Estatística Descritiva em Python
A construção de modelos de machine learning eficazes não começa com a escolha do algoritmo, mas sim com a compreensão profunda dos dados. Nesse sentido, a estatística descritiva atua como uma ferramenta primária para organizar, resumir e descrever as características essenciais de um conjunto de dados, transformando observações brutas em informações inteligíveis.
O que são estatísticas descritivas?
A estatística descritiva consiste no conjunto de técnicas destinadas a sintetizar dados numéricos e categóricos. O objetivo não é fazer inferências sobre uma população maior, mas apresentar os dados de forma que permitam uma análise objetiva da amostra atual.
Segundo Bussab e Morettin (2017), a estatística descritiva preocupa-se em organizar e descrever os dados através de tabelas, gráficos e medidas resumo. Estas medidas dividem-se, basicamente, em:
- Medidas de Posição (ou de Tendência Central): média, mediana e moda são algumas medidas que indicam onde os dados se concentram.
- Medidas de Dispersão (ou de Variabilidade): variância, desvio padrão e amplitude indicam o grau de variabilidade dos dados.
- Medidas de Forma: assimetria e curtose descrevem a forma da distribuição dos dados.
Para que servem?
A principal utilidade destas estatísticas reside na Análise Exploratória de Dados (AED). Tukey (1977), considerado como o “pai” da AED, argumenta que é necessário olhar para os dados para ver o que eles parecem dizer, em vez de apenas confirmar o que já acreditamos ser verdade.
Assim, podemos sintetizar que as estatísticas descritivas servem para:
- Detectar padrões: identificar tendências, sazonalidades ou agrupamentos naturais nos dados.
- Validar a qualidade: verificar a consistência das variáveis (ex.: uma idade negativa ou um salário nulo).
- Simplificar a complexidade: reduzir milhares de linhas de dados a alguns indicadores chave que representam o comportamento global da variável.
Ignorar a etapa descritiva e avançar diretamente para a modelagem é um erro comum que compromete a performance preditiva. A execução prévia destas análises oferece benefícios críticos.
Um dos benefícios é a possibilidade de identificar e tratar valores atípicos (ou outliers), que podem distorcer significativamente o treino de um modelo, especialmente em algoritmos sensíveis à média e à distância Euclidiana, como a Regressão Linear ou K-Means. Hair et al. (2009) alertam que a presença de outliers pode alterar as relações entre variáveis, levando a resultados enviesados e a uma generalização pobre do modelo.
Outro ponto positivo em realizar análises descritivas antes da modelagem é a verificação de pressupostos estatísticos. Muitos algoritmos de machine learning assumem que os dados seguem uma distribuição normal (Gaussiana). As estatísticas descritivas (como assimetria e curtose) e histogramas permitem verificar essa normalidade. Se os dados não forem normais, transformações prévias, como a logarítmica ou o Box-Cox, podem ser necessárias para atender aos requisitos matemáticos do algoritmo (Hair et al., 2009).
Por fim, podemos destacar a seleção de features (variáveis) como outro ponto benéfico. Ao analisar a correlação – uma medida descritiva de associação – entre variáveis, o cientista de dados pode identificar colinearidade. Variáveis altamente correlacionadas podem fornecer a mesma informação ao modelo, causando redundância e overfitting.
Exemplo de código
Para exemplificarmos a utilização de estatísticas descritivas em um dataset real, seguiremos com o conjunto 'spotify_artists_info_cleaned.csv' obtido no artigo que escrevemos sobre limpeza de dados (clique aqui para ler). Ao final da limpeza realizada, salvamos o conjunto pré-processado em um arquivo csv que pode ser baixado aqui.
Na Figura 1 estamos importando as bibliotecas que iremos utilizar durante o código, lendo o arquivo csv na linha 5 e apresentando algumas informações sobre o dataset na linha 7. Lembrando que para fazermos este código, utilizamos o ambiente Python + Jupyter Notebook do Google Colab. Logo, o caminho absoluto para encontrar o arquivo ficou simplificado (linha 5).
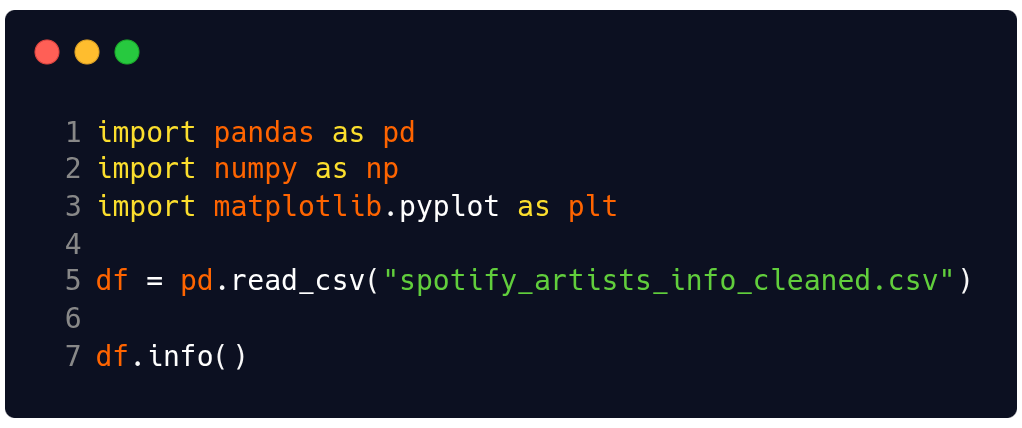
Fonte: Autoria própria.
Seguindo o código, optamos por verificar se havia ou não algum campo nulo (NaN) no dataset. Obviamente não há, pois este arquivo foi pré-processado previamente por nós e os campos nulos foram preenchidos. (Obs: recomendamos a leitura indicada antes de começarmos este exemplo). Na linha 6 da Figura 2, estamos verificando quais são os tipos dos campos.
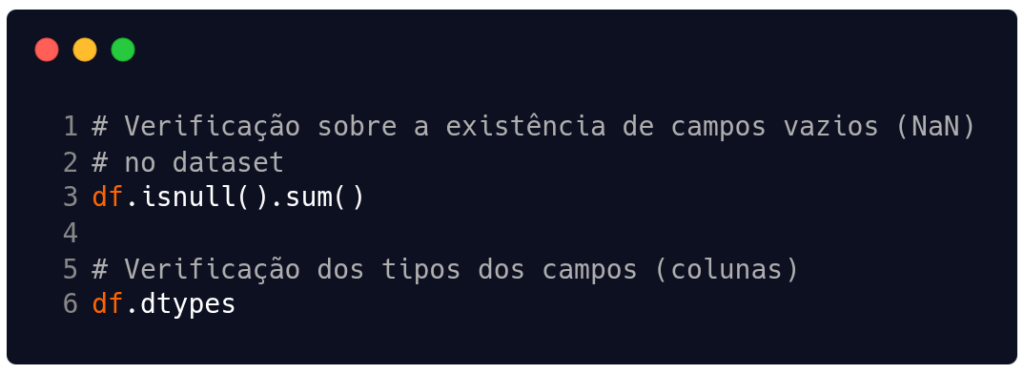
Fonte: Autoria própria.
Com o resultado da linha 6 na Figura 2, descobrimos que os campos 'followers' e 'popularity' são do tipo int64 e float64, respectivamente. Portanto, eles são ótimos atributos para as análises de estatística descritiva que queremos aplicar. Nas linhas 2 e 5 da Figura 3 estamos usando os métodos describe() e agg() para obter a média, a mediana, o desvio padrão, o mínimo e o máximo das colunas numéricas.
Falta obtermos algumas métricas de forma para as variáveis. Por isso, a partir da linha 9 na Figura 3 calculamos e imprimimos a assimetria e a curtose de 'followers' e 'popularity'. Agora, temos as medidas de tendência central, de dispersão e de forma dos dados.
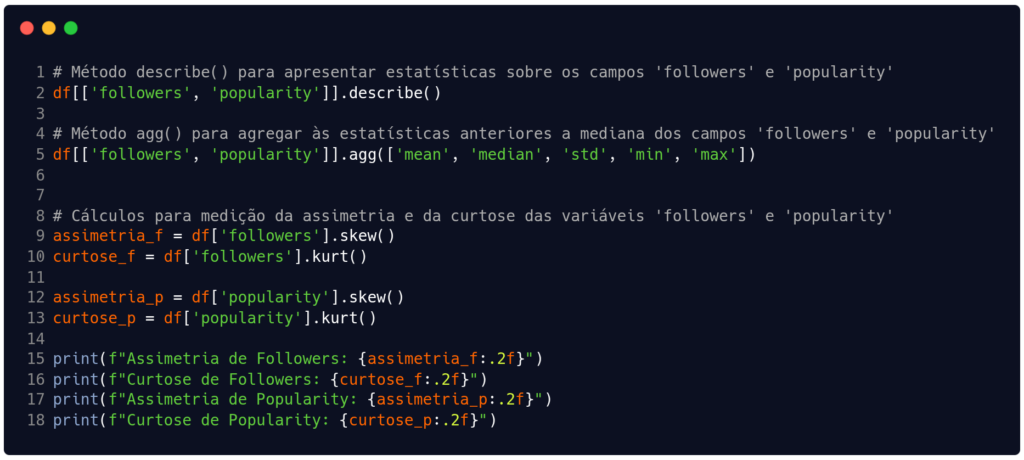
Fonte: Autoria própria.
Com os números em mãos, partiremos para observar gráficos, mais especificamente o histograma. Este gráfico é interessante pois permite que analisemos visualmente a distribuição dos dados na variável. Na Figura 4 estamos construindo e plotando o histograma dos dados presentes no campo 'followers'. O resultado dessa plotagem está na Figura 5.

Fonte: Autoria própria.
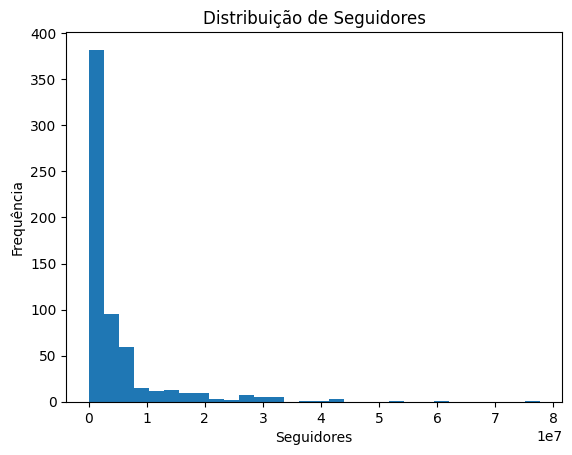
Fonte: Autoria própria.
O histograma da Figura 5 apresenta uma assimetria positiva acentuada (assimetria à direita). Isso é caracterizado por uma grande concentração de observações em valores baixos (lado esquerdo do eixo x). Em termos práticos, isso significa que a maioria dos músicos tem poucos seguidores, enquanto uma pequena parcela deles possui uma quantidade elevada de seguidores (outliers).
A distribuição também indica alta curtose positiva (leptocúrtica), evidenciada por um pico muito elevado próximo aos valores baixos, caudas pesadas, principalmente à direita e maior probabilidade de valores extremos quando comparada a uma distribuição normal.
A análise visual corresponde aos valores numéricos que obtivemos por meio do código na Figura 3 e isso é um bom sinal.
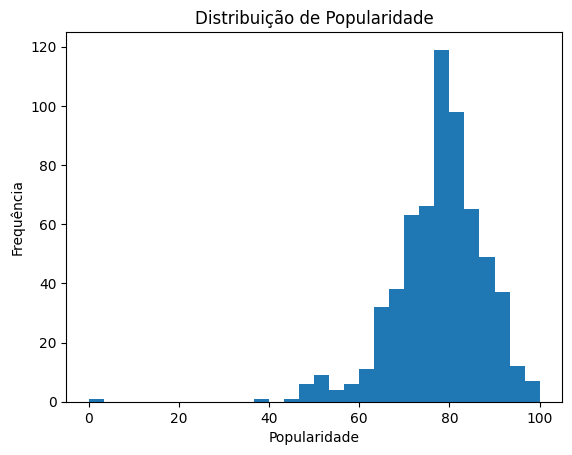
Falta plotarmos o histograma da variável 'popularity'. Na Figura 6 temos o código para isso, enquanto na Figura 7 apresentamos o resultado obtido.

Fonte: Autoria própria.
Fonte: Autoria própria.
Sob a ótica estatística, o histograma da Figura 7 apresenta um comportamento distinto do apresentado na Figura 5 e se aproxima de uma distribuição mais “bem comportada”.
A distribuição apresenta leve assimetria negativa (à esquerda), caracterizada por uma cauda mais longa em direção aos valores menores e poucas observações em valores muito baixos (inclusive com um possível valor extremo próximo de zero). Essa assimetria é fraca, o que sugere que a distribuição é quase simétrica.
Quanto à curtose, o formato indica uma distribuição aproximadamente mesocúrtica, isto é, comportamento próximo ao de uma distribuição normal, especialmente quando desconsiderados possíveis outliers isolados.
Mais uma vez a análise visual está coerente com os valores numéricos que encontramos na resposta do código apresentado na Figura 3.
Análises extras
A partir de agora, os códigos que faremos não são obrigatórios para análises descritivas, apenas servem para desbravarmos mais os dados que temos disponíveis.
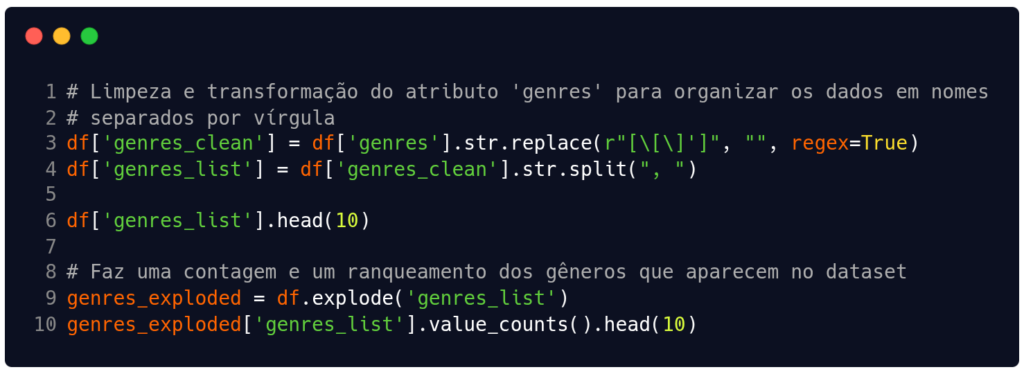
Na Figura 8 estamos limpando e transformando os valores que estão dentro do campo 'genres' para que possamos apresentar uma contagem absoluta de quantas vezes os nomes dos gêneros aparecem no banco de dados. Veja, o atributo 'genres' não é numérico, por isso não fizemos cálculos para média, desvio padrão etc. Assim, optamos por fazer essa transformação que nos permitirá obter uma frequência absoluta (contagem) dos valores (uma estatística descritiva mais simples).
Fonte: Autoria própria.
O código na Figura 8 devolve como resposta um ranqueamento com os 10 gêneros que mais aparecem na lista de frequências absolutas. Como podemos observar na Tabela 1, o estilo pop e suas variações aparecem bastante no dataset.
| Nome do gênero | Frequência Absoluta |
| pop | 147 |
| dance pop | 91 |
| rap | 78 |
| pop rap | 72 |
| pop dance | 67 |
| trap latino | 65 |
| trap | 59 |
| reggaeton | 56 |
| post-teen pop | 54 |
| latin | 53 |
Fonte: Autoria própria.
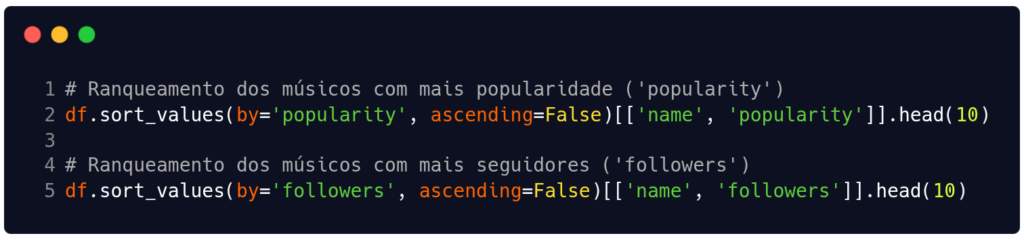
Chegando na reta final de nosso código, optamos por ranquear os 10 músicos com mais seguidores e mais popularidade, apenas para fins de observação pessoal mesmo. Considere essa parte como mais um bônus de exploração na base de dados. Nas linhas 2 e 5 da Figura 9 ordenamos os valores e pedimos para o método sort_values apresentar os resultados com base nas colunas 'popularity' e 'followers'. Os resultados dessas linhas podem ser vistos nas Tabelas 2 e 3.
Fonte: Autoria própria.
| Músicos | Índice de popularidade |
| Drake | 100.0 |
| Bad Bunny | 99.0 |
| The Weeknd | 98.0 |
| Taylor Swift | 98.0 |
| Juice WRLD | 98.0 |
| BTS | 97.0 |
| Ariana Grande | 97.0 |
| Myke Towers | 96.0 |
| J Balvin | 96.0 |
| Dua Lipa | 95.0 |
Fonte: Autoria própria.
| Músicos | Quantidade de seguidores |
| Ed Sheeran | 77681514 |
| Ariana Grande | 59767861 |
| Drake | 53685479 |
| Justin Bieber | 43582165 |
| Eminem | 42607669 |
| Rihanna | 41775923 |
| Billie Eilish | 40754854 |
| Taylor Swift | 37852182 |
| Imagine Dragons | 33179961 |
| Queen | 32828442 |
Fonte: Autoria própria.
A partir dos valores contidos nas Tabelas 2 e 3, verificamos que possuir um alto índice de popularidade não é sinal obrigatório para uma alta quantidade de seguidores e vice-versa. Essa observação pode gerar mais detalhamentos e explorações por parte do cientista de dados. Então, use sua criatividade para explorar ambos os atributos e buscar padrões a partir da relação entre eles.
Considerações finais
A estatística descritiva não é apenas uma formalidade acadêmica; é um pré-requisito técnico para a integridade da modelagem. Como sugere a literatura, compreender a distribuição e a variabilidade dos dados é o passo que separa uma análise robusta de uma aplicação cega de algoritmos.
Para conhecer melhor cada medida descritiva, você pode ler estes artigos sobre estatística descritiva aqui no site: Medidas de Tendência Central, Medidas de Dispersão e Medidas de Forma.
Obrigado pela leitura e bons estudos.
Referências
BUSSAB, W. O.; MORETTIN, P. A. Estatística Básica. 9ª ed. São Paulo: Saraiva, 2017.
HAIR, J. F. et al. Multivariate Data Analysis. 7ª ed. Upper Saddle River: Prentice Hall, 2009.
TUKEY, J. W. Exploratory Data Analysis. Reading: Addison-Wesley, 1977.


