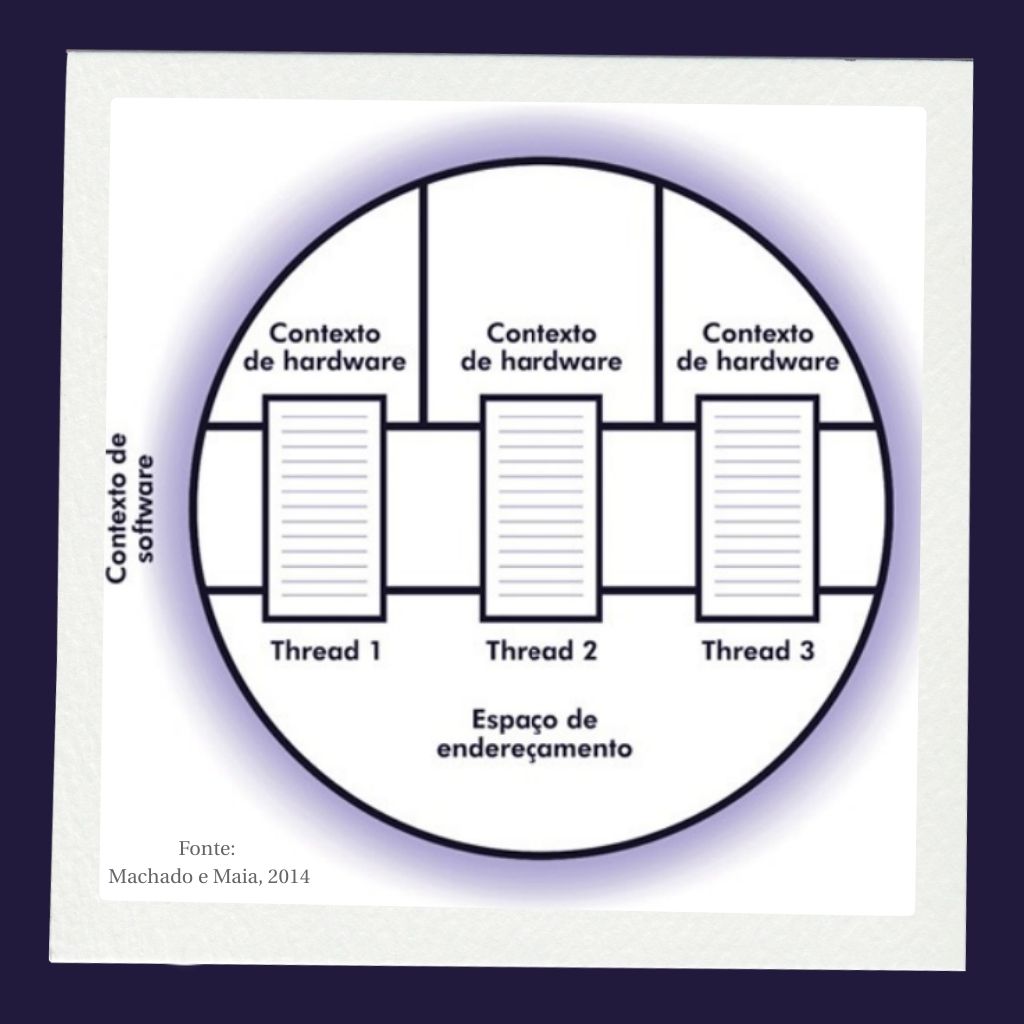
Optativa 2: Agrupamento
O agrupamento (clustering) é um processo de organização de objetos em grupos cujos membros são similares de alguma forma. Segundo a definição clássica de Jain, Murty e Flynn (1999), a técnica de clustering é a organização não supervisionada de padrões (observações, vetores de dados ou vetores de características) em grupos ou clusters. A premissa central é que os padrões dentro de um cluster válido são mais similares entre si do que padrões pertencentes a clusters diferentes (Jain; Murty; Flynn, 1999). Diferente da classificação, aqui não existem rótulos prévios; o algoritmo deve descobrir a estrutura intrínseca dos dados por conta própria.
O principal objetivo do agrupamento é revelar a estrutura subjacente de um conjunto de dados heterogêneo. Conforme estabelecido por Sokal e Sneath (1963), o objetivo é criar uma classificação objetiva e estável baseada na semelhança observável entre as unidades (…). Em termos práticos de Ciência de Dados, Anderberg (1973) destaca que o objetivo raramente é um fim em si mesmo, mas um meio para:
- Redução de dados: simplificar grandes conjuntos de dados substituindo grupos de observações semelhantes por um único representante (o centroide, por exemplo).
- Exploração de dados: identificar hipóteses sobre a estrutura dos dados.
Benefícios do agrupamento
A aplicação correta de técnicas de agrupamento traz benefícios diretos para a análise exploratória. Hartigan (1975), em seu trabalho sobre algoritmos de clustering, aponta que a principal utilidade reside na capacidade de:
- Nomeação e classificação: permitir que objetos complexos sejam agrupados e nomeados, facilitando a comunicação e o entendimento do fenômeno estudado.
- Previsão: objetos no mesmo cluster tendem a ter propriedades semelhantes; portanto, o conhecimento sobre um membro do grupo fornece pistas sobre os outros.
- Resumo: oferece uma visão geral, resumida e abrangente de grandes volumes de informação.
Exemplo de código
Antes de começarmos o exemplo, precisamos fazer um disclaimer: este artigo não está focado em explicar a base matemática e/ou conceitual da técnica. Vamos apenas mostrar a aplicação de código em python. Por isso, pode ser que você se sinta perdido em relação aos passos do código e aos resultados que são encontrados após a execução do algoritmo.
Recomendamos que você procure livros, vídeos e outros materiais para complementar sua experiência educativa. Comece pelas referências que estão disponíveis no final desse artigo, assista ao vídeo introdutório abaixo e procure outras fontes.
Disclaimer feito, seguimos…
Neste artigo seguiremos com o conjunto 'spotify_hits_dataset_complete.tsv' que pode ser baixado aqui. O nosso objetivo com este código é agrupar músicas que possuam características semelhantes sem a ajuda de rótulos previamente definidos.
O código que construímos na Figura 1 começa com a importação das bibliotecas que utilizaremos para manipular os dados. Na tarefa de agrupamento, especialmente, faremos uso da scikit-learn (ou sklearn), que é uma biblioteca open-source para Python capaz de oferecer ferramentas para classificação, regressão, agrupamento (clustering), seleção de modelos e pré-processamento de dados.
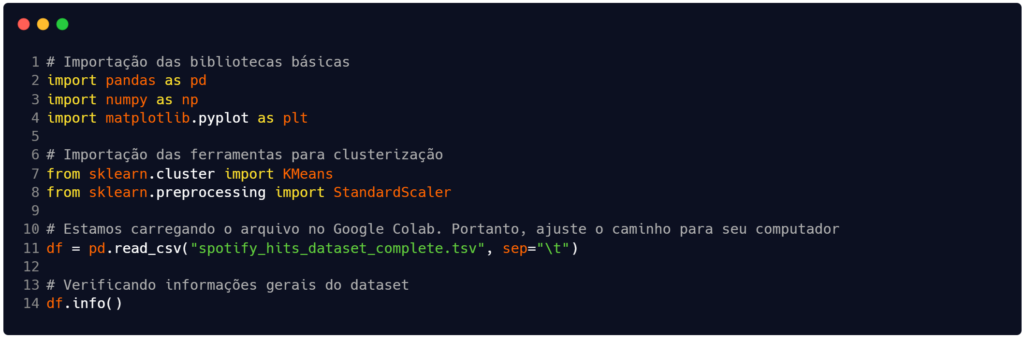
Fonte: Autoria própria.
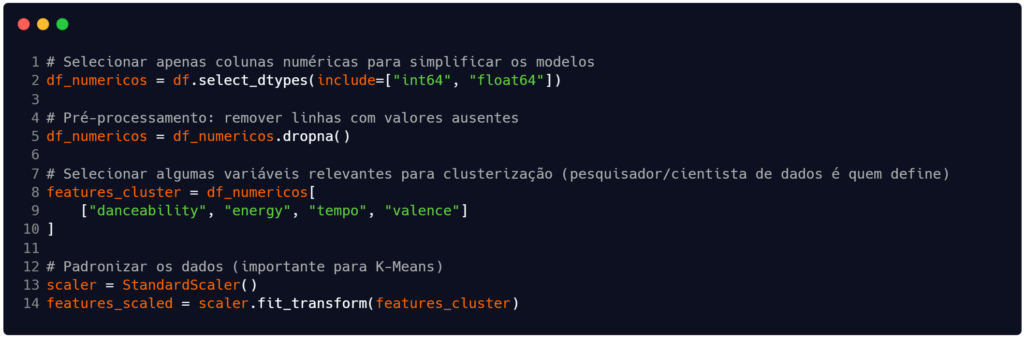
Após a leitura do arquivo e exibição da estrutura geral dele, na Figura 2 selecionamos apenas as colunas (ou atributos, ou variáveis) numéricas para trabalhar e inserimos elas na dataframe df_numericos (linha 2). Neste dataframe realizamos um pré-processamento simples para eliminar campos ausentes (linha 5).
Em seguida, criamos o conjunto de variáveis relevantes para a clusterização e o colocamos na estrutura features_cluster. A escolha de quais atributos utilizar é uma decisão do pesquisador ou do cientista de dados, que possuem o conhecimento sobre o assunto que está sendo tratado na base de dados. Para este exemplo escolhemos as variáveis 'danceability', 'energy', 'tempo' e 'valence'.
Finalizando este bloco do código, executamos uma padronização dos atributos relevantes para o agrupamento (linhas 13 e 14). Este passo é importante para uma boa execução do algoritmo K-means.
Fonte: Autoria própria.
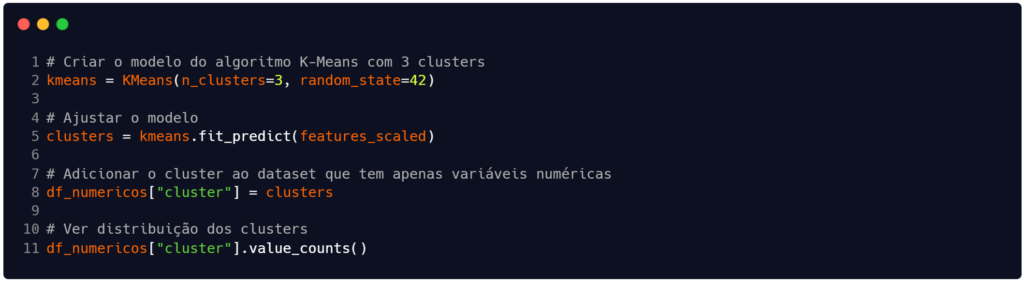
Com as variáveis relevantes definidas e padronizadas, criamos – na linha 2 da Figura 3 – o modelo de clusterização usando o algoritmo K-means e treinamos ele para buscar 3 grupos (ou clusters). Na linha 5 ajustamos o modelo para, enfim, na linha 8 adicionarmos a informação dos clusters na estrutura df_numericos. No final do código (linha 11) optamos por apresentar a contagem dos registros em cada grupo. O resultado que recebemos está contido na Tabela 1.
Fonte: Autoria própria.
| Rótulo do cluster (grupo) | Quantidade de registros no cluster |
| 0 | 546 |
| 2 | 406 |
| 1 | 332 |
Fonte: Autoria própria.
Os resultados disponíveis na Tabela 1 apreesntam a distribuição quantitativa das amostras entre os três grupos definidos (k = 3). O algoritmo K-Means opera particionando o conjunto de dados em k grupos distintos, iterativamente minimizando a inércia, ou seja, a soma dos quadrados das distâncias intra-cluster, conforme a definição clássica proposta por MacQueen (1967). O resultado será uma série de dados indicando quantas músicas foram alocadas nos clusters 0, 1 e 2, permitindo verificar se o agrupamento resultou em conjuntos equilibrados ou se há predominância de um perfil musical específico.
Em termos práticos, os números resultantes representam perfis sonoros consolidados. Ao analisar as features escolhidas (danceability, energy, tempo, valence), é provável que um dos clusters concentre faixas com alta energia e valência (músicas “felizes” e rápidas), enquanto outro agrupe faixas mais lentas e acústicas. A saída do código é, portanto, o diagnóstico da heterogeneidade do nosso dataset, segmentado estatisticamente pela variância dessas características acústicas.
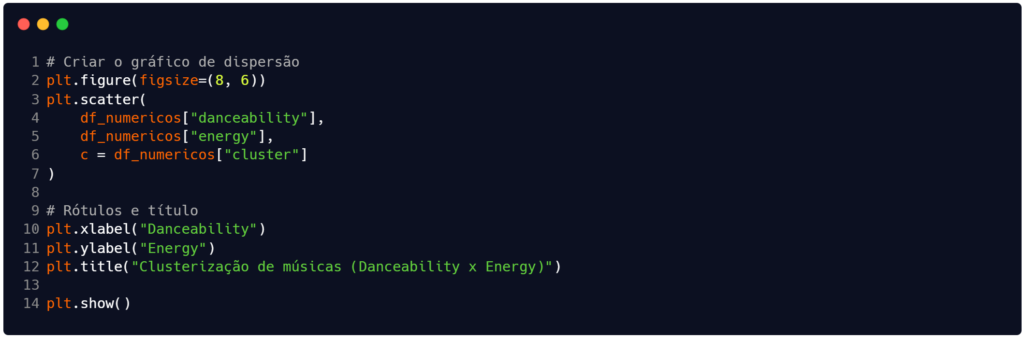
Para ampliar nossas análises sobre os clusters, vamos complementar o código criado até aqui. Na Figura 4 estamos criando um gráfico de dispersão que apresenta uma projeção bidimensional dos agrupamentos realizados em um espaço original de quatro dimensões. Como o algoritmo K-Means utilizou quatro variáveis para calcular as distâncias e formar os clusters, é natural que ocorram sobreposições visuais entre as cores neste gráfico de dispersão, uma vez que as dimensões tempo e valence não estão representadas nos eixos, mas influenciaram a separação dos grupos (Faceli et al., 2011).
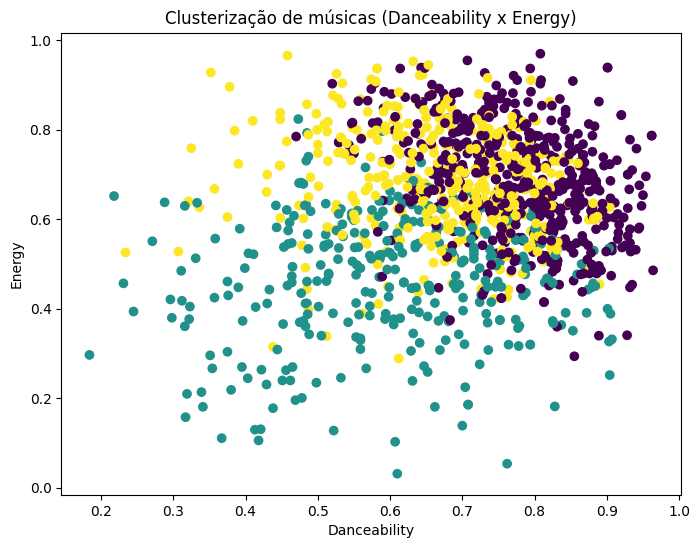
A visualização da Figura 5 – resultado do código na Figura 4 – permite diagnosticar a correlação entre a “dançabilidade” e a energia das faixas dentro de cada cluster. Se as cores estiverem bem separadas, isso indica que essas duas variáveis foram determinantes para a clusterização; caso contrário, a mistura de cores sugere que a distinção entre os grupos depende mais das variáveis ocultas ou que os limites entre os perfis musicais não são lineares nessas duas dimensões específicas (Han; Kamber; Pei, 2012).
Fonte: Autoria própria.
Fonte: Autoria própria.
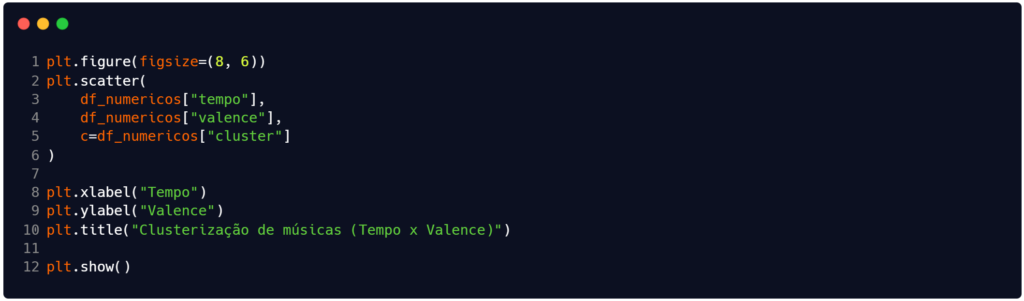
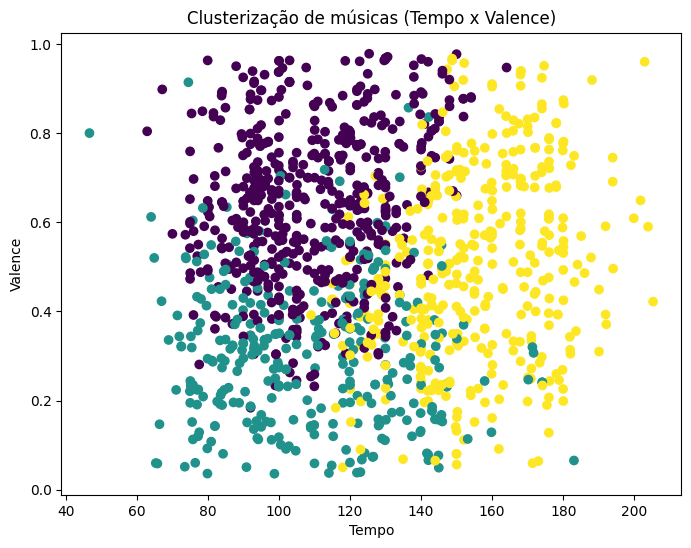
Avançamos o código mais um pouco e obtemos o disposto na Figura 6. Este código vai gerar o resultado visto o gráfico da Figura 7. Este gráfico complementa a análise anterior ao projetar os agrupamentos nas dimensões de andamento (tempo) e positividade musical (valence). A visualização permite verificar se a velocidade da música possui correlação direta com o “humor” da faixa dentro dos clusters formados. Caso as cores apareçam misturadas neste plano, mas separadas no gráfico anterior, deduz-se que as variáveis danceability e energy foram mais determinantes para a discriminação dos grupos do que o par tempo e valence (Wilke, 2019).
É importante destacar que o algoritmo K-Means calculou as distâncias em um espaço tetradimensional padronizado, buscando minimizar a variância intra-cluster globalmente. Portanto, a visualização bidimensional é apenas uma “fatia” da realidade dos dados; sobreposições visuais indicam que a fronteira de decisão entre os clusters depende da interação complexa entre todas as quatro variáveis simultaneamente, e não apenas destas duas isoladamente (Faceli et al., 2011).
Fonte: Autoria própria.
Fonte: Autoria própria.
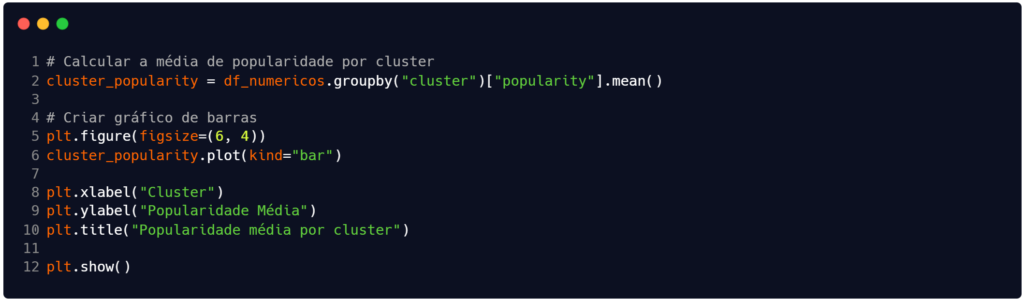
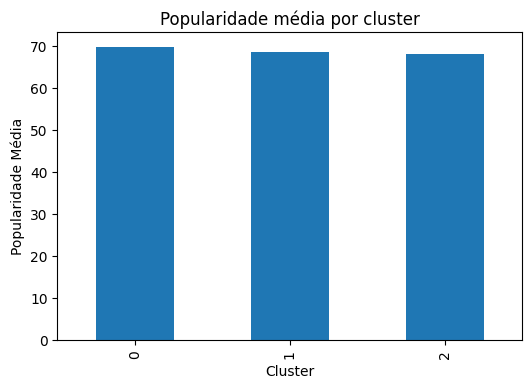
Seguindo mais um pouco em nossas análises, partimos para a inclusão do código na Figura 8. A saída gerada por este código – disponível na Figura 9 – tem como objetivo verificar se existe uma relação direta entre os perfis acústicos formados pelo algoritmo K-Means e a aceitação comercial das faixas. Ao calcular a média da variável popularity para cada cluster, o gráfico de barras permite identificar se determinado conjunto de características sonoras (como, por exemplo, alta energia e dançabilidade) tende a resultar em músicas estatisticamente mais populares, transformando a segmentação técnica em um insight estratégico de negócio (Provost; Fawcett, 2013).
Mas atenção! Precisamos observar que a variável popularity não foi utilizada na etapa de treinamento do modelo, servindo aqui como um atributo de perfilamento a posteriori. Segundo Han, Kamber e Pei (2012), a caracterização dos agrupamentos utilizando variáveis externas – aquelas que não influenciaram o cálculo da distância Euclidiana – é uma metodologia fundamental para validar a utilidade prática da clusterização e atribuir significado semântico aos grupos no mundo real.
Fonte: Autoria própria.
Fonte: Autoria própria.
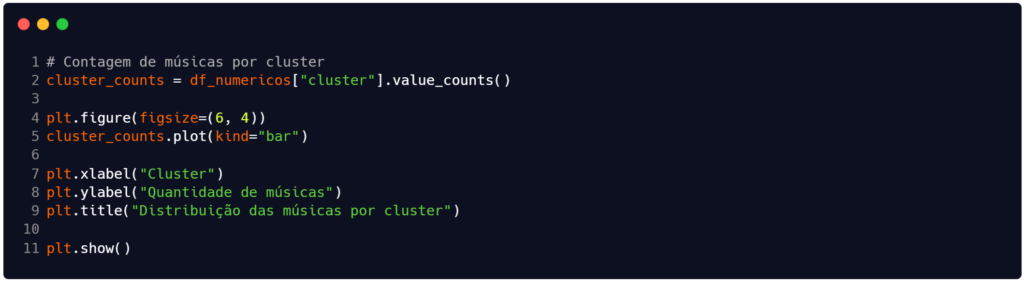
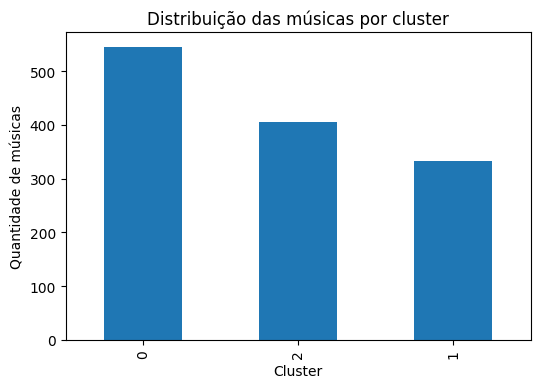
Finalmente, vamos encerrar este código e as análises. Na Figura 10 temos a última parte de código que pretendemos apresentar neste artigo. Ela vai gerar o gráfico disponível na Figura 11, que serve para traduzir visualmente a contagem numérica realizada anteriormente (ver o final da Figura 3), permitindo uma inspeção imediata sobre o equilíbrio (ou desequilíbrio) entre os grupos formados.
A distribuição apresentada serve como um diagnóstico da estrutura natural do dataset. Se as barras apresentarem alturas semelhantes, o algoritmo encontrou grupos com densidades comparáveis; caso contrário, a disparidade revela que determinados perfis musicais são muito mais frequentes que outros na amostra analisada. Segundo Faceli et al. (2011), essa verificação é uma etapa crítica pós-processamento, garantindo que nenhum perfil gerado seja estatisticamente irrelevante para a tomada de decisão.
Fonte: Autoria própria.
Fonte: Autoria própria.
Antes de encerrarmos, mais um disclaimer: este código não foi construído pensando em ser otimizado, em ser um modelo de agrupamento altamente eficiente ou aplicar determinada boa prática de programação. É bem possível que você encontre pontos que podem ser melhorados no código e, neste caso, recomendamos que pratique aplicando-os para melhorar o modelo e algoritmo como um todo.
Considerações finais
A técnica de agrupamento (clustering) constitui uma ferramenta importante na Ciência de Dados para a descoberta de conhecimento em bases não rotuladas. Ao permitir a identificação de estruturas naturais e a redução da complexidade dos dados, a técnica oferece uma base sólida para análises exploratórias profundas, transformando dados brutos em informações organizadas.
Portanto, conforme você avançar em seus estudos, a compreensão profunda desses algoritmos e de seus fundamentos estatísticos será importante para enfrentar os desafios cada vez mais complexos do mercado atual.
Obrigado pela leitura e bons estudos.
Referências
ANDERBERG, M. R. Cluster Analysis for Applications. New York: Academic Press, 1973.
FACELI, K. et al. Inteligência Artificial: Uma Abordagem de Aprendizado de Máquina. Rio de Janeiro: LTC, 2011.
HAN, J.; KAMBER, M.; PEI, J. Data Mining: Concepts and Techniques. 3. ed. Waltham: Morgan Kaufmann, 2012.
HARTIGAN, J. A. Clustering Algorithms. New York: John Wiley & Sons, 1975.
JAIN, A. K.; MURTY, M. N.; FLYNN, P. J. Data clustering: a review. ACM Computing Surveys, New York, v. 31, n. 3, p. 264-323, set. 1999.
MACQUEEN, J. B. Some methods for classification and analysis of multivariate observations. Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, v. 1, p. 281-297, 1967.
PROVOST, F.; FAWCETT, T. Data Science for Business: What You Need to Know about Data Mining and Data-Analytic Thinking. Sebastopol: O’Reilly Media, 2013.
SOKAL, R. R.; SNEATH, P. H. A. Principles of Numerical Taxonomy. San Francisco: W. H. Freeman, 1963.
WILKE, C. O. Fundamentals of Data Visualization: A Primer on Making Informative and Compelling Figures. Sebastopol: O’Reilly Media, 2019.