Medidas de Dispersão
As medidas de dispersão – também conhecidas como medidas de variabilidade – são estatísticas que nos permitem entender o quão espalhados ou concentrados estão os dados em torno de uma medida de tendência central, como a média. Estas medidas são interessantes para descrever a distribuição geral dos dados. Para Bussab e Morettin (2017, p. 45, ebook), as medidas mais usuais são:
Amplitude Total
A amplitude total é a medida de dispersão mais simples. Ela é calculada como a diferença entre o maior e o menor valor observado em um conjunto de dados. A definição formal do conceito de amplitude está descrita na Equação 1.
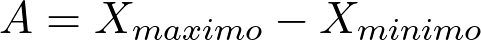
Onde:
Aé a amplitude total.Xmáximoé o maior valor no conjunto de dados.Xmínimoé o menor valor no conjunto de dados.
Considere o seguinte conjunto de dados representando as idades de um grupo de 5 pessoas:
idades: 25, 30, 22, 35, 28
Primeiro, identifique o valor máximo (Xmáximo) do conjunto. Depois, identifique o valor mínimo (Xmínimo). Neste exemplo, o cálculo fica:
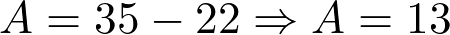
Variância
A variância é uma medida de dispersão que indica o quão longe, em média, os valores estão da média do conjunto de dados. Em outras palavras, podemos dizer que a variância indica o quanto os dados se distanciam da média, em média. O Prof. Altay de Souza (Naruhodo, 2025) descreve que a variância também pode ser entendida como o grau de confiança no palpite do valor esperado (média).
Ela é calculada como a média dos quadrados dos desvios em relação à média aritmética. Porém, é importante destacar que há distinção entre a variância populacional (σ2) e a variância amostral (s2). A variância amostral é frequentemente usada para estimar a variância populacional a partir de uma amostra de dados e utiliza n−1 no denominador para fornecer uma estimativa não viesada. Nas Equações 2 e 3 apresentamos a distinção entre as variâncias.
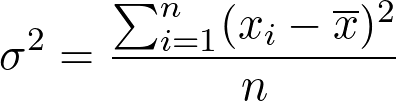
Onde:
σ2é a variância populacional.Xié cada valor individual no conjunto de dados.x̄é a média populacional.né o número total de observações na população.
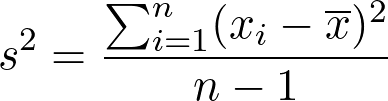
Onde:
s2é a variância amostral.Xi é cada valor individual na amostra.x̄é a média amostral.né o número de observações na amostra.
Para facilitar o entendimento, vamos utilizar a base de idades da exemplificação anterior, assumindo que estes são dados de uma amostra:
idades: 25, 30, 22, 35, 28
Calcule a média amostral (x̄):
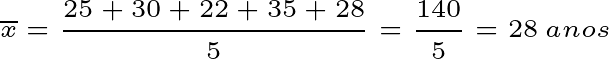
Calcule os desvios de cada valor em relação à média (xi − x̄):
(xi − x̄) | resultado |
| 25 – 28 | – 3 |
| 30 – 28 | 2 |
| 22 – 28 | – 6 |
| 35 – 28 | 7 |
| 28 – 28 | 0 |
Eleve ao quadrado cada desvio ( (xi − ):x̄)2
(xi − x̄)2 | resultado |
| (- 3)2 | 9 |
| (2)2 | 4 |
| (- 6)2 | 36 |
| (7)2 | 49 |
| (0)2 | 0 |
Some os quadrados dos desvios:
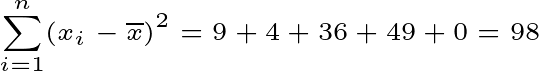
Divida pela soma dos quadrados dos desvios por n − 1 (onde n = 5):
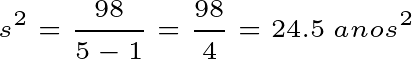
A variância apresenta um problema na unidade de medição. Enquanto a média das idades está em anos, a variância está calculada em anos2. Isso sempre acontecerá, pois os valores dos desvios são elevados ao quadrado. Para resolver essa questão, tiramos a raiz quadrada da variância e obtemos o desvio padrão.
Desvio Padrão
O desvio padrão é simplesmente a raiz quadrada da variância. Ele é uma medida de dispersão expressa na mesma unidade dos dados originais, o que facilita a interpretação. Assim como a variância, existe o desvio padrão populacional (σ) e o amostral (s). Na Equação 4 demonstramos as formulações dos desvios, sendo a equação à esquerda o desvio populacional e à direita o desvio amostral.
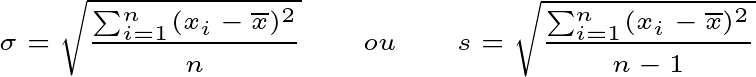
Continuando com o exemplo das idades, onde a variância amostral (s2) foi calculada como 24.5 anos2, calcularemos a raiz quadrada da variância amostral. Isso significa que, em média, as idades do grupo se desviam aproximadamente 4.95 anos da média de 28 anos.
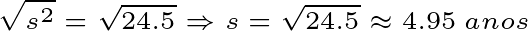
Quanto maior o desvio padrão menor será a confiança no palpite da média, afinal, os dados estão oscilando demais. Isso significa que calcular e apresentar o desvio padrão é tão importante quanto calcular e apresentar a média, conforme o exemplo abaixo:
28 ± 4.95 anos (média e desvio padrão)
Coeficiente de Variação
O Coeficiente de Variação é uma medida de dispersão relativa. Ele expressa o desvio padrão como uma porcentagem da média, sendo útil para comparar a variabilidade de conjuntos de dados com diferentes unidades de medida ou médias muito distintas. De acordo com Rizzo (2025, online), “utiliza-se o coeficiente de variação principalmente em duas situações: para comparar conjuntos de dados com médias muitos desiguais e comparar dados com unidades de medida diferentes.” Em linhas gerais, podemos dizer que quanto maior for o coeficiente de variação, maior será a variabilidade das informações em relação à média, indicando um grupo de dados mais heterogêneo. A Equação 5 formaliza o cálculo do coeficiente.

Onde:
CVé o coeficiente de variação.s(ouσ) é o desvio padrão (amostral ou populacional).x̄é a média (amostral ou populacional), e utiliza-se o valor absoluto da média no denominador para evitar problemas com médias negativas, embora em muitos contextos práticos a média seja positiva.
Usando os dados das idades, onde x̄ = 28 anos e s ≈ 4.95 anos, vamos calcular o coeficiente de variação:
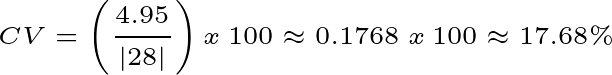
Como o coeficiente nos dá uma medida de dispersão relativa à média, ele não nos diz apenas que os dados estão espalhados (como o desvio padrão), mas o quão espalhados eles estão em comparação com o valor central (a média). No exemplo que temos trabalhado, quando calculamos o CV e obtivemos 17.68%, indicando que os dados estão 17.68% espalhados em relação ao valor da própria média.
Exemplos de código em linguagem Python
Vamos agora treinar os conceitos aprendidos usando programação. Utilizaremos a linguagem Python como instrumentos de treino. O Código 1 traz um exemplo para determinar a amplitude total e a variância de um conjunto amostral de dados. No Código 2 descrevemos um algoritmo que apresenta várias medidas descritivas de dois conjuntos de dados (idades e alturas). No exemplo, buscamos avaliar a diferença entre os desvios-padrão e os coeficientes de variação dos conjuntos.
Não faremos comentários sobre cada linha de programação dos algoritmos. Utilize os comentários nos próprios códigos como instrumento para nortear o entendimento da análise. Caso não entenda a aplicação de alguma biblioteca ou função, pesquise sobre os fundamentos da linguagem Python em si.
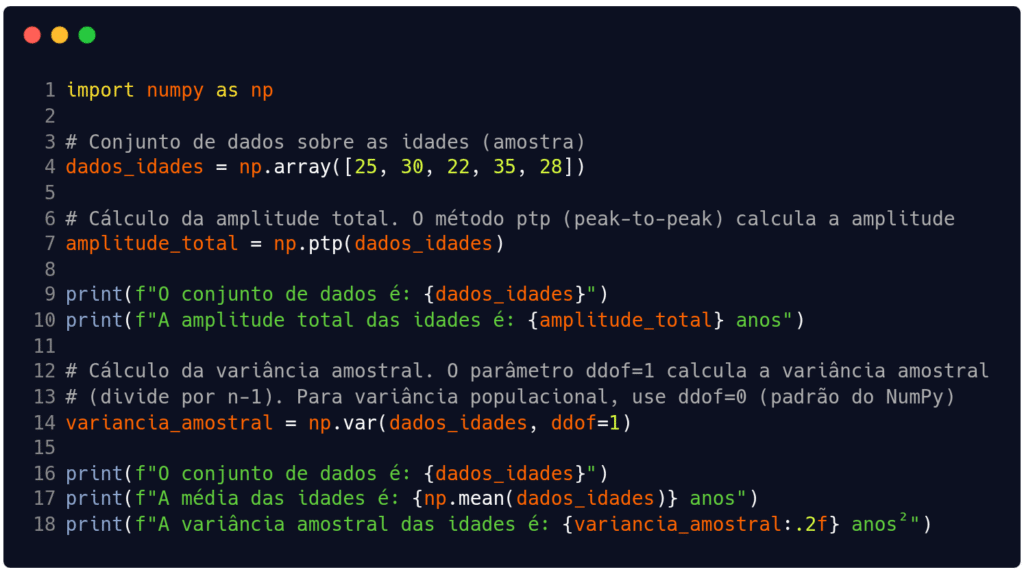
A saída do Código 1 é:
O conjunto de dados é: [25 30 22 35 28]
A amplitude total das idades é: 13 anos
O conjunto de dados é: [25 30 22 35 28]
A média das idades é: 28.0 anos
A variância amostral das idades é: 24.50 anos²
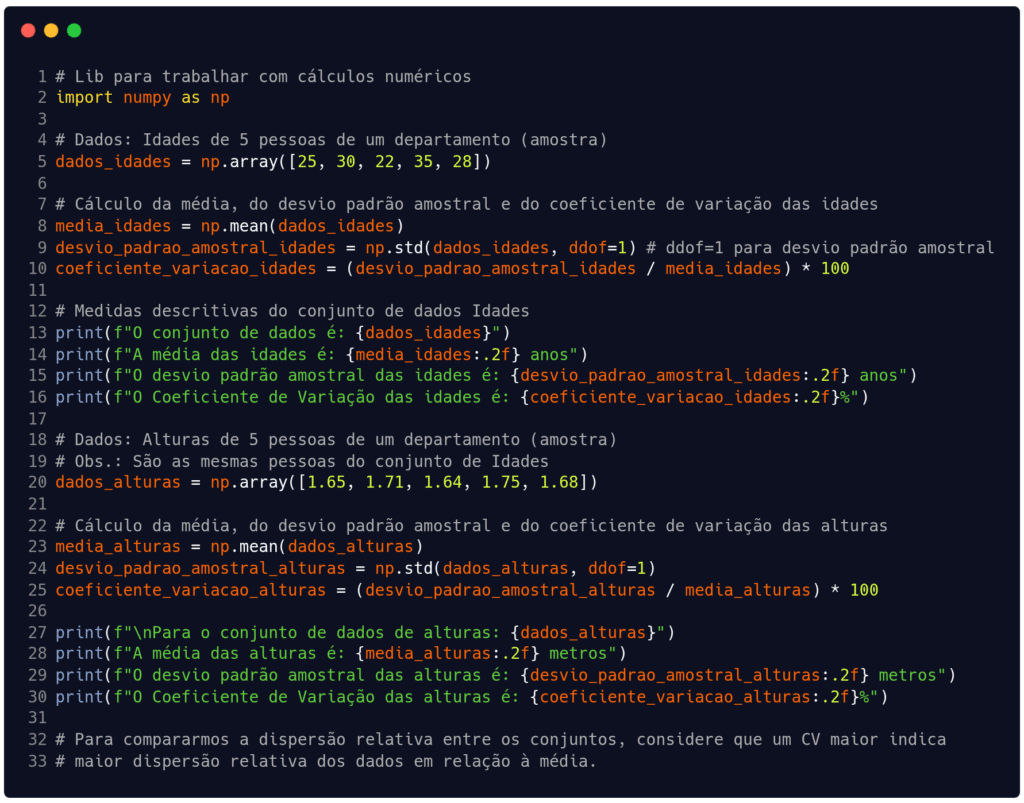
A saída do Código 2 é:
O conjunto de dados é: [25 30 22 35 28]
A média das idades é: 28.00 anos
O desvio padrão amostral das idades é: 4.95 anos
O Coeficiente de Variação das idades é: 17.68%
Para o conjunto de dados de alturas: [1.65 1.71 1.64 1.75 1.68]
A média das alturas é: 1.69 metros
O desvio padrão amostral das alturas é: 0.05 metros
O Coeficiente de Variação das alturas é: 2.67%
Considerações finais
Da mesma forma que no artigo sobre medidas de tendência central, neste também não buscamos encerrar o assunto. Apenas descrevemos a “superfície” do assunto, focando mais na descrição das equações, na elaboração dos conceitos e na exemplificação matemática e computacional de ambos. Recomendamos consultar o Capítulo 3 do livro Estatística Básica de Bussab e Morettin, onde esses conceitos são explorados com mais detalhes e exemplos práticos, para aprofundar seus conhecimentos.
Obrigado pela leitura e bons estudos.
Referências
BUSSAB, Wilton de Oliveira; MORETTIN, Pedro Alberto. Estatística básica. 9ª ed. São Paulo: Saraiva. 2017.
NARUHODO, Cientística & Podcast. Estatística Psicobio I 2025 #03 – Medidas Descritivas II. Disponível em: <https://www.youtube.com/watch?v=xRzNlJGi_0I&list=PLZjaOxYREinvrzOFlRyICSLAOBG2-e0O8&index=18>. Acesso em: 20 mai. 2025.
RIZZO, Maria Luiza Alves. Coeficiente de variação; Brasil Escola. Disponível em: https://brasilescola.uol.com.br/matematica/coeficiente-variacao.htm. Acesso em: 25 mai. 2025.