Optativa 2: Integração dos dados
A Ciência de Dados tem como objetivo principal a extração de informações úteis a partir de dados que servirão como embasamento para tomadas de decisão. Contudo, para que essa extração seja realizada com qualidade, os dados brutos devem ser submetidos a um processo de pré-processamento.
A qualidade dos dados é um pré-requisito importante para que as informações descobertas sejam realmente significativas. Entretanto, no mundo real, os dados costumam ser incompletos, inconsistentes, ruidosos e, muitas vezes, estão em um formato inutilizável ou em diversas fontes diferentes (Pimentel et al., 2021). Logo, a etapa de pré-processamento consiste em ajustar os dados para que sirvam como entrada para os processos de análise posteriores.
O trabalho de pré-processamento geralmente ocorre com as seguintes etapas: Limpeza de Dados, Integração de Dados, Transformação de Dados e Redução de Dados (Pimentel et al., 2021). Essas etapas não são mutuamente exclusivas e dependem do conjunto de dados em análise.
Neste artigo, vamos tratar apenas da integração dos dados. As demais etapas podem ser encontradas nestes artigos do site: limpeza, transformação e redução.
Integração de dados
Após a limpeza inicial do conjunto de dados (dataset), podemos passar para a integração dos dados, que é a etapa em que os dados armazenados em diversas fontes são combinados para criar uma estrutura unificada, fornecendo informações mais significativas (Pimentel et al., 2021).
Por meio da linguagem Python, podemos mesclar e juntar múltiplas tabelas usando operações de junção (join), implementadas pela função merge() que existe na biblioteca pandas. O funcionamento dessa operação é similar ao comando join que existe em linguagem SQL. Portanto, se você conhece banco de dados e SQL, vai entender mais facilmente o que faremos aqui.
Para compreendermos melhor o processo, vamos usar um exemplo: imagine que você trabalha na área de dados em uma gravadora. O departamento de Marketing tem uma planilha com os nomes e fotos dos artistas agenciados pela empresa, enquanto o departamento de Analytics tem os números de popularidade e seguidores desses artistas na plataforma Spotify. Agora, a pedido dos gerentes da empresa, seu trabalho é unir esses dados para criar um relatório completo.
Para este exemplo, vamos usar a base de dados disponível em Oliveira (2021): clique aqui para baixar. Como o conjunto de dados já está unificado, primeiro vamos carregar o arquivo e criar artificialmente essas duas tabelas separadas para que você possa praticar a união. Na Figura 1 é exatamente isso que fazemos. Estamos separando os atributos (colunas) conforme o contexto fictício.
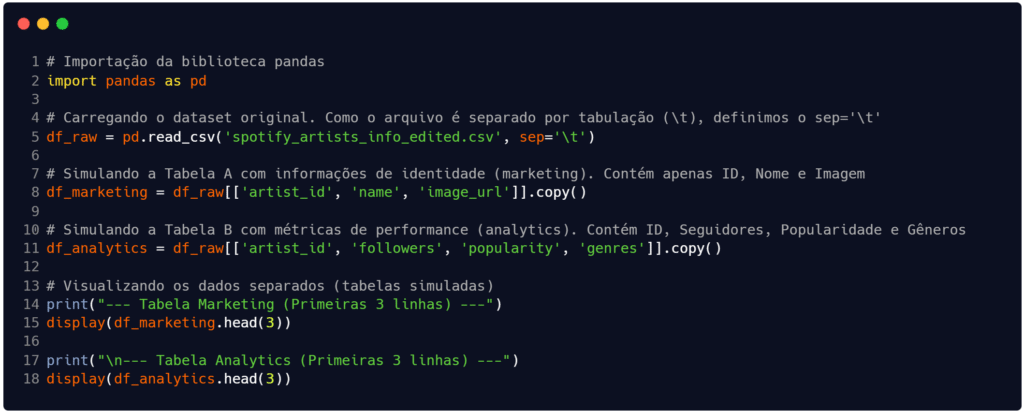
Fonte: Autoria própria.
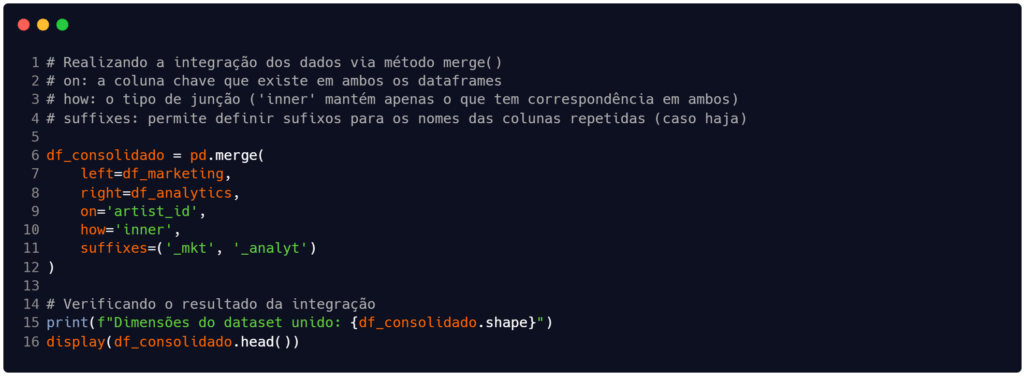
Com as tabelas armazenadas nas estruturas df_marketing e df_analytics, partiremos para a tarefa de unificação de ambas. E aqui está o coração do nosso exemplo. Para unir as tabelas, precisamos de uma chave comum entre ambas. Essa chave é conhecida como chave primária (do inglês, primary key) – exatamente aquela da disciplina de banco de dados. No nosso caso, a chave primária é o campo artist_id.
Na Figura 2 estamos chamando o método merge() na linha 6 e passando alguns parâmetros de funcionamento. Nos parâmetros left e right indicamos quais tabelas serão usadas na unificação, enquanto o argumento on indica qual é a chave primária para conexão entre os registros de ambas as tabelas. O penúltimo argumento, o how, serve para indicar o tipo de junção – que neste caso é o tipo ‘inner‘ para manter apenas as relações de registros que tem correspondência entre si, ou seja, chaves primárias iguais). Finalmente, o parâmetro suffixes serve para gerenciar casos onde há colunas com nomes iguais, destacando quais sufixos devem ser adicionados aos nomes para mantê-las na estrutura unificada.
Fonte: Autoria própria.
Nem sempre é necessário usar o parâmetro suffixes, mas é bastante comum que existam colunas com o mesmo nome (além da chave) em integrações de dados. Portanto, fica a dica.
Breve visão estatística sobre a base
Terminamos o exemplo básico de integração do dataset. Agora, temos um dataframe chamado df_consolidado que armazena as colunas e os registros de ambas as tabelas (df_marketing e df_analytics).
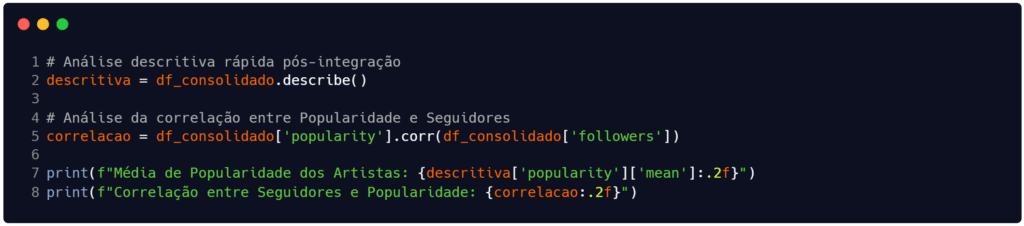
Em momento assim, pode surgir a seguinte dúvida: “o que posso fazer após integrar os dados?”. Bem, podemos tirar alguns insights rápidos sobre a base integrada (mesmo que ainda não tenhamos finalizado o pré-processamento). Na Figura 3 estamos usando o método describe() para obter dados descritivos dos atributos (média, mediana etc.) e o método corr() para obter a correlação entre dois campos específicos, a popularidade (popularity) e a quantidade de seguidores (followers).
Fonte: Autoria própria.
Ao rodar esse código, você verá que existe uma correlação positiva (0.55), que é digamos… “leve”, entre os dois atributos. A princípio, essa correlação indica que quanto mais seguidores, maior a popularidade dos artistas. Contudo, cabe destacar há podem haver valor atípicos (outliers) enviesando o resultado da correlação.
Considerações finais
Para quem gosta de analogias para compreender o funcionamento de algo, podemos dizer que o pré-processamento de dados pode ser comparado a um chef preparando ingredientes antes de cozinhar uma refeição complexa.
Os dados brutos são como os ingredientes crus que, após a parte da limpeza (leia o artigo aqui), precisam ser cozinhados de forma integrada para gerar pratos saborosos. Assim, podemos dizer que a integração é a etapa que unifica os ingredientes que deveriam estar juntos (como azeite e vinagre).
As demais partes do pré-processamento (transformação e redução) acontecem após a limpeza dos dados, de forma a garantir a qualidade final do conjunto de dados. Você pode ler sobre elas aqui: transformação e redução.
Obrigado pela leitura e bons estudos.
Referências
LOPES, Gesiel Rios et al. Introdução à Análise Exploratória de Dados com Python. In: Escola Regional de Computação Aplicada à Saúde (ERCAS), Teresina: [s.n.], 2019. Disponível em: https://www.researchgate.net/publication/336778766_Introducao_a_Analise_Exploratoria_de_Dados_com_Python. Acesso em: 11 nov. 2025.
MORETTIN, Pedro Alberto; SINGER, Julio da Motta. Estatística e ciência de dados. 1. ed. Rio de Janeiro: LTC | Livros Técnicos e Científicos Editora Ltda., 2022.
OLIVEIRA, Gabriel Pereira de. spotify_artists_info_edited.csv. 2021. Arquivo de dados hospedado no GitHub. Disponível em: https://github.com/opgabriel/jai2021-jupyter/blob/main/3.Preparacao/datasets/spotify_artists_info_edited.csv. Acesso em: 21 nov. 2025.
PIMENTEL, João Felipe et al. Ciência de Dados com Reprodutibilidade usando Jupyter. In: ANDRADE, Aline M. S.; WAZLAWICK, Raul S. (Org.). Jornada de Atualização em Informática 2021. Porto Alegre: Sociedade Brasileira de Computação (SBC), 2021. Disponível em: https://books-sol.sbc.org.br/index.php/sbc/catalog/view/67/292/544-1. Acesso em: 11 nov. 2025.
RIDZUAN, F.; WAN ZAINON, W. M. N. A review on data cleansing methods for big data. Procedia Computer Science, [S. l.], v. 159, p. 731–738, 2019. DOI: 10.1016/j.procs.2019.09.198. Disponível em: https://www.sciencedirect.com/science/article/pii/S1877050919318885. Acesso em: 21 nov. 2025.