos erros.
Exemplo prático em Python
Nesta seção será apresentado um exemplo de algoritmo em linguagem Python que faz uso da biblioteca Scikit-Learn. No exemplo vamos usar o conjunto de dados Breast Cancer Wisconsin, que está disponível na própria biblioteca. Trata-se de um conjunto clássico de classificação binária, com 569 amostras, 30 atributos numéricos e duas classes: maligno e benigno, conforme a documentação oficial (Scikit-Learn, 2026).
Importando as bibliotecas
Vamos começar importando as bibliotecas necessárias. Utilizaremos o numpy para as operações numéricas, especialmente para calcular a exponencial dos coeficientes ao obter o odds ratio. Em seguida, importamos o pandas para organizar os coeficientes em formato tabular que facilitará nossa análise posterior. Do biblioteca scikit-learn estamos importando as funções para carregar dados, separar os conjuntos de treino e teste, padronizar atributos, treinar o modelo e avaliar os resultados.
Além das dependências anteriores, buscamos também a classe LogisticRegression do Scikit-Learn, que implementa a regressão logística regularizada e permite diferentes versões de otimização. A documentação oficial informa que a regularização é aplicada por padrão, o que ajuda a reduzir o problema de overfitting (ou sobreajuste) em muitos cenários práticos (Scikit-Learn, 2026).
Como os atributos do conjunto possuem escalas diferentes, será usado o StandardScaler, que centraliza e escala cada atributo usando média e desvio padrão calculados no conjunto de treino. A fase de padronização é frequentemente necessária em cenários onde estimadores de aprendizado de máquina precisam lidar com escalas variadas no conjunto de entrada (e este é um desses casos).
# ---------------------------------------------------------
# Importando as bibliotecas necessárias
# ---------------------------------------------------------
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import (
confusion_matrix,
classification_report,
accuracy_score,
precision_score,
recall_score,
f1_score,
roc_auc_score
)Finalizamos as importações de dependências buscando os métodos que vão calcular as métricas de avaliação comuns para algoritmos de regressão logística.
Carregando a base de dados
Seguindo a construção do algoritmo, carregamos o dataset com a função load_breast_cancer(as_frame=True. Essa linha vai retornar o conjunto de dados de câncer de mama em formato compatível com pandas. O parâmetro as_frame=True faz com que os dados sejam retornados como estruturas tabulares (que é o DataFrame), facilitando a visualização e a manipulação.
Depois, criamos a variável X para receber os atributos de entrada (data) e a variável y para receber a variável-alvo (target). Nesse conjunto, a tarefa é binária: classificar observações em uma das duas classes disponíveis.
# ---------------------------------------------------------
# Carregando o conjunto de dados
# ---------------------------------------------------------
dados_cancer = load_breast_cancer(as_frame=True)
X = dados_cancer.data
y = dados_cancer.target
print("Classes do problema:")
print(dados_cancer.target_names)
print("\nDimensões dos atributos:")
print(X.shape)
print("\nPrimeiras linhas dos dados:")
print(X.head())Apenas para fins de observação, estamos imprimindo na tela quais são as classes do dataset, as dimensões do conjunto de entrada ( x ) e as primeiras linhas dele.
Separando os conjuntos de treino e teste
Chegou a hora de separarmos o que usaremos para treinar o modelo e o que usaremos para testá-lo. A função train_test_split separa os dados em treino e teste, sendo que declaramos o parâmetro test_size=0.25 para reservar 25% das observações para teste.
O parâmetro random_state=42 fixa a semente aleatória para que a divisão possa ser reproduzida, enquanto o parâmetro stratify=y preserva aproximadamente a proporção das classes nos conjuntos de treino e teste, o que é importante em problemas de classificação. Isso tem muito a ver com a ideia da amostragem estratificada que existe na Estatística.
# ---------------------------------------------------------
# Separando dados de treino e teste
# ---------------------------------------------------------
X_treino, X_teste, y_treino, y_teste = train_test_split(
X,
y,
test_size=0.25,
random_state=42,
stratify=y
)Padronizando os atributos de entrada
Com os conjuntos separados e atribuídos às suas variáveis, chamamos a classe StandardScaler para padronizar os atributos. Esse processo ocorre por meio da função fit_transform que calcula a média e o desvio padrão no conjunto de treino e já aplica a transformação nesse mesmo conjunto.
Para evitar possíveis vazamento de dados, a função transform aplica ao conjunto de teste a mesma padronização aprendida no treino (são nomes parecidos, mas não são o mesmo método). Esse cuidado é importante para que informações do conjunto de teste não influenciem o treinamento (o problema de vazamento de dados).
# ---------------------------------------------------------
# Padronizando os atributos
# ---------------------------------------------------------
padronizador = StandardScaler()
X_treino_padronizado = padronizador.fit_transform(X_treino)
X_teste_padronizado = padronizador.transform(X_teste)Treinando o modelo
Este é o momento para criarmos o modelo LogisticRegression. O retorno da classe construtora será colocado no objeto modelo.
Para a criação do objeto definimos o parâmetro max_iter=1000 para aumentar o número máximo de iterações do algoritmo de otimização, reduzindo o risco de interrupção antes da convergência. Já o parâmetro solver="lbfgs" define o algoritmo de otimização usado internamente.
Depois, atribuímos ao objeto modelo o retorno do método fit(), que recebe os atributos de treino padronizados e os rótulos de treino, ajustando os coeficientes do modelo.
# ---------------------------------------------------------
# Criando e treinando o modelo de regressão logística
# ---------------------------------------------------------
modelo = LogisticRegression(
max_iter=1000,
solver="lbfgs",
random_state=42
)
modelo.fit(X_treino_padronizado, y_treino)Testando o modelo
Após o treinamento, o modelo aprendeu e ajustou exaustivamente os coeficientes para a equação que descrevemos na seção Otimização do treinamento.
Agora, vamos aplicar a função predict() conforme abaixo para produzir as classes previstas pelo modelo, normalmente a partir de um limiar de decisão de 0,5. Já a função predict_proba() vai retornar as probabilidades estimadas para cada uma.
# ---------------------------------------------------------
# Realizando previsões
# ---------------------------------------------------------
y_previsto = modelo.predict(X_teste_padronizado)
probabilidades = modelo.predict_proba(X_teste_padronizado)
probabilidade_classe_positiva = probabilidades[:, 1]Como este é um problema binário, buscamos também selecionar a probabilidade da classe positiva por meio do comando probabilidades[:, 1]. Fizemos este passo porque o valor da probabilidade da classe positiva é necessário para o cálculo da AUC.
Avaliando o modelo
Chegamos à etapa onde calculamos as métricas de avaliação do modelo. Basicamente, estamos obtendo os resultados das seguintes métricas:
confusion_matrixretorna a matriz de confusão.accuracy_scorecalcula a acurácia.precision_scorecalcula a precisão.recall_scorecalcula o recall.f1_scorecalcula a média harmônica entre precisão e recall.roc_auc_scorecalcula a área sob a curva ROC a partir das probabilidades previstas (oscikit-learndefine essa função como o cálculo da área sob a curva ROC usando escores de predição).
Essa lógica busca implementar a interpretação alinhada à tradição estatística da regressão logística descrita por Agresti (2013) e Hosmer, Lemeshow e Sturdivant (2013).
# ---------------------------------------------------------
# Avaliando o desempenho do modelo
# ---------------------------------------------------------
matriz = confusion_matrix(y_teste, y_previsto)
acuracia = accuracy_score(y_teste, y_previsto)
precisao = precision_score(y_teste, y_previsto)
revocacao = recall_score(y_teste, y_previsto)
f1 = f1_score(y_teste, y_previsto)
auc = roc_auc_score(y_teste, probabilidade_classe_positiva)
print("\nMatriz de Confusão:")
print(matriz)
print("\nMétricas principais:")
print(f"Acurácia: {acuracia:.4f}")
print(f"Precisão: {precisao:.4f}")
print(f"Recall: {revocacao:.4f}")
print(f"F1-Score: {f1:.4f}")
print(f"AUC: {auc:.4f}")
print("\nRelatório de classificação:")
print(classification_report(y_teste, y_previsto, target_names=dados_cancer.target_names))O primeiro resultado que mandamos o algoritmo apresentar foi a matriz de confusão. No Scikit-Learn, para classificação binária, a matriz costuma seguir a estrutura abaixo, retornando os valores:
Os valores obtidos foram posicionados como VN, FP etc. porque no dataset load_breast_cancer a classe 0 representa malignant e a classe 1 representa benign. Como o Scikit-Learn organiza a matriz por ordem dos rótulos [0, 1], ela deve ser lida assim:
Previsto
malignant benign
Real malignant 52 1
Real benign 1 89Consequentemente, os valores significam:
52 = casos malignos classificados como malignos
01 = casos malignos classificados como benignos
01 = casos benignos classificados como malignos
89 = casos benignos classificados como benignosAgora vem um detalhe importante nesta discussão: os nomes VP, VN, FP e FN dependem de qual classe você escolhe como positiva. Se a classe positiva for benign, como ocorre por padrão nas métricas binárias do Scikit-Learn porque benign = 1, então temos que:
VN = 52 -> malignant previsto como malignant
FP = 01 -> malignant previsto como benign
FN = 01 -> benign previsto como malignant
VP = 89 -> benign previsto como benignNesse caso, o rótulo “negativo” ficou com a classe malignant, porque malignant = 0 no scikit-learn. Este cuidado que precisamos tomar aqui é porque como malignant = 0 e benign = 1, as métricas precision_score, recall_score e f1_score consideraram por padrão benign como classe positiva. Para avaliarmos malignant como positivo, teríamos que alterar o código explicitamente conforme a seguir:
# Este código não foi feito anteriormente, é apenas um exemplo. Desconsidere-o para as análises
precision_score(y_teste, y_previsto, pos_label=0)
recall_score(y_teste, y_previsto, pos_label=0)
f1_score(y_teste, y_previsto, pos_label=0)Observando este detalhe de implementação do scikit-learn, podemos dizer que a explicação mais adequada para a matriz de confusão neste exemplo seria:
O modelo classificou corretamente 52 casos malignos como malignos e errou 1 caso maligno, classificando-o como benigno. Além disso, também classificou corretamente 89 casos benignos como benignos e errou 1 caso benigno, classificando-o como maligno.Depois, imprimimos a acurácia, que foi . Isso significa que o modelo acertou aproximadamente 98,60% das classificações. Na prática, dos 143 exemplos de teste, o modelo errou apenas 2, sendo um desempenho muito alto. Claro que devemos sempre ponderar que o dataset está bem construído e organizado.
O percentual foi obtido a partir das 143 amostras no teste e do cálculo a seguir:
A acurácia é boa neste caso, mas ela deve ser analisada com cuidado. Em problemas desbalanceados, a acurácia pode enganar. Por exemplo, se 99% dos casos fossem benignos, um modelo que sempre dissesse “benigno” teria alta acurácia, mas seria péssimo para detectar câncer maligno.
Por isso, autores como James et al. (2021) recomendam olhar outras métricas além da taxa geral de acerto em problemas de classificação. Neste caso específico, a acurácia é confiável porque as demais métricas também estão altas.
A terceira métrica foi a precisão. Ela responde à pergunta: quando o modelo prevê a classe positiva, quantas vezes ele acerta? Em nosso código, a classe positiva considerada é 1, ou seja, a classe “benign“. Portanto, essa precisão indica que, quando o modelo disse que um tumor era benigno, ele estava correto em aproximadamente 98,89% das vezes ().
Esse valor de precisão é bom, porém, em diagnóstico médico, é preciso atenção: um falso benigno é grave, porque significa classificar como benigno um caso que era maligno. Esse erro aparece como aquele “1” na primeira linha da matriz, pois houve 1 caso maligno previsto como benigno. Portanto, é importante sempre considerarmos o contexto do problema.
A métrica seguinte foi o recall, que busca responder à pergunta: entre todos os casos realmente positivos, quantos o modelo conseguiu encontrar? Como a classe positiva é benign, o recall mede quantos casos benignos reais foram corretamente identificados como benignos. Neste caso:
Este também é um valor muito bom. Mas, novamente, em um problema médico, talvez a métrica mais sensível seja o recall da classe malignant, porque o erro mais perigoso é deixar de identificar um tumor maligno.
No relatório, a classe malignant teve . Isso significa que o modelo identificou corretamente cerca de 98% dos casos malignos. Como havia 53 casos malignos, ele detectou 52 e errou 1.
A quinta métrica impressa foi o F1-Score, que combina precisão e recall em uma única avaliação, conforme equação abaixo:
Como a precisão e o recall foram iguais, o F1 também ficou igual (). Esse valor é um resultado excelente para o método avaliativo, haja vista que o F1-Score é especialmente útil quando queremos equilíbrio entre falsos positivos e falsos negativos. Segundo Géron (2022), devemos sempre considerar o F1-Score como uma métrica importante em problemas nos quais o custo dos erros precisa ser analisado com mais cuidado.
A última métrica de avaliação do modelo que imprimimos foi a AUC. Ela mede a capacidade do modelo de separar as classes em diferentes limiares de decisão (lembrando que um valor de 0,5 indica desempenho semelhante ao acaso). Quando o valor é próximo de 1, há inficação de excelente separação entre as classes. Neste caso, como obtivemos , temos que .
Isso sugere que o modelo quase sempre atribui probabilidades maiores para a classe correta em comparação com a classe incorreta. Em outras palavras, ele não está apenas acertando bem com o limiar padrão de 0,5; ele também está ordenando muito bem os exemplos em termos de risco/probabilidade. Inclusive, talvez este seja o melhor indicador global da saída apresentada por todas as métricas que obtivemos na execução do algoritmo.
Quase finalizando nossas análises, pedimos ao algoritmo para imprimir o relatório de classificação, cujo resultado foi:
precision recall f1-score support
malignant 0.98 0.98 0.98 53
benign 0.99 0.99 0.99 90
accuracy 0.99 143
macro avg 0.99 0.99 0.99 143
weighted avg 0.99 0.99 0.99 143A coluna support mostra quantos exemplos reais havia de cada classe no conjunto de teste. Ou seja, havia 53 tumores malignos e 90 benignos, indicando algum desbalanceamento, mas não extremo, na base. Apesar da classe benigna ser maior, a classe maligna ainda tem quantidade suficiente para avaliação inicial.
A classe malignant teve precisão (precision), recall e F1-score de aproximadamente 0,98, enquanto a classe benign teve valores próximos de 0,99. Isso mostrou que o modelo foi bom nas duas classes, e não apenas na classe majoritária. Bom sinal para nós!
Além disso, ainda temos o retorno dos valores da macro avg – que calcula a média simples entre as classes – e da weighted avg – que calcula a média ponderada pelo tamanho de cada classe. Como ambas ficaram próximas de 0,99, temos que o desempenho do algoritmo está equilibrado.
Interpretando os coeficientes do modelo
Dados os valores das métricas após o teste, vamos agora tentar entender o que o modelo encontrou como coeficientes. A primeira coisa que fizemos foi organizar em um DataFrame os coeficientes aprendidos pelo modelo. A coluna coeficiente vai mostrar o efeito de cada atributo sobre o logit e a coluna odds_ratio aplica o comando np.exp() aos coeficientes para obtermos a interpretação dos efeitos em termos de multiplicação das chances.
Em seguida, ordenamos os coeficientes do DataFrame para facilitar a impressão dos 5 maiores valores (head) e dos 5 menores (tail) coeficientes encontrados pelo modelo.
# ---------------------------------------------------------
# Interpretando os coeficientes do modelo
# ---------------------------------------------------------
coeficientes = pd.DataFrame({
"atributo": X.columns,
"coeficiente": modelo.coef_[0],
"odds_ratio": np.exp(modelo.coef_[0])
})
coeficientes_ordenados = coeficientes.sort_values(
by="coeficiente",
ascending=False
)
print("\nCoeficientes mais positivos:")
print(coeficientes_ordenados.head())
print("\nCoeficientes mais negativos:")
print(coeficientes_ordenados.tail())Os coeficientes mostram como cada atributo influencia o logit da classe positiva. Portanto, como a classe positiva é benign, coeficientes positivos aumentam a chance de o modelo prever benign. Coeficientes negativos aumentam a tendência contrária, ou seja, reduzem a chance de benign e favorecem a classificação como malignant.
Por exemplo, na saída do algoritmo enocntramos a seguinte linha:
mean compactness coeficiente = 0.694230 odds_ratio = 2.002167Isso significa que, mantendo os demais atributos constantes, o aumento de uma unidade padronizada em mean compactness multiplica as chances da classe positiva por aproximadamente 2. Como a classe positiva é benign, esse atributo, nesse modelo ajustado, está associado a maior chance de classificação como benigno.
Já este atributo descrito na linha abaixo:
worst texture coeficiente = -1.250149 odds_ratio = 0.286462tem coeficiente negativo, indicando que o aumento de uma unidade padronizada em worst texture reduz as chances da classe positiva para cerca de 0,286 do valor anterior. Em termos práticos, ele empurra a decisão para longe de benign e mais perto de malignant.
A interpretação pelo Odds Ratio segue a tradição estatística da regressão logística, onde indica o fator multiplicativo nas chances do evento associado à classe positiva, mantendo os demais preditores constantes (Agresti, 2013; Hosmer; Lemeshow; Sturdivant, 2013).
Como definir se esses valores são bons?
Essa é uma pergunta muito comum por parte dos alunos. Considerando o exemplo que demonstramos neste artigo, os resultados são excelentes para o conjunto de teste. O modelo teve apenas 2 erros em 143 exemplos; a acurácia foi 98,60%; a precisão, recall e F1 ficaram próximos de 99%; e a AUC foi 0,9977, indicando separação quase perfeita entre as classes. Porém, a conclusão técnica mais correta aqui seria: o modelo apresentou desempenho muito alto no conjunto de teste utilizado, mas sua qualidade real deve ser confirmada com validação cruzada, análise de dados externos, inspeção dos falsos negativos e avaliação do custo dos erros.
Caso esteja encarando uma situação de regressão logística, você pode definir se seus valores são bons comparando as métricas com quatro critérios:
- Primeiro, compare com um modelo ingênuo. Se a maioria dos casos fosse benigna, um classificador que sempre previsse
benignjá teria uma acurácia razoável. O seu modelo precisa superar esse baseline. Aqui, ele supera com folga porque também acerta muito bem a classemalignant. - Segundo, analise o custo dos erros. Em diagnóstico médico, falso negativo para malignidade é muito grave. Neste caso, houve 1 caso maligno classificado como benigno. Mesmo com métrica alta, esse erro merece atenção, porque pode ter custo clínico elevado. Em um sistema real, talvez fosse melhor ajustar o limiar para reduzir falsos benignos, mesmo que isso aumentasse falsos alertas.
- Terceiro, observe o equilíbrio entre as classes. Aqui, a classe
malignanttem 53 exemplos e a classebenigntem 90. Não é perfeitamente balanceado, mas também não é um desequilíbrio severo. Como as métricas por classe ficaram altas, o modelo parece equilibrado. - Quarto, valide fora dessa amostra. Um único conjunto de teste pode produzir uma estimativa otimista ou pessimista. O ideal é usar validação cruzada, testar em dados coletados em outro período ou em outra fonte e verificar se as métricas continuam altas. Esse cuidado é importante porque bons resultados em teste controlado não garantem desempenho equivalente em produção.
Apesar de não ser uma obrigação, recomendamos a adoção destes critérios para uma avaliação mais completa em termos de produção mercadológica ou científica de uma aplicação. Eles podem lhe ajudar a compreender melhor seus resultados e apresentar boas discussões acerca deles.
Conclusão
A regressão logística é uma técnica básica para analistas de sistemas, cientistas de dados e engenheiros de software que trabalham com classificação binária. Seu valor está em combinar simplicidade matemática, interpretação estatística e aplicação prática em sistemas reais.
Para o analista de sistemas, dominar regressão logística significa compreender como um software pode transformar dados em decisões probabilísticas. Isso é importante em sistemas de recomendação, análise de risco, previsão de evasão, detecção de fraude, priorização de atendimento, diagnóstico assistido e automação de decisões.
A técnica também demonstra que nem todo problema preditivo deve ser tratado como regressão linear. Quando a saída representa uma classe, especialmente uma classe binária, é necessário modelar probabilidades, interpretar incertezas e avaliar erros de maneira compatível com o contexto do problema. E a regressão logística oferece exatamente essa ponte entre estatística, aprendizado de máquina e tomada de decisão computacional.
Obrigado pela leitura e bons estudos!
Referências
AGRESTI, Alan. Categorical Data Analysis. 3. ed. Hoboken: Wiley, 2013.
GOODFELLOW, Ian; BENGIO, Yoshua; COURVILLE, Aaron. Deep Learning. Cambridge: MIT Press, 2016.
HOSMER, David W.; LEMESHOW, Stanley; STURDIVANT, Rodney X. Applied Logistic Regression. 3. ed. Hoboken: Wiley, 2013.
JAMES, Gareth; WITTEN, Daniela; HASTIE, Trevor; TIBSHIRANI, Robert. An Introduction to Statistical Learning: with Applications in R. 2. ed. New York: Springer, 2021.
SCIKIT-LEARN. Supervised Learning Guide. Disponível em: <https://scikit-learn.org/stable/supervised_learning.html>. Acesso em: 23 mai. 2026.