Comandos SQL DML: inserindo, atualizando e excluindo dados em bancos relacionais
A linguagem SQL (do inglês Structured Query Language), é uma linguagem declarativa usada para definir, consultar, manipular e controlar dados em sistemas de bancos de dados relacionais. Em vez de exigir que o programador descreva passo a passo como o banco deve percorrer os dados, a SQL permite declarar o que se deseja obter ou modificar. Essa característica está ligada ao próprio modelo relacional, no qual os dados são organizados em relações, usualmente implementadas como tabelas compostas por linhas e colunas (Codd, 1970; Date, 2004).
Dentro da SQL, os comandos DML (ou Data Manipulation Language), formam o subconjunto responsável pela manipulação dos registros armazenados nas tabelas. Enquanto os comandos DDL, como CREATE, ALTER e DROP, definem a estrutura do banco de dados, os comandos DML atuam sobre os dados propriamente ditos. Os principais comandos DML são INSERT, usado para inserir registros; UPDATE, usado para modificar registros existentes; e DELETE, usado para remover registros (Elmasri; Navathe, 2016).
A importância dos comandos DML para a área de sistemas é facilmente perceptível, pois praticamente todo sistema de informação precisa cadastrar, alterar e excluir dados. Um comércio eletrônico precisa cadastrar clientes, produtos, pedidos e itens comprados. Um sistema acadêmico precisa registrar alunos, disciplinas, matrículas e notas. Um sistema hospitalar precisa manipular pacientes, consultas, exames e prescrições. Em todos esses casos, a persistência das informações depende da correta aplicação dos comandos DML, respeitando restrições de integridade, chaves primárias, chaves estrangeiras e regras de negócio (Silberschatz; Korth; Sudarshan, 2020).
Portanto, aprender comandos DML significa compreender como os dados entram, mudam e saem de um banco de dados. Essa competência é importante para estudantes e profissionais de desenvolvimento de sistemas, análise de dados, engenharia de software e administração de bancos de dados, pois erros em comandos INSERT, UPDATE e DELETE podem gerar inconsistências, perda de dados ou falhas graves em aplicações reais.
Exemplo prático
Para compreender os comandos DML de forma aplicada, usaremos um exemplo lúdico: a loja virtual Mercado Aberto, um pequeno comércio eletrônico que vende produtos diversos. O banco terá quatro tabelas: clientes, produtos, pedidos e itens_pedido.
A lógica do nosso banco é a seguinte: a tabela clientes armazena os compradores da loja, a tabela produtos registra os itens vendidos, a tabela pedidos representa as compras realizadas pelos clientes e a tabela itens_pedido representa quais produtos aparecem em cada pedido. Esse desenho segue a lógica típica de modelagem relacional, em que entidades e relacionamentos são representados por tabelas conectadas por chaves primárias e estrangeiras (Heuser, 2009).
Para os exemplos deste artigo, utilizaremos o PhpMyAdmin como ferramenta para manipulação do banco de dados. Você pode usar este ou qualquer outra ferramenta de administração de MySQL da sua preferência (MySQL Workbench, por exemplo).Antes de treinar os comandos DML, é necessário criar a estrutura mínima do banco. No phpMyAdmin, acesse a aba SQL, conforme a Figura 1.
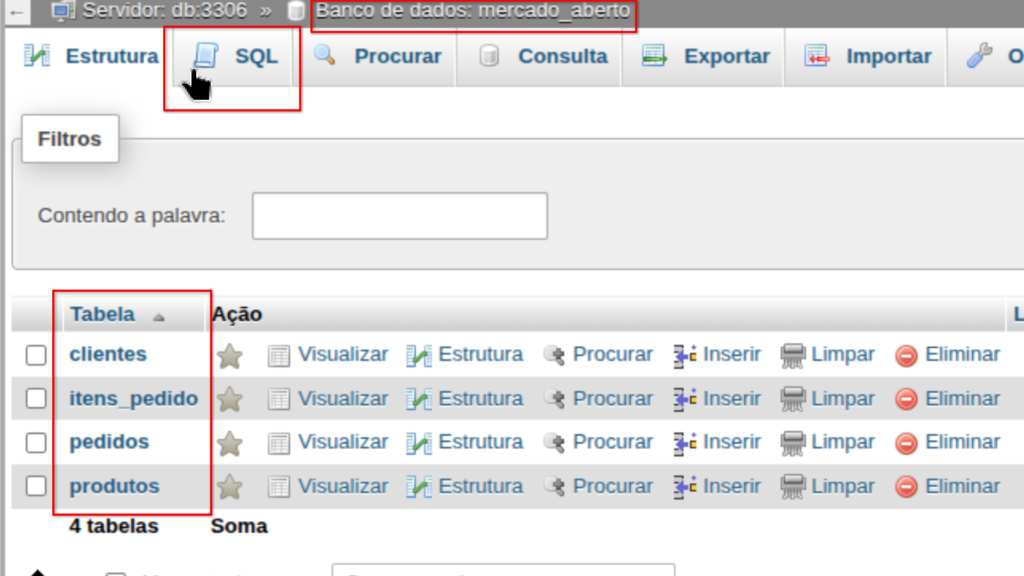
Fonte: Autoria própria.
Após clicar na aba SQL, você verá um campo de texto em branco. Digite os comandos abaixo e, em seguida, execute-os.
CREATE DATABASE mercado_aberto;
USE mercado_aberto;
CREATE TABLE clientes (
id_cliente INT PRIMARY KEY,
nome VARCHAR(100) NOT NULL,
email VARCHAR(120) NOT NULL UNIQUE,
telefone VARCHAR(20) NULL,
data_cadastro DATE NOT NULL
) ENGINE = InnoDB;
CREATE TABLE produtos (
id_produto INT PRIMARY KEY,
nome VARCHAR(100) NOT NULL,
descricao VARCHAR(255) NULL,
preco DECIMAL(10,2) NOT NULL,
estoque INT NOT NULL
) ENGINE = InnoDB;
CREATE TABLE pedidos (
id_pedido INT PRIMARY KEY,
id_cliente INT NOT NULL,
data_pedido DATE NOT NULL,
status_pedido VARCHAR(30) NOT NULL DEFAULT 'Em preparação',
observacao VARCHAR(255) NULL,
CONSTRAINT fk_pedidos_clientes
FOREIGN KEY (id_cliente)
REFERENCES clientes(id_cliente)
ON DELETE RESTRICT
ON UPDATE CASCADE
) ENGINE = InnoDB;
CREATE TABLE itens_pedido (
id_item INT PRIMARY KEY,
id_pedido INT NOT NULL,
id_produto INT NOT NULL,
quantidade INT NOT NULL,
preco_unitario DECIMAL(10,2) NOT NULL,
CONSTRAINT fk_itens_pedidos
FOREIGN KEY (id_pedido)
REFERENCES pedidos(id_pedido)
ON DELETE CASCADE
ON UPDATE CASCADE,
CONSTRAINT fk_itens_produtos
FOREIGN KEY (id_produto)
REFERENCES produtos(id_produto)
ON DELETE RESTRICT
ON UPDATE CASCADE
) ENGINE = InnoDB;Observe que as restrições foram configuradas de forma proposital. Em pedidos, a chave estrangeira id_cliente usa ON DELETE RESTRICT, impedindo a exclusão de um cliente que tenha pedidos cadastrados. Ao mesmo tempo, usa ON UPDATE CASCADE, permitindo que uma alteração no identificador do cliente seja propagada para a tabela pedidos. Em itens_pedido, a chave estrangeira id_pedido usa ON DELETE CASCADE, ou seja, se um pedido for excluído, seus itens também serão excluídos automaticamente. Essa diferença entre RESTRICT e CASCADE é fundamental para compreender a integridade referencial em bancos relacionais (Elmasri; Navathe, 2016).
Inserindo registros completos com INSERT
O comando INSERT é usado para adicionar novos registros em uma tabela. Em sua forma mais explícita, o comando informa o nome da tabela, a lista de colunas e os valores correspondentes. Essa é a forma mais recomendável para fins didáticos e profissionais, pois deixa claro quais valores estão sendo inseridos em quais colunas (Silberschatz; Korth; Sudarshan, 2020).
No primeiro momento, serão inseridos registros completos, preenchendo todas as colunas de cada tabela.
INSERT INTO clientes
(id_cliente, nome, email, telefone, data_cadastro)
VALUES
(1, 'Lia Carvalho', 'lia@mercadoaberto.com', '(33) 99999-1111', '2026-06-01');
INSERT INTO clientes
(id_cliente, nome, email, telefone, data_cadastro)
VALUES
(2, 'Bruno Ferreiro', 'bruno@mercadoaberto.com', '(33) 99999-2222', '2026-06-02');
INSERT INTO produtos
(id_produto, nome, descricao, preco, estoque)
VALUES
(101, 'Mouse', 'Mouse vertical para ergonomia', 29.90, 50);
INSERT INTO produtos
(id_produto, nome, descricao, preco, estoque)
VALUES
(102, 'Teclado', 'Teclado gamer com luzinhas.', 75.00, 12);
INSERT INTO pedidos
(id_pedido, id_cliente, data_pedido, status_pedido, observacao)
VALUES
(1001, 1, '2026-06-05', 'Pago', 'Entregar antes do próximo torneio.');
INSERT INTO pedidos
(id_pedido, id_cliente, data_pedido, status_pedido, observacao)
VALUES
(1002, 2, '2026-06-06', 'Em preparação', 'Cliente retirará na loja.');
INSERT INTO itens_pedido
(id_item, id_pedido, id_produto, quantidade, preco_unitario)
VALUES
(1, 1001, 101, 2, 29.90);
INSERT INTO itens_pedido
(id_item, id_pedido, id_produto, quantidade, preco_unitario)
VALUES
(2, 1001, 102, 1, 75.00);
INSERT INTO itens_pedido
(id_item, id_pedido, id_produto, quantidade, preco_unitario)
VALUES
(3, 1002, 101, 1, 29.90);A ordem dos comandos é importante. Primeiro foram inseridos clientes e produtos. Depois foram inseridos pedidos, pois cada pedido depende de um cliente existente. Por fim, foram inseridos os itens do pedido, pois cada item depende de um pedido e de um produto já cadastrados. Essa sequência respeita a integridade referencial, conceito central em bancos relacionais (Date, 2004).
Para visualizar os registros no phpMyAdmin, o estudante pode clicar no nome da tabela e acessar a aba Visualizar, conforme a Figura 2. Também é possível buscar os registros via SQL (usando o comando SELECT), mas como este não é o foco do artigo, deixaremos para outro texto.
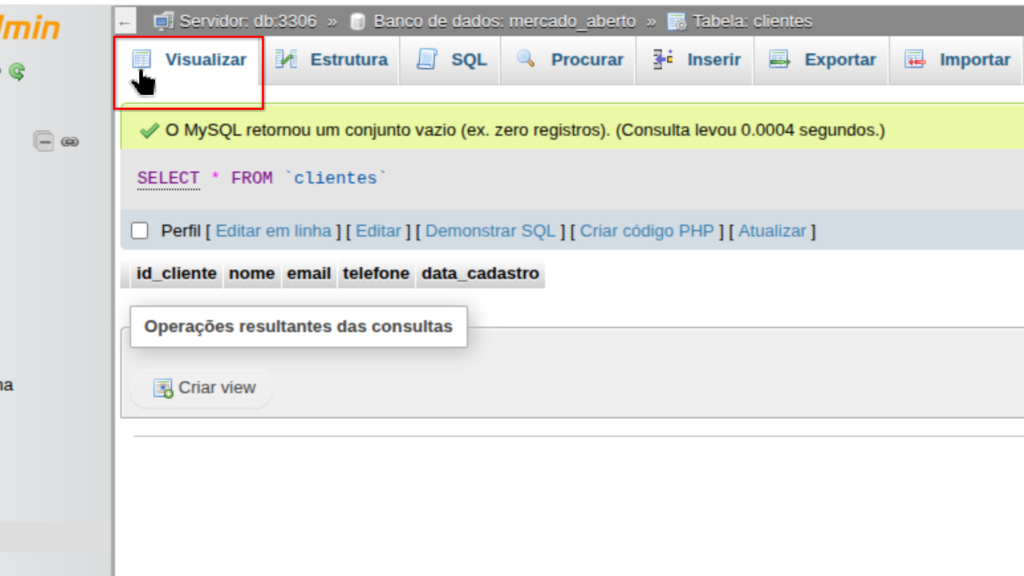
Fonte: Autoria própria.
Inserindo registros incompletos
Em muitos sistemas, nem todos os campos são obrigatórios. Um cliente pode ser cadastrado sem telefone. Um produto pode ser registrado sem descrição inicial. Um pedido pode ser aberto sem observação. Para isso, a tabela precisa permitir valores NULL ou definir valores padrão com DEFAULT.
No banco criado, as colunas telefone, descricao e observacao aceitam NULL. A coluna status_pedido possui valor padrão 'Em preparação'. Isso permite inserir registros incompletos, desde que os campos obrigatórios sejam respeitados.
INSERT INTO clientes
(id_cliente, nome, email, data_cadastro)
VALUES
(3, 'Marta Alquimista', 'marta@mercadoaberto.com', '2026-06-07');Nesse caso, a coluna telefone não foi informada. Como ela aceita NULL, o MySQL armazenará ausência de valor nessa coluna.
INSERT INTO produtos
(id_produto, nome, preco, estoque)
VALUES
(103, 'Headset gamer', 120.00, 8);Aqui, a coluna descricao foi omitida. Como ela também permite NULL, o registro será aceito.
INSERT INTO pedidos
(id_pedido, id_cliente, data_pedido)
VALUES
(1003, 3, '2026-06-08');Nesse exemplo, as colunas status_pedido e observacao foram omitidas. A coluna observacao ficará como NULL, enquanto status_pedido receberá automaticamente o valor padrão 'Em preparação'.
INSERT INTO itens_pedido
(id_item, id_pedido, id_produto, quantidade, preco_unitario)
VALUES
(4, 1003, 103, 1, 120.00);A inserção incompleta não significa inserir dados de qualquer maneira. Ela depende das regras definidas na estrutura da tabela. Campos marcados como NOT NULL precisam receber valores. Campos com chave estrangeira precisam apontar para registros existentes. Assim, o banco de dados atua como uma camada de proteção contra inconsistências (Elmasri; Navathe, 2016).
Atualizando campos dos registros com UPDATE
O comando UPDATE modifica registros existentes. Ele deve ser usado com extremo cuidado, pois uma atualização sem cláusula WHERE pode alterar todos os registros de uma tabela. Em sistemas reais, esse é um dos erros mais perigosos em SQL.
A estrutura geral do comando é:
UPDATE nome_da_tabela
SET coluna = novo_valor
WHERE condição;No Mercado Aberto, suponha que o estoque do mouse vertical precise ser atualizado após uma conferência no depósito.
UPDATE produtos
SET estoque = 47
WHERE id_produto = 101;Agora, imagine que o preço do headset gamer subiu devido à escassez nos fornecedores.
UPDATE produtos
SET preco = 135.00
WHERE id_produto = 103;Também é possível atualizar mais de uma coluna no mesmo comando. Suponha que o pedido 1002 tenha sido pago e que a observação precise ser ajustada.
UPDATE pedidos
SET status_pedido = 'Pago',
observacao = 'Pagamento confirmado. Separar para retirada.'
WHERE id_pedido = 1002;A cláusula WHERE delimita quais registros serão alterados. Sem ela, o comando abaixo mudaria o status de todos os pedidos, o que provavelmente causaria uma inconsistência operacional. Mas cuidado! Esse comando não deve ser executado neste exercício. Ele aparece apenas como alerta didático.
UPDATE pedidos
SET status_pedido = 'Pago';Em bancos relacionais, a consistência dos dados depende tanto das restrições definidas no esquema quanto da precisão dos comandos executados pelos usuários e aplicações (Silberschatz; Korth; Sudarshan, 2020).
Excluindo registros com DELETE
O comando DELETE remove registros de uma tabela. Assim como o UPDATE, ele deve ser usado com a cláusula WHERE para evitar exclusões indevidas.
A estrutura geral é:
DELETE FROM nome_da_tabela
WHERE condição;Para excluir um produto que ainda não foi usado em nenhum pedido, seria possível executar:
INSERT INTO produtos
(id_produto, nome, descricao, preco, estoque)
VALUES
(104, 'Monitor gamer', 'Monitor com 144hz de atualização e 32 polegadas', 4900.90, 20);
DELETE FROM produtos
WHERE id_produto = 104;A exclusão funciona porque o produto 104 não está associado a nenhum item de pedido. Quando há relacionamentos por chave estrangeira, o comportamento depende da regra definida: RESTRICT, CASCADE, SET NULL ou outras ações previstas pelo SGBD. Neste artigo, serão testadas especificamente RESTRICT e CASCADE.
Testando RESTRICT na exclusão
A restrição RESTRICT impede uma operação quando ela violaria a integridade referencial. No banco criado, a tabela pedidos possui uma chave estrangeira para clientes com ON DELETE RESTRICT. Isso significa que um cliente com pedidos não pode ser excluído diretamente.
Tente executar:
DELETE FROM clientes
WHERE id_cliente = 1;O MySQL deve retornar um erro semelhante a este:
Cannot delete or update a parent row: a foreign key constraint failsEsse erro é esperado. O cliente 1, Lia Carvalho, possui o pedido 1001. Se o banco permitisse a exclusão da cliente, o pedido ficaria apontando para um cliente inexistente. A restrição RESTRICT evita esse tipo de inconsistência.
O mesmo raciocínio vale para produtos associados a itens de pedido. A chave estrangeira id_produto em itens_pedido foi definida com ON DELETE RESTRICT. Assim, o produto 101 (mouse), não pode ser removido enquanto estiver presente em algum item de pedido.
DELETE FROM produtos
WHERE id_produto = 101;Esse comando também deve falhar, pois existem itens de pedido associados ao produto 101.
Testando CASCADE na exclusão
A restrição CASCADE propaga automaticamente uma operação para os registros dependentes. No banco criado, a tabela itens_pedido possui uma chave estrangeira para pedidos com ON DELETE CASCADE. Isso significa que, se um pedido for excluído, seus itens também serão excluídos automaticamente.
Antes de executar a exclusão, veja os itens do pedido 1001.
SELECT * FROM itens_pedido
WHERE id_pedido = 1001;Agora, exclua o pedido 1001.
DELETE FROM pedidos
WHERE id_pedido = 1001;Em seguida, consulte novamente os itens do pedido.
SELECT * FROM itens_pedido
WHERE id_pedido = 1001;O resultado deve voltar vazio. Os itens associados ao pedido 1001 foram excluídos automaticamente. Esse é o efeito do ON DELETE CASCADE.
Esse comportamento pode ser útil quando os registros dependentes não fazem sentido sem o registro principal. Em um comércio eletrônico, os itens de um pedido deixam de ter sentido se o próprio pedido for removido. Em outros contextos, porém, CASCADE pode ser perigoso, pois uma exclusão em uma tabela principal pode apagar muitos registros relacionados. A decisão entre RESTRICT e CASCADE deve refletir a regra de negócio e o risco de perda de dados (Date, 2004; Elmasri; Navathe, 2016).
Testando CASCADE na atualização
O ON UPDATE CASCADE propaga alterações feitas no valor da chave primária da tabela principal para as chaves estrangeiras das tabelas dependentes. Embora em sistemas reais seja comum evitar mudanças em identificadores primários, esse recurso é importante para compreender a integridade referencial.
No banco criado, a relação entre clientes e pedidos usa ON UPDATE CASCADE. Isso significa que, se o id_cliente de um cliente for alterado, os pedidos associados também serão atualizados.
Antes da atualização, consulte o cliente 2 e seus pedidos.
SELECT * FROM clientes
WHERE id_cliente = 2;
SELECT * FROM pedidos
WHERE id_cliente = 2;Agora, altere o identificador do cliente 2 para 20.
UPDATE clientes
SET id_cliente = 20
WHERE id_cliente = 2;Depois, consulte os pedidos novamente.
SELECT * FROM pedidos
WHERE id_cliente = 20;O pedido que antes apontava para o cliente 2 agora deve apontar para o cliente 20. Essa propagação ocorreu por causa do ON UPDATE CASCADE.
Também é possível testar o mesmo comportamento entre produtos e itens_pedido. Primeiro, veja o item associado ao produto 103.
SELECT * FROM itens_pedido
WHERE id_produto = 103;Agora, altere o identificador do produto 103 para 130.
UPDATE produtos
SET id_produto = 130
WHERE id_produto = 103;Consulte novamente:
SELECT * FROM itens_pedido
WHERE id_produto = 130;O item do pedido que antes apontava para o produto 103 agora deve apontar para o produto 130. A atualização foi propagada automaticamente.
Testando RESTRICT na atualização
Para testar RESTRICT em atualização, seria necessário criar uma chave estrangeira com ON UPDATE RESTRICT. Como o banco atual foi configurado com ON UPDATE CASCADE, as atualizações de chaves primárias são propagadas. Essa escolha foi feita para permitir o teste explícito de CASCADE em operações de atualização.
Contudo, se quisermos imaginar o comportamento restritivo na atualização, basta voltarmos à subseção Testando RESTRICT na exclusão, que trata do RESTRICT na exclusão. Segundo Elmasri e Navathe (2016), o ON UPDATE RESTRICT impediria a alteração de uma chave primária se existissem registros dependentes apontando para ela.
Conclusão
Os comandos DML são a parte da SQL responsável por manipular os dados armazenados nas tabelas. O comando INSERT permite cadastrar novos registros; o comando UPDATE permite modificar registros existentes; e o comando DELETE permite remover registros. Esses três comandos sustentam operações fundamentais de sistemas de informação, como cadastro de clientes, atualização de estoque, registro de pedidos e exclusão de dados obsoletos.
Do ponto de vista da formação em desenvolvimento de sistemas, dominar DML significa compreender a camada em que a aplicação efetivamente interage com os dados. Interfaces, APIs e regras de negócio frequentemente dependem de comandos equivalentes a INSERT, UPDATE e DELETE. Por isso, o estudo desses comandos deve ir além da sintaxe e favorecer o entendimento dos efeitos, riscos e sua relação com a modelagem relacional.
Obrigado pela leitura e bons estudos!
Referências
CODD, Edgar F. A relational model of data for large shared data banks. Communications of the ACM, New York, v. 13, n. 6, p. 377-387, 1970.
DATE, C. J. Introdução a sistemas de bancos de dados. 8. ed. Rio de Janeiro: Elsevier, 2004.
ELMASRI, Ramez; NAVATHE, Shamkant B. Sistemas de banco de dados. 7. ed. São Paulo: Pearson, 2016.
HEUSER, Carlos Alberto. Projeto de banco de dados. 6. ed. Porto Alegre: Bookman, 2009.
SILBERSCHATZ, Abraham; KORTH, Henry F.; SUDARSHAN, S. Sistema de banco de dados. 7. ed. Rio de Janeiro: LTC, 2020.