Intervalos de Confiança para médias e proporções
Na prática da Engenharia e da Estatística, raramente conhecemos os parâmetros reais de uma população (como a média populacional ou a variância , por exemplo). O que possuímos na realidade são os dados amostrais. Contudo, as amostras não representam a população de forma completa (obviamente, né?). Sendo assim, o Intervalo de Confiança (IC) surge como uma ferramenta para expressar a incerteza inerente a essa estimativa pontual das amostras.
O que é o Intervalo de Confiança?
Em Estatística, um intervalo de confiança é uma faixa de valores numéricos calculada a partir de uma amostra com o objetivo de estimar um parâmetro desconhecido de uma população. Em outras palavras, podemos dizer que um Intervalo de Confiança é um intervalo que tem uma probabilidade específica (chamada de nível de confiança) de conter o valor real do parâmetro populacional desconhecido.
A ideia central é simples: como geralmente não conseguimos observar toda a população, usamos uma amostra. Porém, toda amostra possui variabilidade. O intervalo de confiança tenta expressar essa incerteza de maneira quantitativa. Diferente de uma estimativa pontual, a estimativa intervalar admite o erro.
Por exemplo, em vez de dizer:
“O tempo médio de resposta da API é 220 ms.”
Podemos dizer:
“Com 95% de confiança, o tempo médio de resposta da API está entre 205 ms e 235 ms.”
A segunda afirmação é mais honesta estatisticamente, pois reconhece que a estimativa vem de uma amostra e, portanto, está sujeita a erro amostral. Essa ideia é central na inferência estatística, como discutem Montgomery e Runger (2012) e Morettin e Bussab (2017).
A formulação moderna do IC foi introduzida por Jerzy Neyman em 1937. Segundo Neyman (1937), o termo “confiança” não se refere à probabilidade de o parâmetro estar no intervalo após o cálculo, mas sim ao desempenho do procedimento estatístico em múltiplas repetições do experimento sob as mesmas condições.
Por que intervalos de confiança são importantes?
Intervalos de confiança são importantes porque evitam que decisões sejam tomadas com base em um único número aparentemente preciso, mas possivelmente enganoso.
Em desenvolvimento de sistemas e ciência de dados, isso é importante em cenários que exigem tomada de decisão. Imagine que uma equipe compara duas versões de uma funcionalidade. A versão 1 tem conversão média de 12,1%, enquanto a versão 2 tem conversão média de 12,8%. A versão 2 parece melhor (média maior), mas essa diferença pode ser apenas ruído amostral.
Com a ajuda dos intervalos, podemos buscar respostas para perguntas como:
A nova versão realmente melhorou a conversão?
A latência média da API está dentro do limite aceitável?
O modelo de machine learning tem desempenho estável ou a métrica observada depende demais da amostra de teste?
A taxa de falhas aumentou de forma relevante ou apenas flutuou naturalmente?
Portanto, intervalos de confiança ajudam a transformar dados em decisões mais robustas. Eles não eliminam a incerteza, mas tornam ela explícita.
Características fundamentais
Conforme Bussab e Morettin (2017), para que um intervalo de confiança seja considerado robusto, ele depende de três componentes principais:
- Estimativa Pontual: o valor central obtido da amostra (ex: média amostral ).
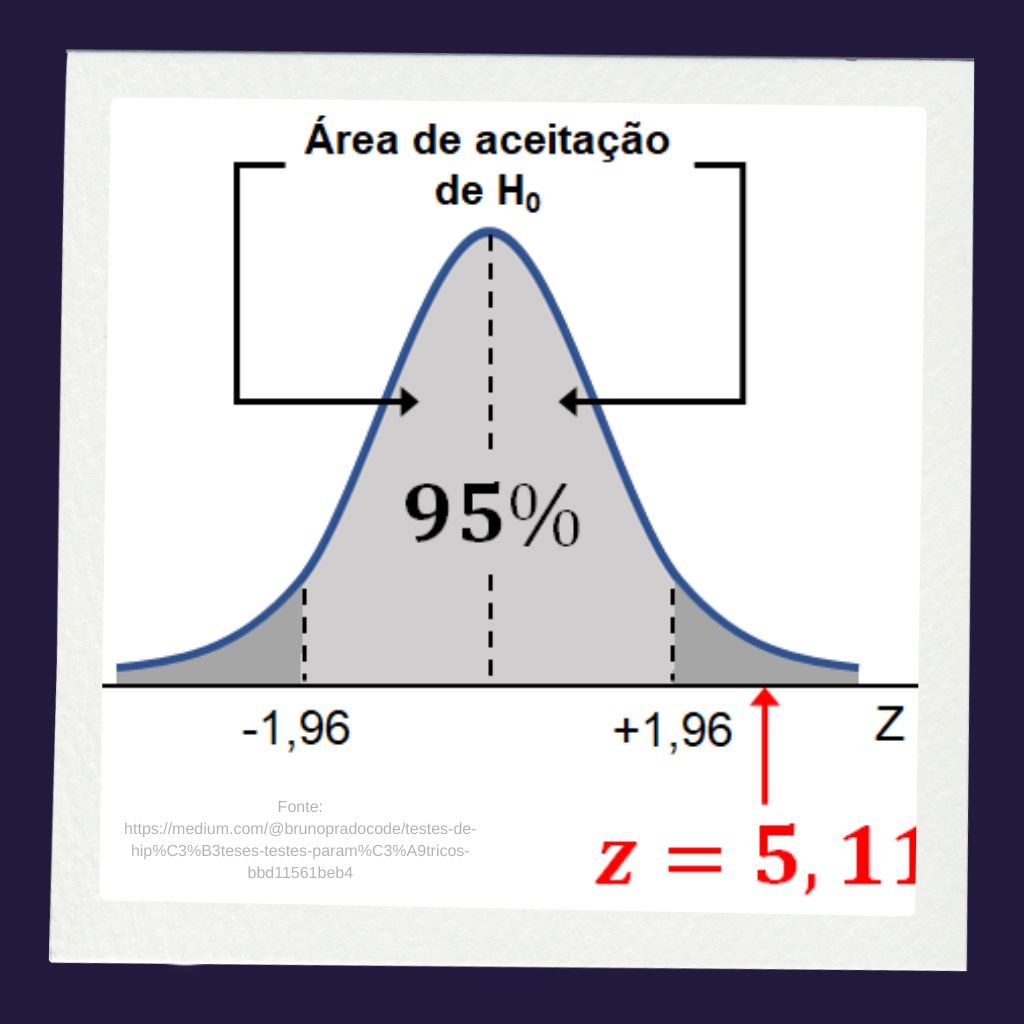
- Nível de Confiança (): a probabilidade de que o método de construção do intervalo capture o parâmetro real. Os valores comuns são 90%, 95% e 99%.
- Margem de Erro ( ): a medida de precisão do intervalo, que depende do desvio padrão e do tamanho da amostra.
De forma geral, um intervalo de confiança pode ser representado por:
sendo que a margem de erro depende do nível de confiança, da variabilidade da amostra e do tamanho da amostra.
Para a média populacional, uma formulação comum é:
Onde:
- é a média amostral (a estimativa).
- é o valor crítico da distribuição normal padrão.
- é o desvio padrão populacional.
- é o tamanho da amostra.
Na prática, quase nunca conhecemos o desvio padrão populacional. Por isso, usamos o desvio padrão amostral ( s ) e a distribuição t de Student:
Essa versão é mais comum em aplicações reais, especialmente quando trabalhamos com amostras pequenas ou quando o desvio padrão populacional é desconhecido.
A interpretação correta do resultado obtido com ICs
Conforme discutido exaustivamente por Moore, Notz e Fligner (2017), ao utilizarmos essa técnica estatística, não devemos cair no erro comum de dizer: “Existe uma probabilidade de 95% de o parâmetro estar dentro deste intervalo específico”. Essa questão é frequentemente mal compreendida.
Um intervalo de confiança de 95% não significa que existe 95% de probabilidade de o parâmetro verdadeiro estar dentro daquele intervalo específico calculado. Na abordagem frequentista clássica, o parâmetro populacional é fixo; quem varia é o intervalo, pois ele depende da amostra. Uma vez que o intervalo foi calculado com dados fixos, o parâmetro está lá dentro ou não está (probabilidade 0 ou 1).
A interpretação correta, alinhada à escola frequentista defendida por Moore, Notz e Fligner (2017), é:
Se repetíssemos o processo de amostragem muitas vezes e construíssemos um intervalo de confiança de 95% para cada amostra, espera-se que aproximadamente 95% desses intervalos conteriam o verdadeiro parâmetro populacional.
Essa interpretação é importante porque evita uma leitura subjetiva equivocada do intervalo. A distinção entre parâmetro fixo e amostra aleatória é uma base da inferência estatística frequentista, como apresentado por Casella e Berger (2002).
Exemplo 01: intervalo para a latência média de um banco de dados
Imagine que você está monitorando a latência de um banco de dados. Você coletou uma amostra de 100 consultas (n = 100) e obteve uma média de 50ms com um desvio padrão populacional conhecido de 10ms. Calcule o Intervalo de Confiança de 95% para a média de latência ().
O objetivo é estimar a latência média () de um banco de dados com base numa amostra. Os dados que temos à disposição a partir do enunciado são:
- Média amostral (): 50ms
- Desvio padrão populacional (): 10ms (variância conhecida)
- Tamanho da amostra (): 100
- Nível de confiança: 95% ()
- Valor crítico (): 1,96 (valor padrão para 95% de confiança)
A fórmula do Intervalo de Confiança para a média com conhecido é:
Substituindo os valores que temos na equação, obteremos:
- Cálculo do erro padrão da média ():
- Cálculo da margem de erro ( ):
- Aplicando à média:
Resultado: O Intervalo de Confiança de 95% é [48,04ms; 51,96ms]. A interpretação deste resultado é que estamos 95% confiantes de que o método utilizado capturou a média real de latência da população, e que ela se situa entre 48,04ms e 51,96ms.
Aprimorando o exemplo
Agora, se precisássemos que a margem de erro fosse de apenas 1 ms (mantendo os 95% de confiança), qual deveria ser o novo tamanho da amostra ? Vamos descobrir.
Para reduzir a margem de erro ( ) para apenas 1ms mantendo a confiança de 95%, isolamos na fórmula da margem de erro:
Substituindo os valores:
Como o tamanho da amostra deve ser um número inteiro, arredondamos sempre para cima para garantir a precisão mínima desejada. Logo, para a nova situação que buscamos analisar.
E o que isso nos diz sobre a viabilidade de sistemas de alta precisão? Bom, este simplório exemplo nos dá três coisas para se pensar:
- A Lei dos Rendimentos Decrescentes: note que para reduzir a margem de erro de 1,96ms para 1ms (uma redução de aproximadamente 49%), precisamos aumentar a amostra de 100 para 385 (um aumento de quase 400%). Isso demonstra que a precisão não escala linearmente com os dados; ela escala com o quadrado da redução desejada.
- Custo de Observabilidade: em sistemas de Big Data, quadruplicar a coleta de dados para ganhar metade da precisão pode significar custos proibitivos de armazenamento, processamento de rede e CPU.
- Trade-off para uma pesquisa ou um negócio: em muitos casos, uma precisão de 2 ms (com n = 100) é suficiente para decisões de negócio ou de pesquisa. A busca pela “precisão perfeita” pode ser um erro de engenharia se o custo de obtenção dessa precisão superar o benefício da informação.
Exemplo 02: intervalo de confiança para o tempo médio de resposta de uma API
Imagine que façamos parte de uma equipe de engenharia que está buscando medir o tempo de resposta de uma API em milissegundos. Dentro dos testes, nossa equipe coletou 30 requisições da aplicação e agora queremos estimar o tempo médio real de resposta da API com 95% de confiança.
Os 30 tempos de resposta coletados, em milissegundos, foram:
[210, 215, 198, 220, 205, 230, 225, 218, 212, 207, 216, 219, 221, 214, 208, 226, 232, 211, 209, 217, 223, 228, 206, 213, 224, 229, 231, 202, 199, 216]
Porém, nossa equipe de engenharia não conhece o desvio populacional de todas as respostas possíveis da API. Sendo assim, mesmo com n = 30, será adotada a distribuição t de student e a equação da seguinte maneira:
Vamos construir a equação de IC aos poucos, mas, apesar de precisarmos de várias estimativas descritivas, não vamos demonstrar os cálculos passo a passo neste artigo. Deixaremos os valores aproximados abaixo:
- Média amostral:
- Variância amostral:
- Desvio padrão amostral:
Pronto. Agora mostraremos a construção dos cálculos a partir do erro padrão, pois tem relação com o conteúdo deste artigo. O erro padrão é uma parte da equação completa de IC, descrita e desenvolvida como:
Continuando, para obtermos o valor crítico para um intervalo de confiança de 95%, precisamos definir o alfa ( ) e o grau de liberdade das observações independentes1. Com as 30 requisições observadas, o grau de liberdade é: . Segundo a formulação matemática, obtemos o valor de da seguinte forma:
Como o intervalo é bilateral:
Com 29 graus de liberdade, buscamos o valor crítico ( ) na tabela padronizada que existe para a distribuição t de student. Para encontrar essa tabela, clique aqui. Com base nela, temos que:
Agora que temos o valor crítico (neste caso, ) e o erro padrão (), podemos obter a margem de erro, conforme a seguir:
Finalmente, para construirmos o intervalo de confiança completo, temos que:
Considerando a média amostral mais ou menos a margem de erro anterior, temos que o limite inferior é , enquanto o limite superior é . Portanto, o intervalo de confiança de 95% que encontramos é igual a:
Logo, podemos dizer com 95% de confiança de que o método aplicado é capaz de capturar a média populacional e estimamos que o tempo médio real de resposta da API esteja entre e .
Aprimorando o exemplo, dessa vez via código
Como este é um site voltado aos profissionais de TI, eu não poderia deixar de representar este exemplo de forma computacional. A seguir, temos a mesma lógica aplicada ao exemplo codificada em linguagem Python, para averiguarmos a validade dos nossos cálculos e resultados.
import numpy as np
from scipy import stats
tempos_resposta = np.array([
210, 215, 198, 220, 205, 230, 225, 218, 212, 207,
216, 219, 221, 214, 208, 226, 232, 211, 209, 217,
223, 228, 206, 213, 224, 229, 231, 202, 199, 216
])
n = len(tempos_resposta)
media = np.mean(tempos_resposta)
desvio_padrao = np.std(tempos_resposta, ddof=1)
nivel_confianca = 0.95
graus_liberdade = n - 1
erro_padrao = desvio_padrao / np.sqrt(n)
t_critico = stats.t.ppf((1 + nivel_confianca) / 2, graus_liberdade)
margem_erro = t_critico * erro_padrao
limite_inferior = media - margem_erro
limite_superior = media + margem_erro
print(f"n: {n}")
print(f"Média amostral: {media:.4f}")
print(f"Desvio padrão amostral: {desvio_padrao:.4f}")
print(f"Erro padrão: {erro_padrao:.4f}")
print(f"t crítico: {t_critico:.4f}")
print(f"Margem de erro: {margem_erro:.4f}")
print(f"IC 95%: [{limite_inferior:.4f}, {limite_superior:.4f}]")A saída do algoritmo acima deverá ser algo como demonstrado a seguir. Repare que os valores retornados pelo algoritmo refletem os valores que obtivemos nos cálculos apresentados, validando nossa lógica.
n: 30
Média amostral: 216.1333
Desvio padrão amostral: 9.5655
Erro padrão: 1.7464
t crítico: 2.0452
Margem de erro: 3.5718
IC 95%: [212.5615, 219.7052]Para uma equipe de desenvolvimento numa empresa, a técnica estatística de intervalos de confiança pode orientar decisões de performance. Por exemplo, se o requisito do sistema diz que a média deve ficar abaixo de 250 ms, o resultado sugere que a API está dentro do limite. Porém, se o limite fosse 215 ms, o intervalo indicaria incerteza suficiente para justificar novas medições ou otimizações.
Exemplo 03: intervalo de confiança para proporções
Os Exemplos 01 e 02 trabalharam apenas com a possibilidade de estimarmos a média populacional. Entretanto, nem sempre queremos estimar uma média. Muitas vezes, em sistemas digitais, queremos estimar uma proporção. Por exemplo:
- proporção de usuários que clicam em um botão;
- proporção de transações com erro;
- proporção de clientes que abandonam o carrinho;
- proporção de testes automatizados que falham;
- proporção de requisições que retornam status HTTP 500.
Repare que nos exemplos citados o intervalo de confiança (IC) para proporção é utilizado porque os dados são categóricos (nominais ou binários) e o objetivo é estimar a porcentagem ou fração de uma população que pertence a uma determinada categoria.
Para uma proporção amostral ( ), um intervalo aproximado pode ser calculado por:
Onde:
- é a proporção observada na amostra (a estimativa).
- é o valor crítico da distribuição normal padrão.
- é o tamanho da amostra.
O cenário do exemplo é o seguinte: suponha que, em 1.000 requisições a uma API, 37 delas retornaram erro. Ou seja, a proporção amostral de erro é:
Beleza! Nossa API obteve uma taxa de proporção de 3,7% de erro. Agora, vamos calcular um intervalo de confiança de 95% para essa proporção:
Obtendo os limites inferior (LI) e superior (LS), temos: e . Em nossa interpretação para este cenário podemos dizer que:
Com 95% de confiança, a taxa real de erro da aplicação foi capturada pelo método estatístico e está entre aproximadamente 2,53% e 4,87%.
Esse tipo de informação é útil para monitoramento de confiabilidade. Por exemplo, se a diretriz de conformidade da empresa determina que a taxa de erro deve ser menor que 5%, a estimativa parece aceitável, mas ainda próxima do limite superior. A decisão técnica poderia ser investigar logs, verificar gargalos e aumentar a amostragem para realizar outros testes e obter novos intervalos.
Aprimorando o exemplo, dessa vez via código
Transpondo a lógica que aplicamos para criar o intervalo de proporção, teremos um algoritmo como o abaixo:
import numpy as np
from scipy import stats
n = 1000
erros = 37
p_hat = erros / n
nivel_confianca = 0.95
z_critico = stats.norm.ppf((1 + nivel_confianca) / 2)
erro_padrao = np.sqrt((p_hat * (1 - p_hat)) / n)
margem_erro = z_critico * erro_padrao
limite_inferior = p_hat - margem_erro
limite_superior = p_hat + margem_erro
print(f"Taxa observada de erro: {p_hat * 100:.2f}%")
print(f"IC 95%: [{limite_inferior * 100:.2f}%, {limite_superior * 100:.2f}%]")O resultado esperado ao final do código será:
Taxa observada de erro: 3.70%
IC 95%: [2.53%, 4.87%]corroborando os valores que obtivemos no cálculo manual.
Atenção: intervalo de confiança não é garantia de verdade
Um erro comum quando trabalhamos com ICs é interpretá-lo como garantia absoluta, sendo que ele não é e nunca foi criado para ser.
É importante lembrarmos que um intervalo de confiança depende de pressupostos, entre os principais estão:
- a amostra deve ser representativa;
- as observações devem ser independentes, quando o método exigir isso;
- a distribuição assumida deve ser adequada ao problema;
- o tamanho da amostra deve ser suficiente para a aproximação usada.
Contudo, em sistemas reais, esses pressupostos podem falhar miseravelmente. Logs podem estar incompletos, usuários podem não ser independentes, amostras podem estar concentradas em determinados perfis e métricas podem ser afetadas por deploys ou incidentes. Por isso, intervalos de confiança devem ser lidos como ferramentas de apoio à decisão, não como verdades automáticas.
Trade-offs no uso de intervalos de confiança
Assim como tudo na vida, não existe “almoço grátis”. Triola (2017) enfatiza que, ao trabalharmos com ICs, enfrentamos dilemas e teremos que tomar decisões.
O primeiro trade-off envolve o nível de confiança. Um intervalo de 99% oferece maior confiança, mas será mais largo. Um intervalo de 90% será mais estreito, mas menos conservador. Em decisões críticas, como segurança, saúde, finanças ou infraestrutura essencial, níveis maiores podem ser desejáveis. Em decisões exploratórias, 90% ou 95% podem ser suficientes.
A escolha do nível de confiança impacta diretamente no segundo trade-off: precisão e custo. Para reduzir a largura do intervalo, geralmente precisamos de mais dados. Mas coletar mais dados pode custar tempo, dinheiro, processamento e armazenamento. Em um sistema de grande escala, isso pode impactar observabilidade, privacidade e custo operacional.
O terceiro trade-off envolve simplicidade matemática e realismo. Fórmulas baseadas na normalidade são simples e didáticas, mas nem sempre adequadas. Métodos como bootstrap são mais flexíveis, porém computacionalmente mais caros e ainda dependem da qualidade da amostra.
Isso nos leva ao quarto trade-off, que é a decisão técnica. Um intervalo pode indicar incerteza, mas não decide sozinho. A decisão final precisa considerar impacto no usuário, risco operacional, custo de mudança, requisitos de negócio e tolerância ao erro.
Considerações finais
Intervalos de confiança são uma das ferramentas mais importantes da inferência estatística. Eles permitem estimar parâmetros populacionais a partir de amostras, expressando a incerteza associada a essas estimativas.
No contexto de desenvolvimento de sistemas, eles podem ser usados para analisar latência, disponibilidade, taxa de erro, uso de recursos e resultados de testes A/B. Em ciência de dados, ajudam a avaliar modelos, comparar métricas e comunicar incerteza de maneira mais responsável. Um intervalo de confiança não torna a decisão perfeita, mas a torna mais transparente, quantitativa e cientificamente fundamentada.
Destacamos que neste artigo discutimos apenas o conceito e as principais características do Intervalo de Confiança. Da mesma forma que nos artigos anteriores sobre Estatística, não buscamos encerrar o assunto. Recomendamos consultar outras fontes de referência, onde esses conceitos são explorados com mais detalhes para aprofundar seus conhecimentos.
Obrigado pela leitura e bons estudos.
Referências
BUSSAB, W. O.; MORETTIN, P. A. Estatística Básica. 9. ed. São Paulo: Saraiva, 2017.
CASELLA, George; BERGER, Roger L. Statistical inference. 2. ed. Pacific Grove: Duxbury, 2002.
MONTGOMERY, Douglas C.; RUNGER, George C. Applied statistics and probability for engineers. 5. ed. Hoboken: Wiley, 2012.
MOORE, D. S.; NOTZ, W. I.; FLIGNER, M. A. A Estatística Básica e sua Prática. 7. ed. Rio de Janeiro: LTC, 2017.
NEYMAN, J. Outline of a Theory of Statistical Estimation Based on the Classical Theory of Probability. Philosophical Transactions of the Royal Society of London, Series A, Mathematical and Physical Sciences, v. 236, n. 767, p. 333-380, 1937.
TRIOLA, M. F. Introdução à Estatística. 12. ed. Rio de Janeiro: LTC, 2017.
Referências complementares
NARUHODO, Cientística & Podcast. Estatística Psicobio I 2025 #04 – Teorema Central do Limite e Intervalos de Confiança I. Disponível em: <https://www.youtube.com/live/SQOOrYn6QnI?si=b5QiUVhGMKtFbuLu>. Acesso em: 27 fev. 2026.
NARUHODO, Cientística & Podcast. Estatística Psicobio I 2025 #04 – Intervalos de Confiança II. Disponível em: <https://www.youtube.com/live/SrcnCIaOlQg>. Acesso em: 27 fev. 2026.
- O grau de liberdade no intervalo de confiança representa o número de observações independentes na amostra que podem variar ao estimar parâmetros. Geralmente calculado como (tamanho da amostra menos 1). ↩︎