Pré-processamento de dados: Limpeza de um conjunto
A Ciência de Dados tem como objetivo principal a extração de informações úteis a partir de dados que servirão como embasamento para tomadas de decisão. Contudo, para que essa extração seja realizada com qualidade, os dados brutos devem ser submetidos a um processo de pré-processamento.
A qualidade dos dados é um pré-requisito importante para que as informações descobertas sejam realmente significativas. Entretanto, no mundo real, os dados costumam ser incompletos, inconsistentes, ruidosos e, muitas vezes, estão em um formato inutilizável ou em diversas fontes diferentes (Pimentel et al., 2021). Logo, a etapa de pré-processamento consiste em ajustar os dados para que sirvam como entrada para os processos de análise posteriores.
O trabalho de pré-processamento geralmente ocorre com as seguintes etapas: Limpeza de Dados, Integração de Dados, Transformação de Dados e Redução de Dados (Pimentel et al., 2021). Essas etapas não são mutuamente exclusivas e dependem do conjunto de dados em análise.
Neste artigo, vamos tratar apenas da limpeza dos dados (data cleaning). As demais etapas podem ser encontradas nestes artigos do site: integração, transformação e redução.
Limpeza dos dados (data cleaning)
A limpeza dos dados pode ser definida como a etapa de detecção e correção de registros corrompidos ou incorretos. O objetivo final é melhorar a qualidade dos dados por meio da identificação e remoção de erros e inconsistências (Ridzuan e Wan Zaino, 2019).
Nessa etapa do pré-processamento, os problemas mais comuns e suas respectivas soluções são:
Dados ausentes (missing data)
Dados ausentes representam um obstáculo considerável para a criação da maioria dos modelos de aprendizado de máquina e outras análises. Eles ocorrem quando nenhuma informação é fornecida para um ou mais atributos ou registros. Em estruturas de dados como o pandas DataFrame da linguagem Python, são frequentemente representados como NaN (Not a Number)ou None (Pimentel et al., 2021).
Usando a função isna() em da biblioteca pandas é possível identificar e tratar esses dados. A Figura 1 apresenta um código que carrega um conjunto de dados disponível em Oliveira (2021) – clique aqui para baixar – e utiliza o método para verificar quais atributos (colunas) estão com dados ausentes, além de contar quantos dados estão faltando.
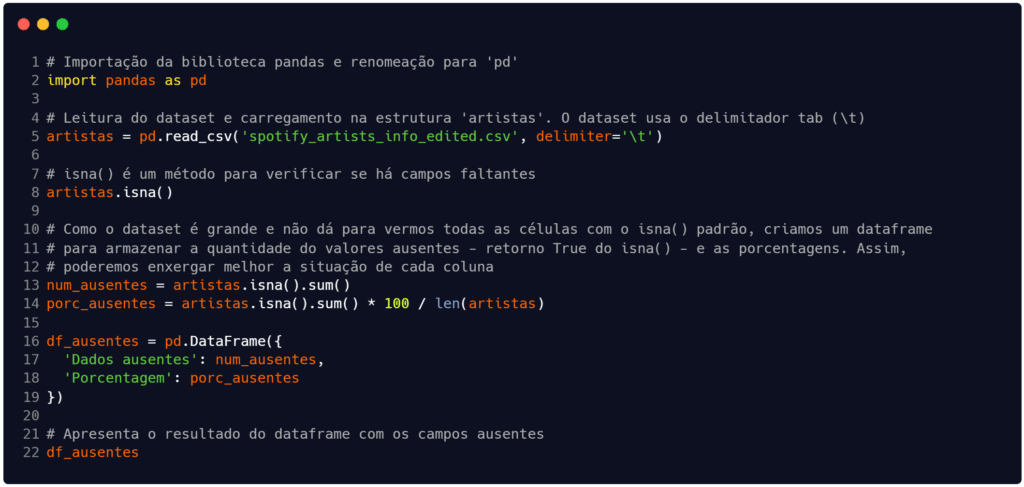
Fonte: Autoria própria.
Encontrados os dados faltantes, há duas soluções: 1) elimina-se o atributo ou o registro; e 2) imputa-se um valor para o campo ausente. A abordagem mais simples é eliminar todos os registros (linhas) ou atributos (colunas) que contenham valores ausentes. Essa técnica é vantajosa para amostras de grande volume, onde o descarte não distorce significativamente a interpretação. No pandas, o método dropna() permite essa exclusão (Oliveira, 2021). Contudo, é válido ressaltar que neste caso há o risco de se perder dados potencialmente úteis. Portanto, é preciso moderação e reflexão nessa abordagem.
A segunda opção é substituir os valores ausentes por uma estimativa, ou seja, imputar (ou preencher) valores nos campos vazios. Métodos mais simples incluem substituir o valor ausente pela média (ou mediana) dos valores presentes, como acontece quando se usa a função fillna() do pandas (Pimentel et al., 2021).
Seguindo o exemplo deste artigo, optamos por preencher os campos e não eliminá-los. Assim, conforme pode-se observar na Figura 2, estamos adotando alguns padrões para imputar valores no campos ausentes. A escolha da forma como será feita a imputação dos valores varia conforma o tipo do campo, o contexto da área e seu objetivo.
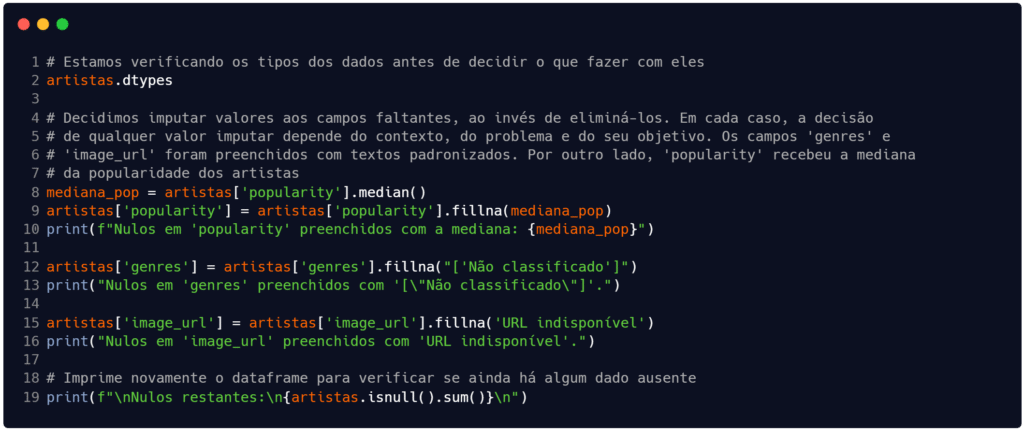
Fonte: Autoria própria.
A imputação de dados que realizamos neste exemplo é simplória e cabe ressaltar que, segundo Pimentel et al. (2021), técnicas de imputação avançadas, como imputação múltipla e modelos preditivos, podem ser mais precisas e são mais comuns. Portanto, é importante reforçar que não existe uma maneira ideal única, já que o desempenho de cada estratégia depende do conjunto de dados.
Dados ruidosos (noisy data)
Dados ruidosos são aqueles que fornecem informações adicionais, mas que não têm sentido, sendo geralmente gerados por falhas na coleta ou erros de entrada de dados. O ruído pode prejudicar os resultados das análises e modelos.
Segundo Pimentel et al. (2021), existem diversas técnicas para reduzir os efeitos de pequenos erros de observação. O método de Binning (agrupamento em bins), a regressão e os algoritmos de agrupamento de dados (clustering) são, conforme Lopes et al. (2019), algumas das opções válidas.
No caso do nosso exemplo, o único problema que podemos ter, a princípio, é o fato do atributo ‘genres‘ ser do tipo string enquanto armazena uma lista de valores. Isso pode gerar algum problema de processamento no futuro. Logo, a única limpeza que fizemos na Figura 3 foi a transformação do tipo do dado (de string para list).
Repare que o processo de limpeza que adotamos pode parecer igual a uma transformação dos dados. Contudo, eles não são iguais. Na etapa de transformação dos dados, nós alteramos diretamente a escala, ou a unidade ou os valores dos dados. Aqui, nós modificamos apenas o tipo de armazenamento do dado, sem alterar sua escala.
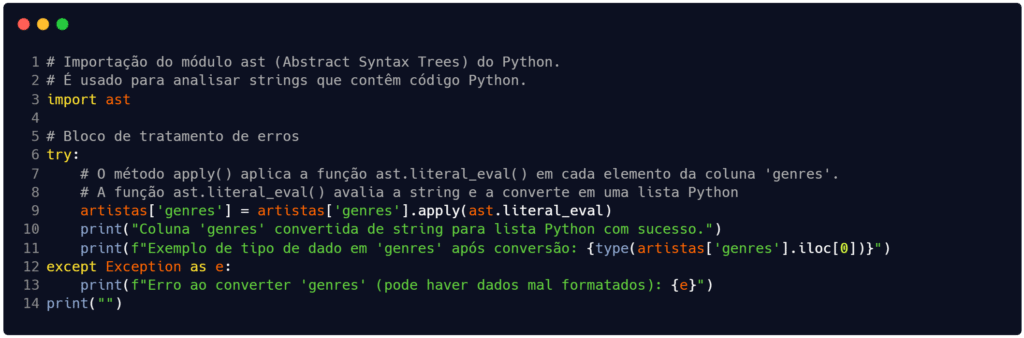
Fonte: Autoria própria.
Outliers (valores atípicos)
Os valores atípicos – ou outliers – são dados que se diferenciam de forma gritante da tendência central, frequentemente causados por erros de coleta ou entrada de dados, e que podem interferir na qualidade das análises. A presença de dados assimétricos e valores atípicos é uma ocorrência observada na prática (Morettin e Singer, 2022, p. 99).
Para solucionar este tipo de problema, primeiro devemos identificar quais são estes valores observando-se os valores máximos e mínimos das variáveis. Conforme Pimentel et al. (2021), a função describe() do Pandas e os gráficos boxplots são ferramentas comuns para esse tipo de observação.
Na Figura 4 optamos por encontrar os valores atípicos do atributo ‘followers‘. Inicialmente buscamos os intervalos interquartis do conjunto relativamente à coluna. Com isso, foi possível obter uma versão do dataframe apenas com os registros que apresentam os valores atípicos (o dataframe chamado outliers).
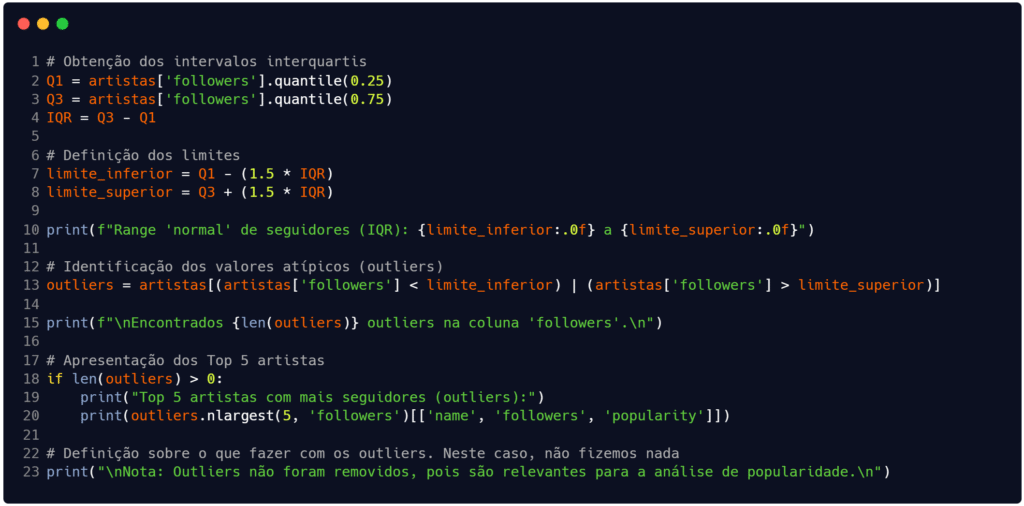
Fonte: Autoria própria.
Dados duplicados
A duplicação de dados, bastante comum durante a coleta ou entrada de dados, pode levar a conclusões incorretas, fazendo com que algumas observações pareçam mais comuns do que realmente são. A duplicação pode ser proveniente de cópias exatamente iguais de um mesmo registro ou duplicação parcial, como por exemplo, nomes próprios com ou sem abreviação (Pimentel et al., 2021).
Nestes casos, a remoção é a solução mais simples e é realizada pelo método drop_duplicates() do pandas. Em dados tabulares, é importante usar identificadores únicos (como artist_id) para confirmar se o registro deve ser descartado ou se representa entidades diferentes (Pimentel et al., 2021).
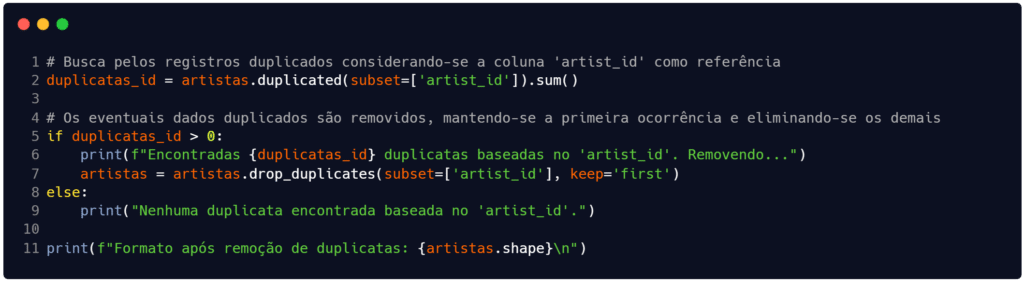
Fonte: Autoria própria.
Nossa busca por registros duplicados na Figura 5 foi bem simples. Existe a possibilidade de termos duplicatas mais difíceis de identificar, como as duplicatas parciais. Essas duplicatas são aquelas onde nem todos os atributos estão repetidos, mas apenas alguns.
Para estas situações, Pimentel et al. (2021) sugerem usar funções de similaridade de strings para encontrar cópias não idênticas.
Considerações finais
Para quem gosta de analogias para compreender o funcionamento de algo, podemos dizer que o pré-processamento de dados pode ser comparado a um chef preparando ingredientes antes de cozinhar uma refeição complexa.
Os dados brutos são como os ingredientes crus, muitas vezes vindo com cascas (ruídos), partes estragadas (dados ausentes ou outliers) ou misturados em caixas desorganizadas (dados não integrados ou despadronizados). Portanto, durante a parte da limpeza, o chef deve descascar, lavar e descartar as partes inutilizáveis.
As demais partes do pré-processamento (integração, transformação e redução) acontecem após a limpeza dos dados, de forma a garantir a qualidade final do conjunto de dados. Você pode ler sobre elas aqui: integração, transformação e redução.
Obrigado pela leitura e bons estudos.
Referências
LOPES, Gesiel Rios et al. Introdução à Análise Exploratória de Dados com Python. In: Escola Regional de Computação Aplicada à Saúde (ERCAS), Teresina: [s.n.], 2019. Disponível em: https://www.researchgate.net/publication/336778766_Introducao_a_Analise_Exploratoria_de_Dados_com_Python. Acesso em: 11 nov. 2025.
MORETTIN, Pedro Alberto; SINGER, Julio da Motta. Estatística e ciência de dados. 1. ed. Rio de Janeiro: LTC | Livros Técnicos e Científicos Editora Ltda., 2022.
OLIVEIRA, Gabriel Pereira de. spotify_artists_info_edited.csv. 2021. Arquivo de dados hospedado no GitHub. Disponível em: https://github.com/opgabriel/jai2021-jupyter/blob/main/3.Preparacao/datasets/spotify_artists_info_edited.csv. Acesso em: 21 nov. 2025.
PIMENTEL, João Felipe et al. Ciência de Dados com Reprodutibilidade usando Jupyter. In: ANDRADE, Aline M. S.; WAZLAWICK, Raul S. (Org.). Jornada de Atualização em Informática 2021. Porto Alegre: Sociedade Brasileira de Computação (SBC), 2021. Disponível em: https://books-sol.sbc.org.br/index.php/sbc/catalog/view/67/292/544-1. Acesso em: 11 nov. 2025.
RIDZUAN, F.; WAN ZAINON, W. M. N. A review on data cleansing methods for big data. Procedia Computer Science, [S. l.], v. 159, p. 731–738, 2019. DOI: 10.1016/j.procs.2019.09.198. Disponível em: https://www.sciencedirect.com/science/article/pii/S1877050919318885. Acesso em: 21 nov. 2025.