Pré-processamento de dados: Redução dos dados
A Ciência de Dados tem como objetivo principal a extração de informações úteis a partir de dados que servirão como embasamento para tomadas de decisão. Contudo, para que essa extração seja realizada com qualidade, os dados brutos devem ser submetidos a um processo de pré-processamento.
A qualidade dos dados é um pré-requisito importante para que as informações descobertas sejam realmente significativas. Entretanto, no mundo real, os dados costumam ser incompletos, inconsistentes, ruidosos e, muitas vezes, estão em um formato inutilizável ou em diversas fontes diferentes (Pimentel et al., 2021). Logo, a etapa de pré-processamento consiste em ajustar os dados para que sirvam como entrada para os processos de análise posteriores.
O trabalho de pré-processamento geralmente ocorre com as seguintes etapas: Limpeza de Dados, Integração de Dados, Transformação de Dados e Redução de Dados (Pimentel et al., 2021). Essas etapas não são mutuamente exclusivas e dependem do conjunto de dados em análise.
Disclaimer 1: Neste artigo, vamos tratar apenas da redução dos dados. As demais etapas podem ser encontradas nestes artigos do site: limpeza, integração e transformação.
Disclaimer 2: Este artigo é voltado para um público totalmente iniciante em Introdução a Ciência de Dados. Portanto, não focaremos na explicação matemática das técnicas. Para maior aprofundamento, recomenda-se o conhecimento de Álgebra Linear e/ou Estatística.
O que é a Redução de Dimensionalidade?
A redução de dimensionalidade é uma etapa de pré-processamento que se refere a um conjunto de técnicas que têm como objetivo reduzir a dimensionalidade (colunas) de observações (linhas) com base em sua estrutura de dependência (Morettin e Singer, 2022). O propósito central é obter poucos componentes, que consigam conservar, pelo menos de forma aproximada, a estrutura de covariância do conjunto de dados original.
Quando utilizá-la?
Ela é bastante utilizada em conjuntos de dados que apresentam um grande número de variáveis (muitas colunas). Isso se torna especialmente relevante em estruturas de dados onde o número de unidades amostrais (n) é muito menor do que o número de variáveis (p), denotado pela expressão n ≪ p (Pimentel et al., 2021). Nesses casos, os dados têm alta dimensão e requerem procedimentos especiais. Em outras palavras, as técnicas de redução de dimensionalidade garantem uma diminuição no tamanho dos dados ao agregar-se ou eliminar-se recursos redundantes.
A necessidade de aplicar essas técnicas surge principalmente para enfrentar os desafios de gerenciamento e processamento de dados, que consomem tempo, esforço e recursos, especialmente com grandes volumes e alta dimensionalidade.
Principais vantagens
Conforme apontado por Pimentel et al. (2021) e Morettin e Singer (2022), as três principais vantagens que podemos obter ao aplicar-se as técnicas de redução no pré-processamento são:
1. a redução do custo de recursos computacionais: com a diminuição do tamanho dos dados, seja agregando ou eliminando características redundantes, o processo se dá de forma mais eficiente e rápida.
2. a melhoria em análises subsequentes: os componentes obtidos podem substituir as variáveis (colunas) originais em análises posteriores, servindo como novas variáveis preditoras em modelos de regressão, por exemplo.
3. o ajuste no tratamento de modelos complexos: em dados de alta dimensão, o ajuste de modelos matemáticos lineares pode ser tratado por meio de técnicas de redução de dimensionalidade ou regularização.
Principais técnicas de redução
Três das técnicas mais utilizadas para a redução de dimensionalidade são: a Análise de Componentes Principais (PCA), a Análise Fatorial e a Análise de Componentes Independentes.
Análise de Componentes Principais (PCA)
A Análise de Componentes Principais (do inglês, Principal Component Analysis – PCA) é vista na literatura como uma das técnicas mais simples e mais comum para redução de dimensionalidade. É um algoritmo não supervisionado que busca desenvolver métodos para combinar variáveis e, assim, reduzir sua dimensionalidade (Morettin e Singer, 2022).
De acordo com Morettin e Singer (2022), o PCA busca sequencialmente combinações lineares (componentes principais) das variáveis de forma que a primeira combinação corresponda à maior parcela de sua variabilidade, a segunda à segunda maior, e assim por diante. Além disso, essas componentes devem ser não correlacionadas entre si. Para isso, ela utiliza uma estrutura matemática que inclui os autovetores da matriz de covariâncias amostral (S) — ou da matriz de correlações amostrais (R) — e suas variâncias são os autovalores correspondentes.
Análise Fatorial
A Análise Fatorial tem como objetivo obter um conjunto de fatores que permita identificar características comuns a um conjunto de variáveis, ou seja, obter combinações lineares ortogonais das variáveis originais que sejam interpretáveis como variáveis latentes. A técnica visa modelar as relações entre as variáveis observadas em termos de fatores latentes comuns, juntamente com erros.
Análise de Componentes Independentes
A Análise de Componentes Independentes (do inglês Independent Component Analysis – ICA) é um método desenvolvido para obter componentes que não dependem da suposição de normalidade dos dados. Essa característica se contrapõe à Análise Fatorial, que tem resultados mais adequados sob essa condição. Assim, o ICA busca variáveis resultantes (componentes) que sejam independentes e não gaussianas (Morettin e Singer, 2022).
Dentro das principais aplicações da técnica se pode citar o processamento de sinais biomédicos, a separação de sinais de áudio e as séries temporais financeiras.
Exemplo de código utilizando PCA
Para exemplificarmos a utilização da redução de dimensionalidade em um dataset real, seguiremos com o conjunto 'spotify_artists_transformed.csv' obtido no artigo que escrevemos sobre transformação de dados (clique aqui para ler). Ao final da transformação, salvamos o conjunto pré-processado para normalizar e padronizar algumas variáveis (colunas). Vamos seguir a partir dele para realizar a redução das dimensões usando a técnica de PCA, conforme o código exposto na Figura 1.
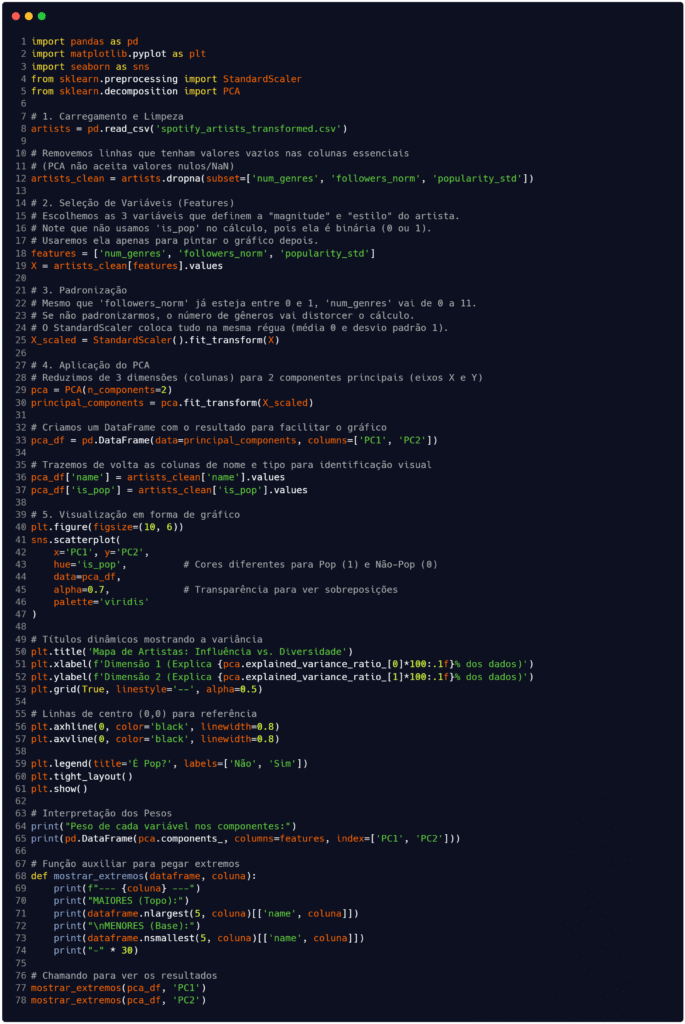
Fonte: Autoria própria.
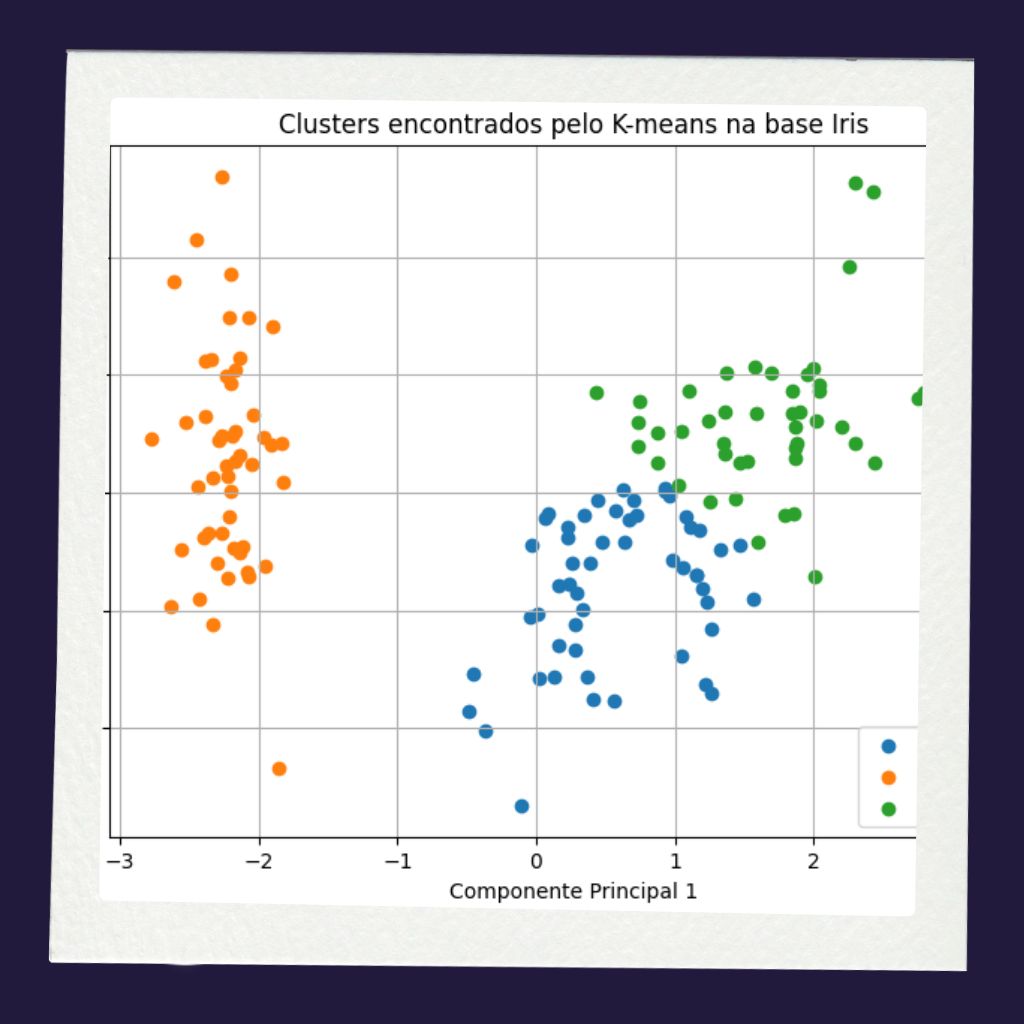
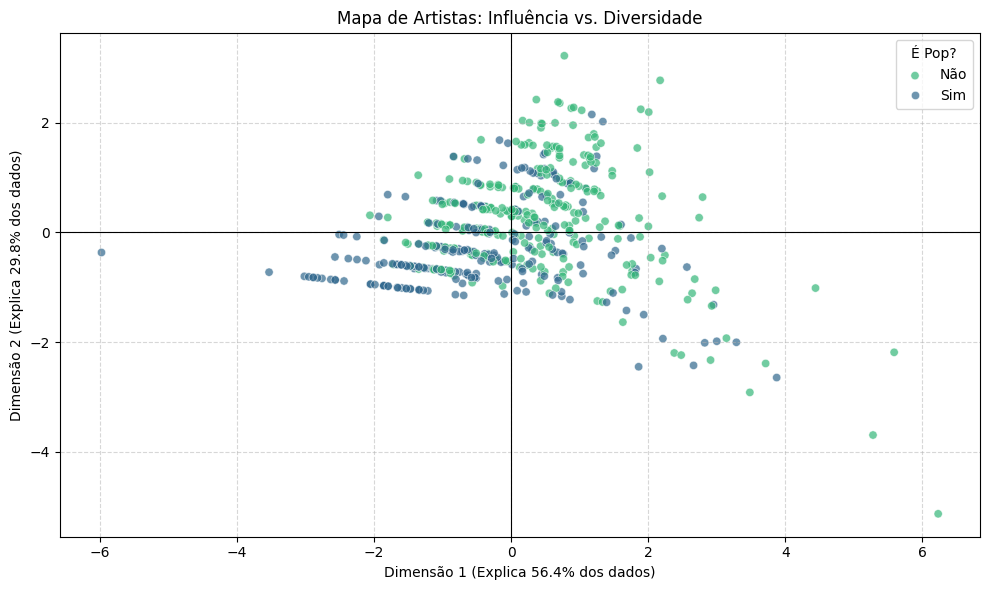
Após a execução do código, obteremos como primeiro resultado um mapa de relação entre influência e diversidade de gênero musical, apresentado na Figura 2. O eixo X (Dimensão 1) faz referência ao componente principal 1 (PC1) obtido na redução de dimensões do PCA. Observe que quanto mais à direita no gráfico, maior é o valor de PC1. Logo, os artistas posicionados mais à direita (pontos coloridos no gráfico) são mais populares e possuem mais seguidores. Este eixo indica o “tamanho do artista” na indústria da música.
Em relação ao eixo Y (Dimensão 2), a referência é ao componente principal 2, também fruto da redução. Os valores positivos (para cima no eixo) indicam artistas com elevada variabilidade de gêneros, caracterizando um perfil eclético, ao passo que valores negativos (para baixo no eixo) denotam artistas concentrados em poucos estilos, configurando o perfil de mainstream focado.
Dessa forma, enquanto o eixo horizontal mensura a magnitude absoluta da fama, o eixo vertical atua como um discriminador qualitativo, situando a diversidade estilística no topo e a especialização massificada na base do diagrama.
Fonte: Autoria própria.
Toda essa análise é a redução de dimensionalidade na prática: a simplificação dados para entender melhor o comportamento deles. Ao longo do código, transformamos 3 variáveis complexas ('num_genres', 'followers_norm', 'popularity_std') em um mapa 2D simplório que nos permita realizar afirmativas como “no canto superior direito temos artistas famosos e ecléticos em relação ao gênero musical” e “no canto inferior esquerdo temos artistas menores e mais especializados num gênero massificado”.
Além disso, é válido destacar que utilizamos a variável 'is_pop' que estava no dataset transformado original para colorir os pontos do mapa, de forma a demonstrar os artistas que tinham ou não alguma variação do estilo pop dentro dos seus estilos musicais tocados. Essa indicação se dá pelas duas cores de pontos e pela legenda no gráfico.
O segundo resultado obtido a partir do código na Figura 1 vem do trecho escrito nas linhas 64 e 65. Nelas, utilizamos o atributo pca.components_ para extrair os autovetores resultantes da decomposição espectral e organizá-los em um dataframe, permitindo a leitura dos loading scores, que são os coeficientes de correlação entre as variáveis originais e os componentes principais gerados. Os dados obtidos estão organizados na Tabela 1.
| num_genres | followers_norm | popularity_std | |
| PC1 | 0.419925 | 0.607193 | 0.674522 |
| PC2 | 0.866522 | -0.489205 | -0.099082 |
Fonte: Autoria própria.
Na análise dos pesos, observa-se que o primeiro componente (PC1) apresenta coeficientes positivos e elevados para todas as variáveis, o que o caracteriza como um índice de magnitude global, onde popularidade e diversidade crescem simultaneamente. Em contrapartida, o segundo componente (PC2) revela uma diferenciação estrutural ao atribuir um peso fortemente positivo ao número de gêneros (0.86) e negativo aos seguidores (-0.49), indicando que este eixo atua como um discriminador qualitativo que separa a diversidade musical (ecléticos) da concentração de audiência (focados).
Para finalizar, o último resultado que obtemos com o algoritmo está contido no trecho de código a partir da linha 68 até o final. Nas últimas linhas implementamos um procedimento de validação semântica do modelo, utilizando os métodos nlargest e nsmallest para isolar as observações situadas nos limites extremos de cada componente principal. Os dados retornados estão descritos na descrição a seguir:
ANÁLISE DO EIXO X (PC1): FAMA E MAGNITUDE: Quanto maior o número, maior a popularidade e alcance do artista.
TOP 5 MAIORES (gigantes da música)
- Ed Sheeran ……… 6.23
- Drake ………….. 5.59
- Ariana Grande …… 5.28
- Rihanna ………… 4.44
- Eminem …………. 3.87
TOP 5 MENORES (menos populares na amostra)
- Niack …………………….. -5.98
- Henri Rene & His Orchestra ….. -3.53
- Larry Walsh ……………….. -3.02
- Mark Linett ……………….. -2.95
- Rymez …………………….. -2.89
ANÁLISE DO EIXO Y (PC2): FOCO VS DIVERSIDADE: Números positivos indicam diversidade (muitos gêneros). Números negativos indicam foco extremo (muitos seguidores em poucos gêneros).
TOP 5 MAIORES (alta diversidade vs nicho)
- Kim Petras ……… 3.22
- Tiësto …………. 2.77
- MadeinTYO ………. 2.42
- Oliver Heldens ….. 2.38
- Kylie Minogue …… 2.36
TOP 5 MENORES (alto foco vs superstars)
- Ed Sheeran ……… -5.13
- Ariana Grande …… -3.69
- Billie Eilish …… -2.92
- Eminem …………. -2.65
- Alan Walker …….. -2.45
Essa inspeção dos outliers é interessante para traduzir as coordenadas abstratas do PCA em conceitos tangíveis, pois permite verificar se a distribuição matemática corresponde à realidade observável dos dados. Ao revelar que os valores máximos do primeiro componente pertencem a artistas de alcance global e os do segundo componente discriminam entre a diversidade de repertório e a especialização de audiência, o código confirma empiricamente a interpretação dos eixos, demonstrando que a redução de dimensionalidade preservou e organizou hierarquicamente as características fundamentais do conjunto de dados original.
Considerações finais
O pré-processamento de dados pode ser comparado a um chef preparando ingredientes antes de cozinhar uma refeição complexa. Os dados brutos são como os ingredientes crus, muitas vezes vindo com cascas (ruídos), partes estragadas (dados ausentes ou outliers) ou misturados em caixas desorganizadas (dados não integrados ou despadronizados).
A etapa da limpeza envolve descascar, lavar e descartar as partes inutilizáveis. Em seguida, a integração junta os ingredientes que deveriam estar juntos (como azeite e vinagre). Paralelamente, a transformação ajusta o formato de alguns ingredientes (por exemplo, cortar em cubos, moer ou converter unidades de medida), para que, finalmente, a redução garanta que apenas os ingredientes essenciais e mais saborosos sejam usados (eliminando excessos ou combinando temperos) e assegurando que o prato final (ou seja, o modelo analítico) tenha alta qualidade e seja confiável.
Obrigado pela leitura e bons estudos.
Referências
MORETTIN, Pedro Alberto; SINGER, Julio da Motta. Estatística e ciência de dados. 1. ed. Rio de Janeiro: LTC | Livros Técnicos e Científicos Editora Ltda., 2022.
PIMENTEL, João Felipe et al. Ciência de Dados com Reprodutibilidade usando Jupyter. In: ANDRADE, Aline M. S.; WAZLAWICK, Raul S. (Org.). Jornada de Atualização em Informática 2021. Porto Alegre: Sociedade Brasileira de Computação (SBC), 2021. Disponível em: https://books-sol.sbc.org.br/index.php/sbc/catalog/view/67/292/544-1. Acesso em: 11 nov. 2025.