Optativa 2: Regressão
A análise de regressão é uma das ferramentas estatísticas existentes para a modelagem de dados, cuja origem remonta aos estudos biométricos do final do século XIX. O termo foi cunhado originalmente por Francis Galton em 1886, no seu estudo Regression towards Mediocrity in Hereditary Stature, onde ele observou que a altura dos filhos tendia a “regredir” para a média da população, em vez de replicar extremos dos pais (Galton, 1886). Embora o conceito tenha nascido na biologia, a sua formalização matemática foi solidificada por Karl Pearson e, posteriormente, por Ronald A. Fisher, transformando-a numa técnica robusta para quantificar relações.
Em termos contemporâneos, a regressão não se limita à biometria, mas define-se como o estudo da dependência estatística de uma variável (chamada dependente ou resposta) em relação a uma ou mais variáveis (explicativas ou regressores). Segundo Gujarati e Porter (2011), a essência da técnica reside em estimar o valor médio da variável dependente com base nos valores fixos das variáveis explicativas. Portanto, trata-se de um método para descrever matematicamente como uma variável se comporta em função de outras.
Objetivos da regressão
O objetivo central da regressão vai além da simples associação entre dados; ela busca estabelecer uma relação funcional de causa e efeito, ainda que estatística, e não necessariamente determinística. Wooldridge (2010a) argumenta que o principal propósito da análise de regressão, especialmente na econometria e ciência de dados, é a inferência ceteris paribus1. Isso significa isolar o efeito de uma variável independente sobre a variável resposta, mantendo todos os outros fatores constantes, o que permite testar teorias e hipóteses científicas com rigor.
Além da inferência e explicação de fenômenos, a regressão possui um forte caráter preditivo. Conforme destacado por Hair et al. (2009), a técnica é amplamente utilizada para prever valores futuros da variável dependente com base em novos dados das variáveis independentes. Em cenários de Machine Learning, por exemplo, o foco desloca-se frequentemente da interpretação dos coeficientes para a minimização do erro de previsão, tornando a regressão uma ferramenta versátil tanto para “explicar” o passado quanto para “antecipar” o futuro.
Benefícios da regressão
Um dos maiores benefícios da regressão é a sua capacidade de quantificar a força e a direção das relações entre variáveis de forma precisa. Diferentemente de análises puramente descritivas, a regressão fornece coeficientes numéricos que indicam, por exemplo, exatamente quanto as vendas aumentam para cada unidade monetária investida em publicidade. Esta quantificação permite aos gestores e cientistas de dados passarem de intuições vagas para decisões baseadas em métricas concretas (Gujarati; Porter, 2011).
Outra vantagem é o controle estatístico de variáveis de confusão. Em experimentos não controlados, é comum que múltiplos fatores influenciem o resultado simultaneamente. A regressão múltipla permite “limpar” esses efeitos, ajustando o modelo para considerar a influência simultânea de diversos fatores. Isso oferece uma visão mais realista e menos enviesada do fenômeno estudado, de forma a evitar correlações sem sentido e garantir a validade das conclusões analíticas (Wooldridge, 2010a).
Exemplo de código
Antes de começarmos o exemplo, precisamos fazer um disclaimer: este artigo não está focado em explicar a base matemática e/ou conceitual da técnica. Vamos apenas mostrar a aplicação de código em python. Por isso, pode ser que você se sinta perdido em relação aos passos do código e aos resultados que são encontrados após a execução do algoritmo.
Recomendamos que você procure livros, vídeos e outros materiais para complementar sua experiência educativa. Comece pelas referências que estão disponíveis no final desse artigo, assista ao vídeo introdutório abaixo e procure outras fontes.
Disclaimer feito, seguimos…
Neste artigo seguiremos com o conjunto 'spotify_hits_dataset_complete.tsv' que pode ser baixado aqui. O nosso objetivo com este código é prever a popularidade da música a partir de atributos numéricos existentes no conjunto de dados, como danceability, energy, tempo e outros.
O código que construímos na Figura 1 começa com a importação das bibliotecas que utilizaremos para manipular os dados. Na tarefa de regressão, especialmente, faremos uso da scikit-learn (ou sklearn), que é uma biblioteca open-source para Python capaz de oferecer ferramentas para classificação, regressão, agrupamento (clustering), seleção de modelos e pré-processamento de dados.
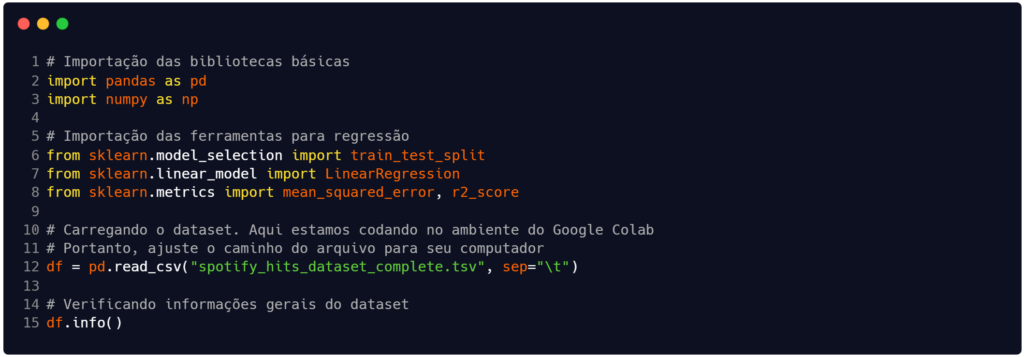
Fonte: Autoria própria.
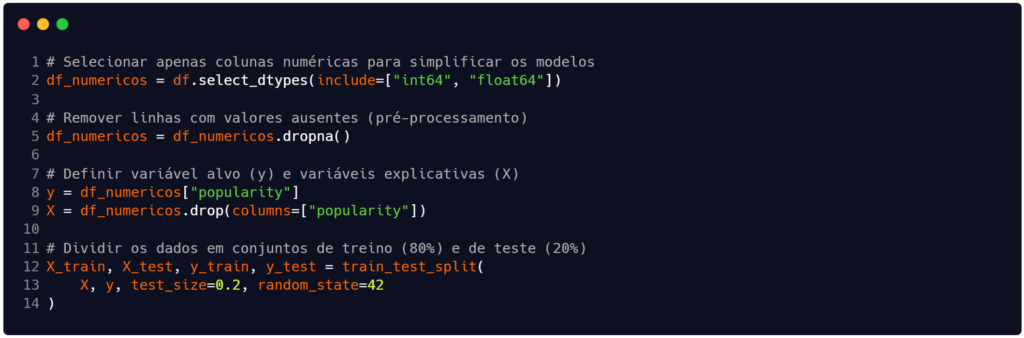
Após a leitura do arquivo e exibição da estrutura geral dele, na Figura 2 selecionamos apenas as colunas (ou atributos, ou variáveis) numéricas para trabalhar e inserimos elas na dataframe df_numericos (linha 2). Neste dataframe realizamos um pré-processamento simples para eliminar campos ausentes (linha 5).
Em seguida, criamos o conjunto de variáveis explicativas (X) e da variável alvo (y). Os atributos contidos em X servirão como preditores na busca para prever a popularidade de uma música (y).
Finalizando este bloco do código, criamos os subconjuntos de treinamento e teste, tanto para o conjunto X quanto para o y. Assim, as estruturas X_train e X_test são os subconjuntos de variáveis preditoras e as estruturas y_train e y_test são os subconjuntos de variável alvo.
Fonte: Autoria própria.
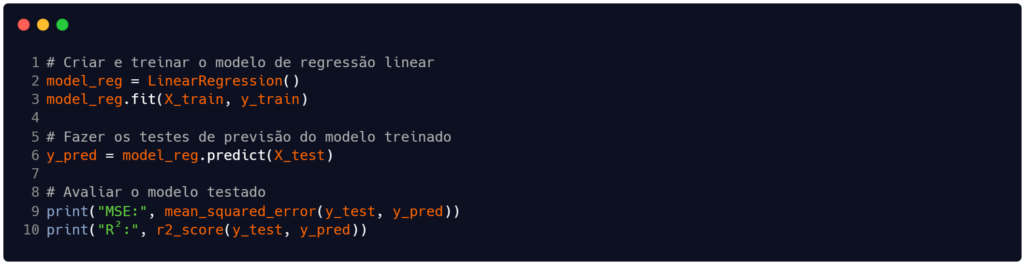
Com os subconjuntos para treinamento e teste preparados, criamos – nas linhas 2 e 3 da Figura 3 – o modelo de regressão linear e treinamos ele com nosso conjunto de treino para X e y. Queremos que o modelo aprenda a relacionar as variáveis preditoras (X_train) com os valores alvo (y_train).
Na linha 6 estamos finalmente testando o modelo a fim de validar o quão eficiente ele está em predizer os registros da variável alvo. O model_reg aciona o método predict, que recebe como parâmetro o conjunto de entradas de teste (X_test).
Fonte: Autoria própria.
Finalizando o código, nas linhas 9 e 10 apresentamos duas métricas de avaliação do modelo de regressão aplicado a este problema. A saída que recebemos ao final está contida na Tabela 1.
| Métrica | Valor |
| MSE | 143.19619833123235 |
| R² | 0.5989732820776716 |
Fonte: Autoria própria.
Os resultados disponíveis na Tabela 1 são opções disponíveis da biblioteca scikit-learn e mostram como o modelo se comportou no problema. Para interpretar o Mean Squared Error (MSE), devemos compreender que ele representa a média dos quadrados dos erros, ou seja, a média das diferenças ao quadrado entre os valores previstos pelo modelo e os valores reais. Como essa métrica eleva os resíduos ao quadrado, ela penaliza severamente erros maiores, sendo útil para identificar se o modelo está cometendo grandes desvios pontuais (James et al., 2013).
Contudo, o valor final de 143,19 não está na mesma unidade de medida da nossa variável alvo, que é a popularidade ('popularity'). O problema do MSE neste caso é conceitual e tem relação com sua dimensão física. Mesmo que consideremos que o valor 143,19 caiba numericamente dentro do intervalo de 0 a 100 da variável popularidade, a unidade de medida do MSE é “pontos de popularidade ao quadrado”. Isso ocorre porque o cálculo do MSE eleva as diferenças ao quadrado (unidade2), tornando impossível uma comparação direta e linear com a escala original da sua variável alvo (James et al., 2013).
Para entender o erro na mesma escala dos nossos dados (0 a 100), devemos observar a Raiz do Erro Quadrático Médio (RMSE), que é simplesmente a raiz quadrada do MSE. Ao calcular a raiz quadrada de 143,19, chegamos a aproximadamente 11,96. Este valor sim está na mesma unidade da variável alvo (“pontos de popularidade”) e indica que, em média, as previsões do nosso modelo desviam cerca de 12 pontos para cima ou para baixo em relação ao valor real, o que representa um erro médio de aproximadamente 12% dentro da escala total (Wooldridge, 2010b).
Considerando o contexto de popularidade musical (nossos dados), um RMSE de aproximadamente 12 pontos na escala de 0 a 100 é um resultado razoável e até esperado, dada a natureza subjetiva e altamente volátil do consumo cultural. A popularidade de uma música raramente depende apenas de suas características intrínsecas (como bpm, acústica ou gênero), sendo fortemente influenciada por dinâmicas sociais imprevisíveis e “efeitos de rede”, o que torna a predição exata extremamente difícil (Salganik; Dodds; Watts, 2006).
Já o Coeficiente de Determinação (R2) de 0,598 indica que, aproximadamente, 60% da variabilidade da nossa variável dependente (o que queremos prever) é explicada pelas variáveis independentes (os dados que usamos) incluídas no seu modelo linear. O restante – cerca de 40% – representa a variância não explicada ou ruído. Um R2 de 0,60 sugere um ajuste moderado e, dependendo da área de estudo, pode ser considerado bom ou não. Por exemplo, em ciências sociais pode ser considerado bom, enquanto em física pode ser considerado baixo (Gujarati; Porter, 2011). Sob essa ótica, o R2 de aproximadamente 0,60 indica um ajuste robusto para dados comportamentais. Em pesquisas que envolvem preferências humanas, explicar 60% da variância é frequentemente considerado um efeito forte, pois o restante da variação costuma ser atribuído a fatores aleatórios ou não mensuráveis pelo modelo.
Essas métricas foram escolhidas, e são padrão em bibliotecas como o scikit-learn, por motivos complementares de otimização matemática e comunicabilidade. O MSE é preferido matematicamente como função de perda (loss function) durante o treinamento porque é uma função convexa e diferenciável, o que facilita o cálculo do gradiente para encontrar os parâmetros ideais do modelo (Goodfellow; Bengio; Courville, 2016).
Por outro lado, o R2 é selecionado por sua capacidade de interpretação intuitiva. Diferente do MSE, ele é uma medida adimensional (independente de escala), permitindo que você comunique a qualidade do ajuste do modelo como uma proporção ou porcentagem de “sucesso” na explicação dos dados, facilitando a comparação entre diferentes estudos ou modelos (James et al., 2013).
Antes de encerrarmos, mais um disclaimer: este código não foi construído pensando em ser otimizado, em ser um modelo de regressão altamente eficiente ou aplicar determinada boa prática de programação. É bem possível que você encontre pontos que podem ser melhorados no código e, neste caso, recomendamos que pratique aplicando-os para melhorar o modelo e algoritmo como um todo.
Considerações finais
A análise de regressão se consolidou como um pilar na ciência de dados, transitando da descrição histórica de Galton para a moderna modelagem preditiva. A sua dupla capacidade de inferir causalidade ceteris paribus e gerar previsões precisas torna-a uma técnica interessante para transformar dados brutos em conhecimento estratégico. O domínio dela não só enriquece a análise exploratória, como fundamenta decisões baseadas em evidências robustas, permitindo ao cientista de dados navegar com segurança entre a teoria estatística e a prática aplicada.
Conforme você avançar em seus estudos, a compreensão profunda desses algoritmos e de seus fundamentos estatísticos será importante para enfrentar os desafios cada vez mais complexos do mercado atual.
Obrigado pela leitura e bons estudos.
Referências
GALTON, F. Regression towards mediocrity in hereditary stature. The Journal of the Anthropological Institute of Great Britain and Ireland, v. 15, p. 246-263, 1886.
GOODFELLOW, I.; BENGIO, Y.; COURVILLE, A. Deep Learning. Cambridge: MIT Press, 2016.
GUJARATI, D. N.; PORTER, D. C. Basic Econometrics. 5. ed. New York: McGraw-Hill Education, 2011.
HAIR, J. F. et al. Multivariate Data Analysis. 7. ed. Upper Saddle River: Prentice Hall, 2009.
JAMES, G. et al. An Introduction to Statistical Learning: with Applications in R. New York: Springer, 2013.
SALGANIK, M. J.; DODDS, P. S.; WATTS, D. J. Experimental Study of Inequality and Unpredictability in an Artificial Cultural Market. Science, v. 311, n. 5762, p. 854-856, 2006.
WOOLDRIDGE, J. M. Introductory Econometrics: A Modern Approach. 4. ed. Mason: South-Western Cengage Learning, 2010a.
WOOLDRIDGE, J. M. Econometric Analysis of Cross Section and Panel Data. 2. ed. Cambridge: MIT Press, 2010b.
- Inferência ceteris paribus refere-se à análise do efeito de uma única variável sobre outra, assumindo que todas as demais variáveis permanecem constantes ou inalteradas. A expressão em latim significa, literalmente, “tudo o mais mantido constante“. ↩︎