Medidas de Forma
As medidas de forma são ferramentas úteis para descrever a aparência da distribuição dos dados que temos à disposição. Elas complementam as medidas de tendência central (como média, mediana e moda) e as medidas de dispersão (como variância e desvio padrão), oferecendo um perspectiva mais ampla do conjunto de dados. As duas principais medidas de forma são a Assimetria (Skewness) e a Curtose (Kurtosis) (Naruhodo, 2025, online).
Assimetria
A assimetria (ou skewness) é uma medida que indica o grau de desvio da distribuição dos dados em relação a uma distribuição simétrica (como a curva normal, onde a média, mediana e moda coincidem). Podemos encontrar três situações possíveis:
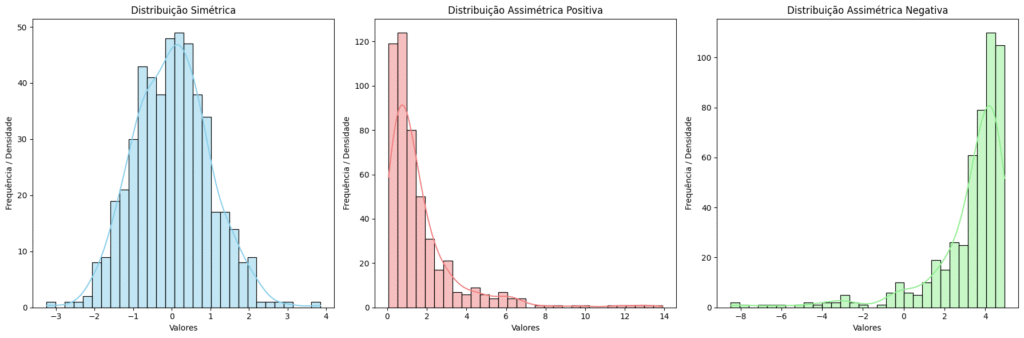
- A distribuição é simétrica: os dados estão distribuídos igualmente em torno da média. A cauda da curva é igual em ambos os lados. Neste caso,
assimetria ≈ 0. - A assimetria é positiva (ou à direita): a cauda da direita é mais longa. Isso significa que há uma concentração de dados nos valores mais baixos e alguns valores mais altos “puxando” a média para cima. Geralmente, a Média > Mediana > Moda. Podemos dizer também que a
assimetria > 0. - A assimetria é negativa (ou à esquerda): a cauda da esquerda é mais longa. Indica uma concentração de dados nos valores mais altos, com alguns valores mais baixos “puxando” a média para baixo. Geralmente, Média < Mediana < Moda. Portanto, a
assimetria < 0.
Visualmente, podemos utilizar a Figura 1 como representação para cada situação descrita.
A apresentação matemática do conceito de assimetria está descrita na Equação 1.
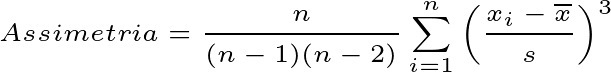
Onde:
x̄: média dos dadoss: desvio padrãon: número de observações
Ao final desse artigo apresentamos um exemplo para aplicar a equação e a interpretação do resultado de assimetria.
Curtose
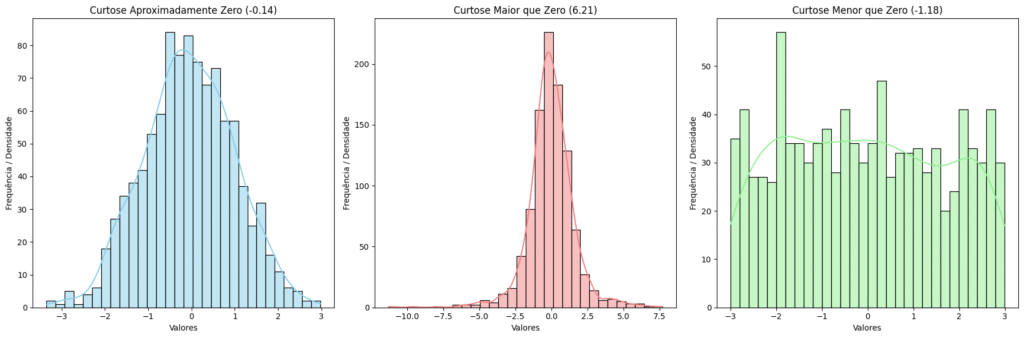
A curtose (ou kurtosis) mede o grau de achatamento da curva de distribuição em comparação com a curva normal. Ela indica a concentração de dados em torno da média e nas caudas. Em outros termos, diremos de forma vulgar que ela apresenta a altura do pico da distribuição em comparação com curva normal. Novamente, existem três possibilidades para interpretação:
- Mesocúrtica: a curva tem um achatamento semelhante à curva normal.
curtose ≈ 0(quando se usa a “curtose em excesso”, que subtrai 3 da curtose tradicional) oucurtose ≈ 3(curtose tradicional).
- Leptocúrtica: a curva é mais “pontuda” que a normal, com caudas mais pesadas. Isso significa que há mais dados concentrados próximos à média e também mais valores extremos (outliers).
curtose > 0(curtose em excesso) oucurtose > 3(curtose tradicional).
- Platicúrtica: a curva é mais “achatada” que a normal, com caudas mais leves. Indica menos concentração de dados em torno da média e menos valores extremos.
curtose < 0(curtose em excesso) oucurtose < 3(curtose tradicional).
Repare que em todas as opções existem a comparação com o valor 0 e 3. Isso acontece porque a distribuição normal padrão tem uma curtose de 3 quando usamos a fórmula não ajustada. Porém, para facilitar a interpretação, usa-se a curtose em excesso, que subtrai esse valor de referência. Logo, a comparação passa a ser com o valor 0 (zero). Muitos softwares calculam a curtose em excesso (kexcess), que é simplesmente o valor da curtose (k) menos 3 [k − 3]. Como dito anteriormente, isso é feito para que uma distribuição normal tenha curtose igual a 0, facilitando a interpretação. Na Figura 2 apresentamos exemplos de distribuições com as possíveis curtoses.
Na Equação 2 apresentamos como calcular a curtose de uma amostra.
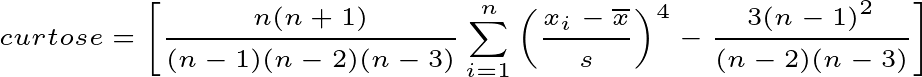
Onde:
sé o desvio padrão amostral.Xié cada valor individual no conjunto de dados.x̄é a média populacional.né o número total de observações na população.
Exemplo
Dois jovens prestes a se formarem em Análise e Desenvolvimento de Sistemas queriam saber como estava a questão salarial da carreira que eles haviam escolhido cursar na graduação. Para isso, eles coletaram os dados salariais mensais líquidos (em reais) de 10 funcionários de uma startup da cidade deles, resultando na Tabela 1.
| Desenvolvedores da startup | Salários mensais líquidos (em reais) |
| Pessoa desenvolvedora 01 | R$ 2.500,00 |
| Pessoa desenvolvedora 02 | R$ 2.800,00 |
| Pessoa desenvolvedora 03 | R$ 2.800,00 |
| Pessoa desenvolvedora 04 | R$ 3.000,00 |
| Pessoa desenvolvedora 05 | R$ 3.200,00 |
| Pessoa desenvolvedora 06 | R$ 3.350,00 |
| Pessoa desenvolvedora 07 | R$ 3.500,00 |
| Pessoa desenvolvedora 08 | R$ 4.000,00 |
| Pessoa desenvolvedora 09 | R$ 4.500,00 |
| Pessoa desenvolvedora 10 | R$ 8.000,00 |
A partir dos dados coletados e estruturados na Tabela 1, eles prepararam uma estrutura de dados em linguagem Python para realizar a descrição estatística dos salários e interpretar o conjunto.
salarios: [2500, 2800, 2800, 3000, 3200, 3350, 3500, 4000, 4500, 8000]
Em seguida, resolveram calcular à mão as medidas-resumo básicas para comparar com o resultado do código computacional. Os resultados que eles obtiveram foram:
- Média: (2500 + 2800 + 2800 + 3000 + 3200 + 3350 + 3500 + 4000 + 4500 + 8000) / 10 = 3.765
- Mediana: Com os dados ordenados, a mediana é a média dos dois valores centrais (3200 e 3350) = 3.275
- Moda: O valor que mais se repete é 2.800. Logo, esta é a moda do conjunto.
- Desvio Padrão: após calcularem a variância e aplicarem a raiz quadrada dela, eles obtiveram o valor 1603.48.
Para finalizar os testes, eles executaram o Código 1 para averiguar os valores calculados para medidas de tendência central e dispersão, além da assimetria e curtose. Ao final ainda imprimiram um gráfico dos salários (histograma) para terem melhor visão sobre a distribuição dos dados e dos resultados.
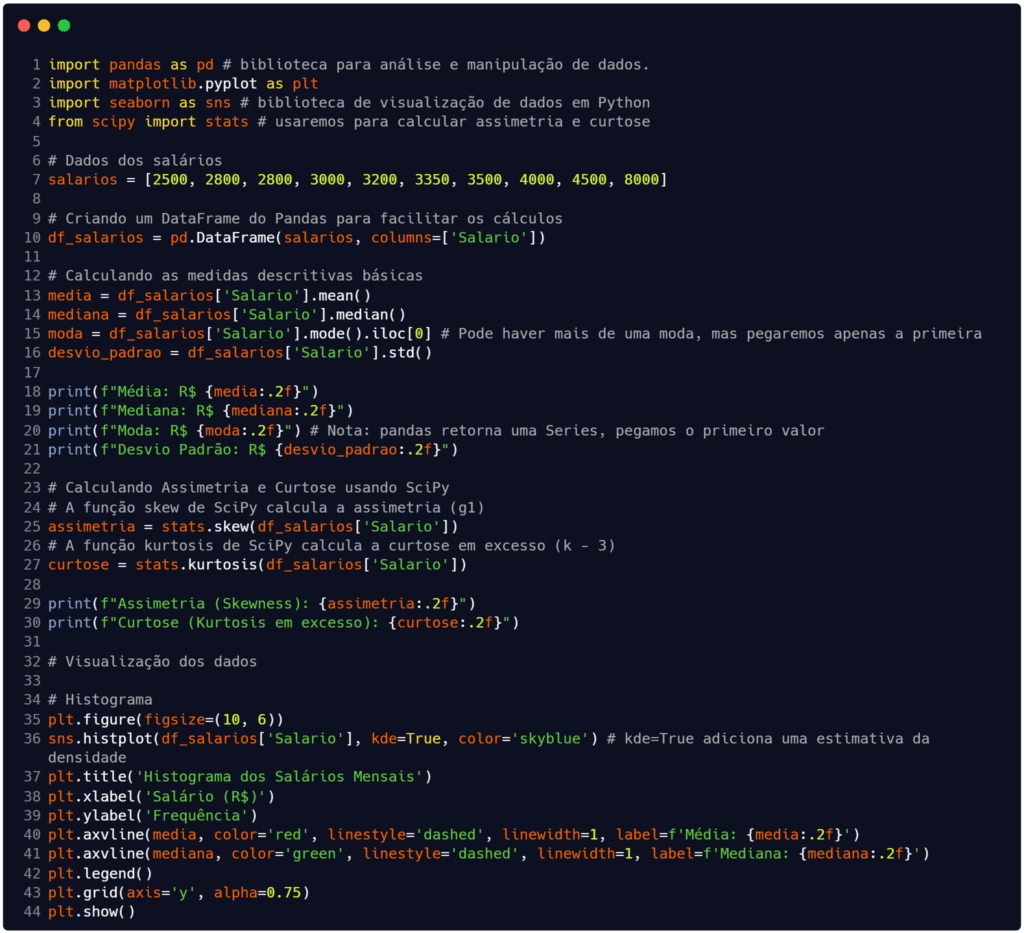
A saída obtida com o Código 1 é:
Média: R$ 3765.00
Mediana: R$ 3275.00
Moda: R$ 2800.00
Desvio Padrão: R$ 1603.48
Assimetria (Skewness): 2.04
Curtose (Kurtosis em excesso): 3.10
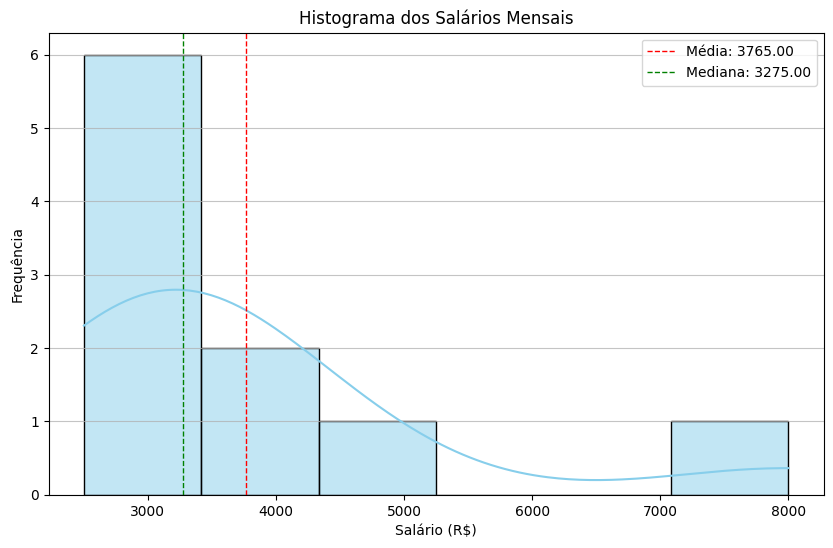
Observando o valor da assimetria vemos que o valor foi positivo (2.04), confirmando a assimetria positiva. A cauda à direita do histograma é mais longa (Figura 1). Por outro lado, a curtose também deu num valor positivo (3.10), indicando uma distribuição leptocúrtica (mais pontuda e com caudas mais pesadas que a normal), o que faz sentido devido ao valor extremo de R$ 8.000,00 no conjunto de dados.
Observação: Não faremos comentários sobre cada linha de programação dos algoritmos. Utilize os comentários nos próprios códigos como instrumento para nortear o entendimento da análise. Caso não entenda a aplicação de alguma biblioteca ou função, pesquise sobre os fundamentos da linguagem Python em si.
Considerações finais
Da mesma forma que nos artigos anteriores sobre medidas de tendência central e medidas de dispersão, neste também não buscamos encerrar o assunto. Apenas descrevemos a “superfície” do assunto, focando mais na descrição das equações, na elaboração dos conceitos e na exemplificação matemática e computacional de ambos. Recomendamos consultar outras fontes de referência, como o livro Estatística Básica, de Bussab e Morettin (2017), onde esses conceitos são explorados com mais detalhes para aprofundar seus conhecimentos.
Obrigado pela leitura e bons estudos.
Referências
BUSSAB, Wilton de Oliveira; MORETTIN, Pedro Alberto. Estatística básica. 9ª ed. São Paulo: Saraiva. 2017.
NARUHODO, Cientística & Podcast. Estatística Psicobio I 2025 #03 – Medidas Descritivas II. Disponível em: <https://www.youtube.com/watch?v=xRzNlJGi_0I&list=PLZjaOxYREinvrzOFlRyICSLAOBG2-e0O8&index=18>. Acesso em: 20 mai. 2025.